NASC@ICT团队在第六届全国社会媒体处理大会技术评测中勇夺桂冠
在刚刚落幕的第六届全国社会媒体处理大会(SMP 2017)中,由网络数据科学与技术重点实验室的邢国亮、高浩、曹婍、岳新玉、徐冰冰、岑科廷组成的NASC@ICT团队,在沈华伟指导老师的带领下,同时斩获了CSDN用户画像技术评测的团队第一名以及单项任务第一名两项荣誉。

此次用户画像技术评测隶属于第六届全国社会媒体处理大会,由中国中文信息学会社会媒体处理专委会主办、CSDN协办并赞助,吸引了来自全球200多家单位的757名选手报名参赛,共组建了329支参赛队伍。截止比赛结束,一共有52支队伍完成比赛并提交了完整有效的评测结果。评测聚焦于CSDN技术论坛的用户画像问题,共包含三个不同维度的子任务,分别为:用户内容主题词生成,用户兴趣标注以及用户成长值预测。
用户内容主题词生成
给定若干用户文档(博客或帖子),参赛者需要为每一篇文档生成3个最合适的主题词。要求生成的主题词必须出现在文档中。该任务的难点在于内容主题词是一个相对开放的空间域,候选词集合的范围非常大,与此同时主题词的生成不同于常见的机器学习场景,无法直接应用传统的分类/回归模型。如何在这样开放的候选词中生成文章对应的主题词并充分利用训练数据的标注信息,是该任务的一大关键点。