声音图片 多感知论文
https://arxiv.org/abs/1805.11264
https://www.groundai.com/project/disentangling-by-partitioning-a-representation-learning-framework-for-multimodal-sensory-data/
视觉跟imu ,马路牙子开上去可不行,视觉跟雷达的深度信息。
Disentangling by Partitioning: A Representation Learning Framework for Multimodal Sensory Data
Wei-Ning Hsu, James Glass
(Submitted on 29 May 2018)
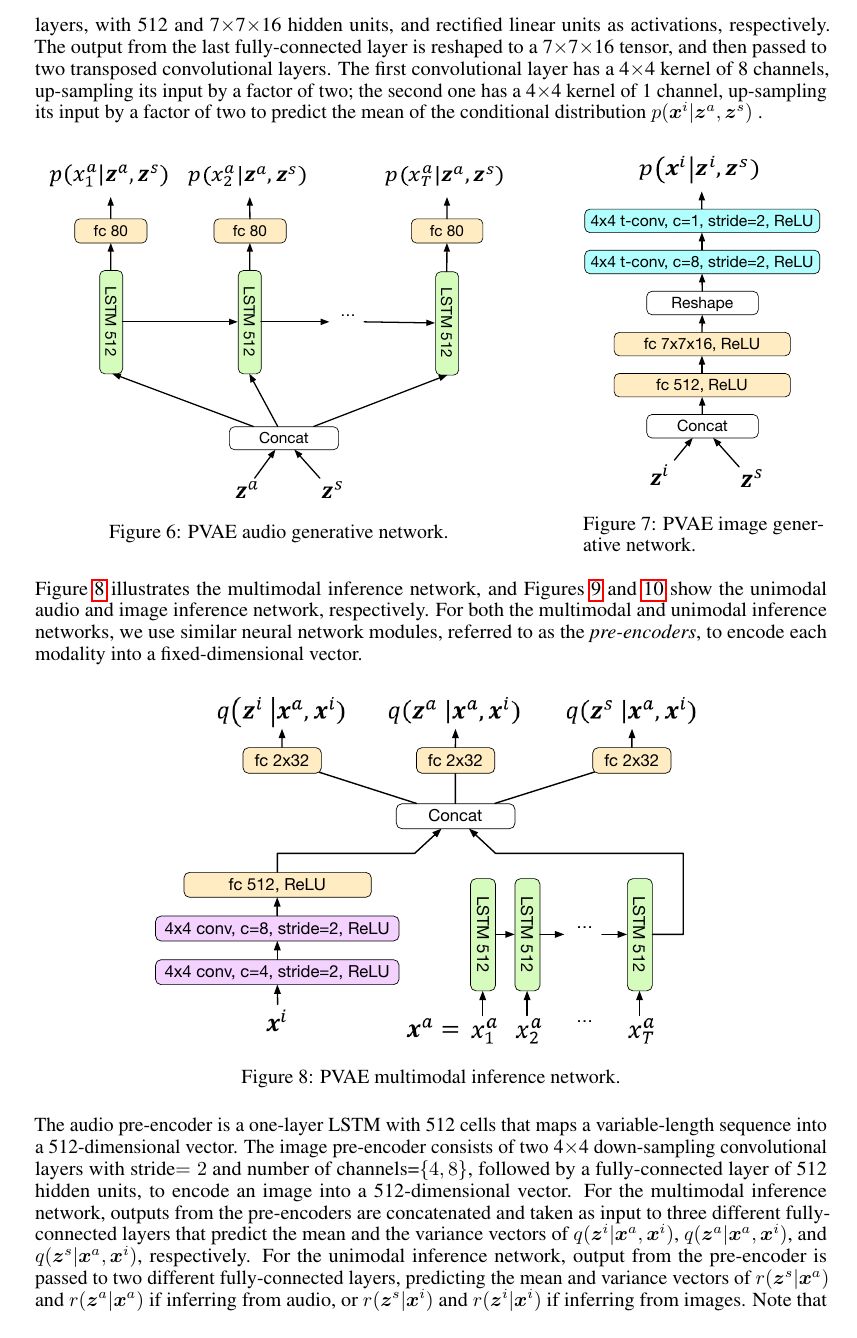
Multimodal sensory data resembles the form of information perceived by humans for learning, and are easy to obtain in large quantities. Compared to unimodal data, synchronization of concepts between modalities in such data provides supervision for disentangling the underlying explanatory factors of each modality. Previous work leveraging multimodal data has mainly focused on retaining only the modality-invariant factors while discarding the rest. In this paper, we present a partitioned variational autoencoder (PVAE) and several training objectives to learn disentangled representations, which encode not only the shared factors, but also modality-dependent ones, into separate latent variables. Specifically, PVAE integrates a variational inference framework and a multimodal generative model that partitions the explanatory factors and conditions only on the relevant subset of them for generation. We evaluate our model on two parallel speech/image datasets, and demonstrate its ability to learn disentangled representations by qualitatively exploring within-modality and cross-modality conditional generation with semantics and styles specified by examples. For quantitative analysis, we evaluate the classification accuracy of automatically discovered semantic units. Our PVAE can achieve over 99% accuracy on both modalities.




Ambient Sound Provides Supervision for Visual Learning https://arxiv.org/pdf/1608.07017.pdf
In this work, we show that a model trained to predict held-out sound from video frames learns a visual representation that conveys semantically meaningful information. We formulate our sound-prediction task as a classification problem, in which we train a convolutional neural network (CNN) to predict a statistical summary of the sound that occurred at the time a video frame was recorded.
https://arxiv.org/abs/1706.05137
One Model To Learn Them All
https://arxiv.org/abs/1706.00932
See, Hear, and Read: Deep Aligned Representations
Firstly, we use an unsu- pervised method that leverages the natural synchronization between modalities to learn an alignment. Secondly, we de- sign an approach to transfer discriminative visual models into other modalities.
We experiment with this representation for several multi-modal tasks, such as cross-modal retrieval and classification. Moreover, although our network is only trained with image+text and image+sound pairs, our rep- resentation can transfer between text and sound as well, a transfer the network never saw during training.



