Ian Goodfellow:作为一名审稿人,我是这样看论文的
编者按:又到了春暖花开的季节,各大会议也逐渐活跃了起来,随之而来的就是海量论文的审阅工作。作为“GAN之父”,Ian Goodfellow结合自己的工作经验为各位审稿人提了几点建议,不仅对专业论文审阅人员有用,准备写论文的同学也可以借鉴一下。文章来自Ian Goodfellow的推特,经论智编译整理。
最近我看到很多类似“资深审稿人只看那些一眼看上去就是高质量的论文”或者“一定要记得bid,不然你只会得到劣质论文”这样的说法。作为一名资深审稿人,我从来不苛求一定要得到好论文。审稿人可以bid,但是你应该明白自己的目标是什么。
我个人有两个目的:
保证文献的高质量;
减少作为一名审稿人需要完成的工作量。
基于这些目的,我主要争取的是那些可能会被拒的论文,而被拒的原因其他审稿人可能发现不了。
有些很忙的资深审稿人可能只会bid那些质量明显很差的论文以减少工作量。另外,审稿人还有些其他的目的,例如比其他人更早地了解到令人兴奋的研究,确保优秀的研究成果不被拒绝,或者审查他们本领域的成果等等。
但是也有些审稿人“不坏好心”,例如如果与某人有不愉快的经历,他就会申请要这篇论文然后将其拒绝。
如何评估一篇论文的进步之处?
到目前为止,已经有许多关于生成对抗网络(GANs)如何工作的理论和实践研究了,同时还有许多用GANs生成新奇有趣的项目的论文。同样还有许多论文,将GANs作为大型系统的一部分,比如将GANs用于半监督学习、差分隐私、数据集增强等等。但是这些都不是这篇文章的目的。
这篇文章是关于评估一些新方法,这些方法能让GANs生成或训练更好地样本。
首先,我会推荐对GANs感兴趣的读者阅读Are GANs Created Equal(arxiv.org/pdf/1711.10337.pdf)这篇论文,它解释了为什么该领域的实证研究很难实现,以及正确的做法。
另外一篇帮助了解背景的论文是A note on the evaluation of generative models(arxiv.org/abs/1511.01844),这解释了为什么用好的样本和不良的可能性能生成模型,以及关于生成模型的指标问题。
GAN相关论文的一个难点是评估其新颖性。有很多关于GAN的改善提议,但是我们很难跟踪这些改进并判断它是否是真的新方法。我们要在谷歌里用4到5种不同的方法搜索,看这个想法是否被人提过。
这里有一个能够很好了解各种GAN变体的资源:
地址:github.com/hindupuravinash/the-gan-zoo
如果我提出了一个不是那么新的方法,这篇论文仍然是值得看的,但是审稿人必须确保这篇论文确切地了解了先前的知识。
随着各种标准层出不穷,Frèchet初始距离(FID)可能是目前为止评估通用GAN模型性能最好的标准。对于ImageNet以外的数据集,也可以用除了Inception之外的模型去定义距离。
一些研究特殊案例的论文可能包括其他标准,但是如果一篇论文连FID都没有的话,我倒是想看看它这样做的原因。
很多论文都鼓励读者通过查看样本形成自己对于这种方法的看法,这通常是一个不好的迹象。据我了解其中一个重要原因是从某一领域生成样本,这是以前的技术无法解决的。
