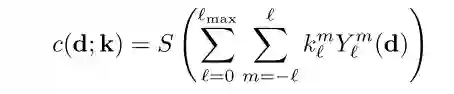NeRF 方法拥有较好的渲染效果,但渲染速度极为缓慢,难以进行实时渲染。来自 UC 伯克利等机构的研究者使用一种名为 PlenOctrees 的数据结构为 NeRF 引入了一种新的数据表示,将渲染速度提升了 3000 多倍。
从稀疏的静态图像合成任意 3D 视角物体和场景新视图是很多 VR 和 AR 应用的基础。近年来神经辐射场(Neural Radiance Fields, NeRF)的神经网络渲染研究通过神经网络编码实现了真实的 3D 视角场景渲染。但是 NeRF 需要极端的采样要求和大量的神经网络运算,导致其渲染速度十分缓慢,严重制约了其在实际场景,尤其是实时交互场景中的应用。例如,使用 NeRF 在高端 GPU 上渲染一张 800X800 像素的图片大概需要 30 秒。近日,来自 UC 伯克利等机构的研究者使用一种名为 PlenOctrees 的数据结构为 NeRF 引入了一种新的数据表示,实现了实时的 NeRF 渲染。其渲染速度比原始的 NeRF 提高了 3000 多倍,并且图像质量可以与 NeRF 媲美。此外,采用 PlenOctrees 结构还能有效减少 NeRF 的训练时间。
![]()
论文地址:
https://arxiv.org/pdf/2103.14024.pdf
项目地址:
https://alexyu.net/plenoctrees/
在 NeRF 方法中,摄像机光线从特定角度穿过场景,生成一组采样的三维点,通过神经网络把这些点的空间位置和视角映射成对应的密度和颜色。然后使用经典的体绘制技术将这些颜色和密度累积到二维图像中。这要求沿射线方向的每个样本都需输入神经网络来获取密度和颜色。这种方式是很低效的,因为大部分样本都是在自由空间中采样的,对整体的颜色并没有贡献。因此本篇论文提出使用稀疏的八叉树(Octree)结构来避免过度采样。另外该方法还预计算了每个体素的值,避免重复输入网络。
![]()
该算法的框架如图 1 所示。该研究提出了名为 PlenOctree 的数据结构,将训练好的 NeRF 预采样转换成 PlenOctree 的数据结构,具体地讲,该方法使用 Octree 结构,把建模所需的密度值和球谐函数(SH)存储到树的叶子节点上。球面谐波代替了某一角度的 RGB 值,可以从任意角度恢复独立的颜色信息。此外,为了更直接地实现 PlenOctree 转换,该研究提出了一种改进的 NeRF 模型(NeRF-SH),产生球面谐波表示,以此避免对网络输入不同视角数据。这些信息可以直接存储在 PlenOctree 的叶子节点上。同时通过微调 Octree 结构就可以进一步提升图像质量。
NeRF-SH 模型如图 1(a)所示,其基本的优化过程和渲染过程与 NeRF 相同,但 NeRF-SH 模型不直接输出 RGB 颜色,而是输出球谐函数 k。颜色 c 由在相应的射线方向 (θ, φ) 上的球谐函数 k 基上加权求和计算得出。转换公式如下:
![]()
其中 d 为视角角度,k 是网络输出的球谐函数 SH。使用 SH 基无需对视图方向进行采样,从而减少了训练时间。在 NeRF-SH 的训练过程中,该研究还引入了稀疏先验约束,以提升 Octree 结构的存储效率。整个提取过程大约需要 15 分钟。
PlenOctree 结构如图 1(b)所示,在 NeRF-SH 模型训练完成后,将其转换成稀疏的 Octree 结构以实现实时渲染。转换的过程分为以下三个步骤:1)在较高的层次上,在网格上评估网络,只保留密度值,2)通过阈值过滤体素。3)对每个剩余体素内的随机点进行采样,并对它们进行平均,以获得 SH 函数,并存储在 Octree 叶子中。在渲染的过程中树的值是完全可微的,直接在原始训练图像上微调就可以进一步提升图像质量。PlenOctree 结构的优化速度约为每秒 300 万射线,相比之下,NeRF 优化速度约为每秒 9000 射线。该方法的优化速度相比 NeRF 具有明显的提升,因此可以提前结束 NeRF-SH 的训练来构建 PlenOctree 结构,而几乎不会降低模型性能。
渲染效果如图 2 所示,相比于 NeRF,该方法渲染的图像在细节上更优,更接近于真实图像,并且渲染速度快了 3000 多倍。
![]()
图 3 是几种方法训练时间的对比结果,可以看出 NeRF 模型和 NeRF-SH 模型所需的训练时间接近。而 PlenOctree 结构转换和微调需要大约 1 小时的训练时间。但是将 NeRF-SH 和 PlenOctree 结合可以让模型只需 4.5 小时,就能达到 NeRF 大约 16 小时的训练质量。
![]()
虽然渲染速度和性能都有所提升,但使用 Octree 结构也会占用更多内存资源。感兴趣的读者可以阅读原文了解更多详细内容。
建新·见智 —— 2021亚马逊云科技 AI 在线大会
4月22日 14:00 - 18:00
为什么有那么多的机器学习负载选择亚马逊云科技?大规模机器学习、企业数字化转型如何实现?
《建新 · 见智——2021 亚马逊云科技 AI 在线大会》由亚马逊云科技全球人工智能技术副总裁及杰出科学家 Alex Smola、亚马逊云科技大中华区产品部总经理顾凡领衔,40多位重磅嘉宾将在主题演讲及6大分会场上为你深度剖析亚马逊云科技创新文化,揭秘 AI/ML 如何帮助企业加速创新。
分会场一:亚马逊机器学习实践揭秘
分会场二:人工智能赋能企业数字化转型
分会场三:大规模机器学习实现之道
分会场四:AI 服务助力互联网快速创新
分会场五:开源开放与前沿趋
分会场六:合作共赢的智能生态
6大分会场,你对哪个主题更感兴趣?
识别二维码或点击阅读原文,免费报名看直播。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com