NASC@ICT团队通过构建高覆盖率、低存储代价的特定候选词集合,将传统的无监督的主题词生成模型转换成一个在特定候选词集合上的二分类问题。特定候选词集合的构建过程如下图所示,最终共构建了301,076个候选词,覆盖达到92%的标注主题词。
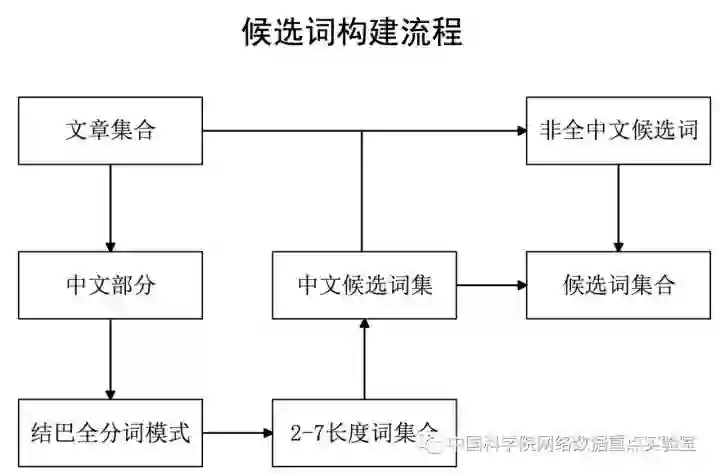
图1:候选词构建流程
构建完候选词集合后,文档的主题词生成问题转换为了在该候选集上的二分类问题(是该文档的主题词或者不是)。NASC@ICT团队构建了包括统计特征、语义特征、外部特征、NLP特征等多种维度的特征共466维,利用XGBoost进行了分类模型的训练。该主题词生成模型在线上测试集达到了65.6%的准确率,以绝对性的优势稳居第一(第二名成绩为60.5%),获得该单项任务冠军。
用户兴趣标注
给定若干用户的文档信息(博客或帖子)和行为数据(浏览、评论、收藏、转发、点赞/踩、关注、私信等),参赛者需要为每一个用户标注3个最合适的兴趣方向。标签空间由CSDN给定,共42维。该任务的主要难点在于训练样本数量非常少,模型很容易过拟合。NASC@ICT团队通过提出了一个两阶段的框架来解决上述挑战(如下图所示)。
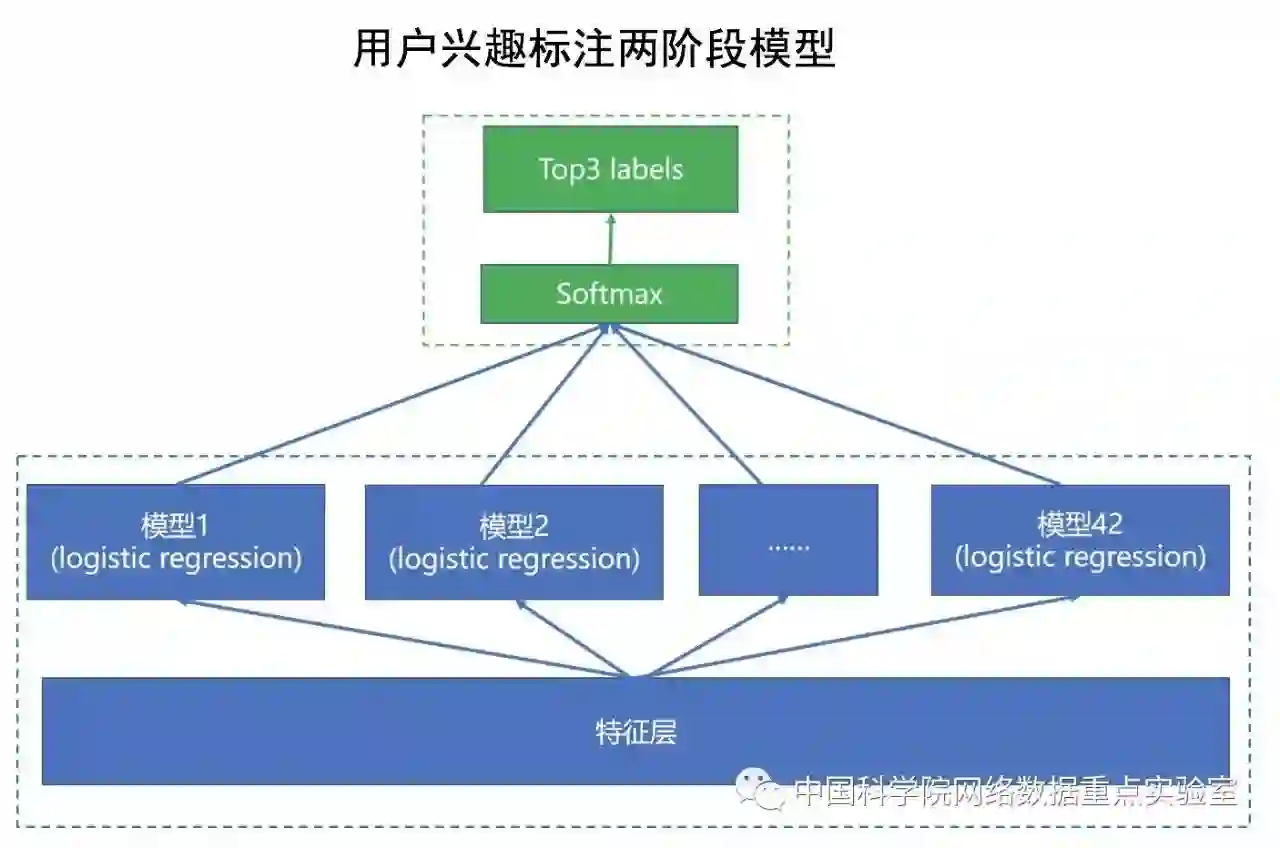