例如,用单个GAN生成ImageNet样本非常困难,许多论文也证实了这么做基本会失败。但是SN-GAN成功地从所有类别中制作出了可识别的样本,所以也证明了SN-GAN是一项重大改进。(不过这种改进可能源自于其中的某些因素,而不是论文所提出的方法,例如新的、更大的架构等)
许多论文展示了来自CIFAR-10或CelebA等数据集的样本,并让审稿人留下了深刻的印象。对于这些论文,我从来不知道我要寻找什么。任务大部分都已经解决了,剩下的没有给我任何信号。
另外,面对只有一点点缺陷的图像,我不知道怎么将它与其他图像进行排序。能不能加一点马赛克或者稍微改动一下……
因此,我通常不会用CelebA或CIFAR-10的样本检查试验方法是否有效。审稿人应该对应用自己标准的人保持警惕,一个微小的调整就有可能让深度学习算法失败。而且作者习惯性地不会仔细检查自己的标准。
通常来说,一篇论文起码要采用一个出现在另一篇论文中的标准,并且另一篇论文的作者在此基础上获得了好的结果。这种评估方法至少是激励相容的。
审稿人应该检查其他论文是否执行了相同任务,并检查它们的分数。我们经常会看到引用某篇论文,然后展示出比原论文中更糟糕的图像或分数。
当然其他领域也会在标准上遇到麻烦,具体可参阅这篇论文:e.humanities.uva.nl/ireval/papers/paper_2.pdf
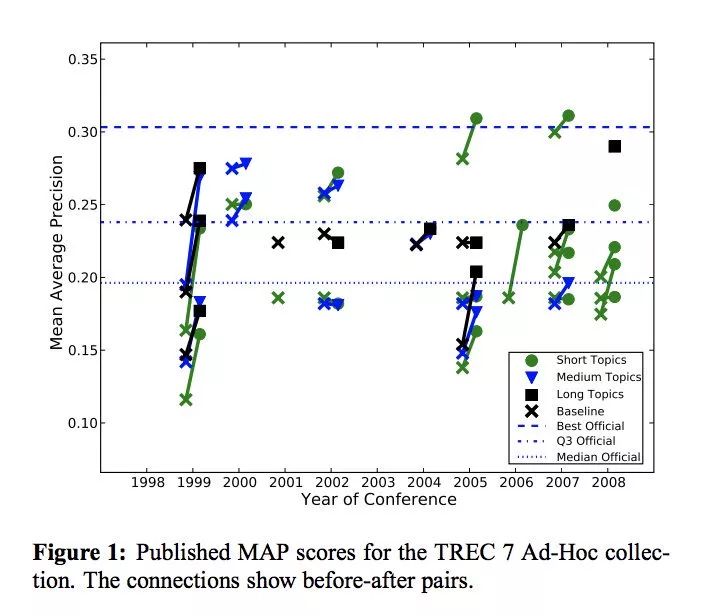
有时,如果一篇论文研究一项新任务或者此前的研究很少评估过的方面,作者有必要实施他们自己定的标准。在这种情况下,至少论文的一半篇幅都要用来证明该标准是正确的。
另外,解释超参数的来源也非常重要。通常新方法看起来还有待改进的原因就是作者花了太多时间解释在新方法中如何优化超参数。
判断一篇GAN论文好的标准是什么?
许多深度学习算法,特别是GANs和强化学习,每次运行时都会得到非常不同的结果。论文应该公布同样的超参数下,至少三次运行结果,以便了解算法的随机性。
许多看起来似乎有进步的论文只是展示了新方法较好的运行结果,以及旧方法糟糕的结果。
即使没有明显的证据证明精心挑选实验结果,论文往往也会展示新方法生成的单一学习曲线和基准的单一曲线,两条曲线非常接近,以至于让我认为同种方法运行两次得到的结果会大不相同。
在解释如何优化超参数时,重要的是搞清楚它们是来优化多次运行的最大值还是最小值或是平均值。
还有一点需要记住的是,有人会把好方法写成一篇烂论文。有时我们会看到一篇论文,介绍的方法的确很好,但里面出现了很多没有科学支持的论断。审稿人应该对此有所判断。
如果你是某会议的领域主席,我强烈建议让目标审稿人与论文领域相匹配,没有人是全能的GAN专家。例如,如果你收到一篇带有编码器的GANs论文,可以试着请一名ALI、BiGAN、alpha-GAN或AVB领域的作者来审稿。
如果你审阅的是关于mode collapse的论文,并且作者认为mode collapse意味着记住训练样本的一个子集,请谨慎,因为这种情况通常比较麻烦。
例如,mode collapse通常会扰乱与数据不一致的garbage points,这些点往往会在训练中移动。Mode collapse也可以是图案或背景中非常细微的重复,但人眼看不出差别。
最后,论文的副标题不要太多……