图2:用户兴趣标注两阶段模型
在第一阶段,独立的42个二分类模型并行训练生成,然后将这42个二分类模型的结果作为第二阶段的输入,训练softmax分类器。该两阶段模型在线上测试集达到了44.9%的准确率,有效地解决了训练样本过少,模型容易过拟合的问题。
用户成长值预测
给定若干用户在一段时间内(至少1年)的文档信息(博客或帖子)和行为数据(浏览、评论、收藏、转发、点赞/踩、关注、私信等),参赛者需要预测每一个用户在未来一段时间内(半年至1年)的成长值。如何在CSDN这样一个开放系统下,预测用户未来的行为以及相应的成长值一个非常难的问题。加之带标签数据也较少,用户行为本身就有一定的不可预测性,更使得该任务非常具有挑战性。NASC@ICT团队提出通过回归的半监督模型+Stacking框架来增加带标签数据,解决标注数据过少的问题,增强模型的泛化能力。同时,提取了包括用户行为、用户发布的文档、用户表达等多种维度包含多种信息的特征,来捕获开放系统下的众多影响因素。模型的整体框架如下图所示。最终模型在线上验证集的成绩为0.76,在为期30天的比赛赛程中一直占据排行榜首位。
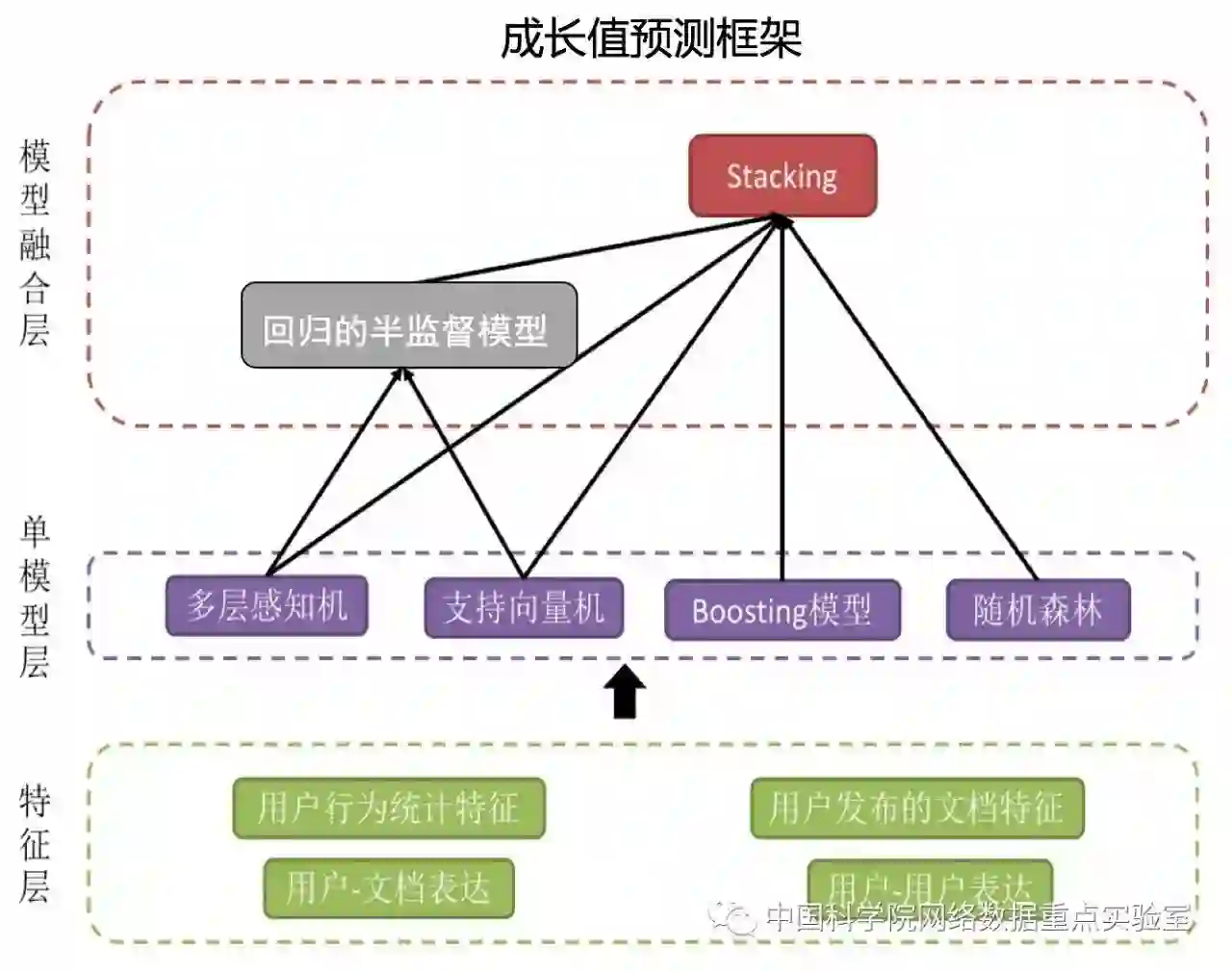
图3:成长值预测框架





