“巨人的肩膀” 海量CTR模型的高效高性能实现 FuxiCTR
导语
CTR预估模型是现代大规模工业推荐系统的核心,往往扮演着“精排”的角色。当下主流的CTR预估模型采用双分支的并行结构,一个分支以深度模型DNN为主,另外一个分支以特征交叉网络为主。特别是自Wide&Deep之后的工作,包括DeepFM、xDeepFM、DCN等撑起了工业推荐系统的一片天。宏观来看,CTR预估模型的整体结构往往并不复杂,其动机也通常易于理解。但是,在实际的落地效果中,代码实现上的细小差异可能对最终的结果会有显著的影响。所以,戏称调模型、调参数为“炼丹”也不足为奇。不过,站在巨人的肩膀上去学习甚至改进CTR模型倒是入门推荐系统的捷径。即使是对于有多年的炼丹经验的算法工程师而言,停下来回顾一下过往的经典模型,或许也能从中得到启发。
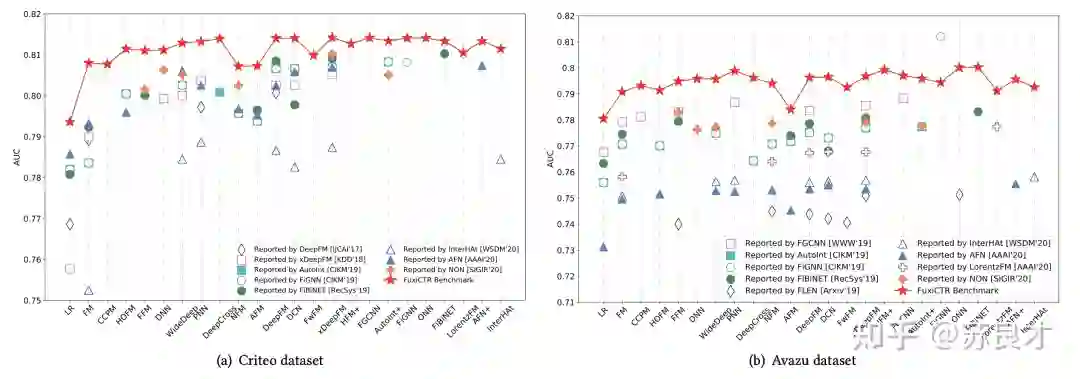
我们身处在一个很好的时代,能够遇到一些很优秀的推荐系统开源代码库。其中,FuxiCTR不仅指出了CTR预估模型发展的一些问题,包括基线效果不一致、数据划分不统一、调参不细致等,而且进行了真正的大量实验(超过12,000 GPU时)给出了近年来主流CTR模型的复现结果。当然,令人眼前一亮的是,复现的结果甚至相比于论文结果有着明显的提升。如图1所示,FuxiCTR汇报的结果相比于论文汇报结果能够有千分点甚至百分点的提升。顺便一提,FuxiCTR的论文今年也被CIKM 2021接收。从这个角度看,FuxiCTR就是本文要寻找的“巨人的肩膀”。
因此,本文就基于FuxiCTR复现xDeepFM模型,试图实现高性能的CTR模型。当然,FuxiCTR不止局限于xDeepFM,也不止拘泥于深度交叉网络模型,只是本文选择xDeepFM模型作为研究对象,希望能够给读者带来一些帮助和提示。
FuxiCTR
介绍
FuxiCTR不仅是一个开源代码工具库,而且提供了主流CTR模型的复现结果。目前,FuxiCTR的代码已经开源:
# Huawei-Noah [stable version]
https://github.com/huawei-noah/benchmark/tree/main/FuxiCTR
# xue-pai [dev version]
https://github.com/xue-pai/FuxiCTR
Huawei-Noah的开源版本是官方正式开源版本,但是由于xue-pai仓库的版本上dev版本,更新较快,本文采用xue-pai开源的FuxiCTR。根据Github上的介绍,FuxiCTR是"configurable, tunable, and reproducible" ,因此希望本文能够充分挖掘和展现FuxiCTR的特性。
FuxiCTR原论文(FuxiCTR: An Open Benchmark for Click-Through Rate Prediction)已被CIKM 2021接收,更详细的介绍见https://dl.acm.org/doi/10.1145/3459637.3482486。
环境安装
如果服务器环境里已经配置好了可用的torch环境,那么一般来说只需要特别安装pyyaml、h5py和tqdm即可。
# pip
pip install pyyaml,tqdm,h5py
# conda
conda install pyyaml,tqdm,h5py
当然,如果要单独搭建一个环境,那么强烈推荐使用Anaconda环境。
-
Linux下Anaconda环境的安装,推荐使用清华镜像(https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/)选择适合的脚本下载并安装。特别地,本文推荐使用Anaconda3-5.2.0-Linux-x86_64.sh,https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.2.0-Linux-x86_64.sh。
-
Pytorch的安装详见官网,https://pytorch.org/get-started/locally/。如果使用conda进行安装,速度太慢的话也可以切换成清华源。这里需要注意一点,FuxiCTR目前只在Pytorch 1.0和1.1版本上进行了测试,为了避免兼容性问题,目前也推荐使用Pytorch 1.0或1.1版本。
-
其余的环境依赖也可利用参考下面的脚本进行安装
# pip
pip install numpy,pandas,pyyaml,tqdm,h5py
# conda
conda install numpy,pandas,pyyaml,tqdm,h5py
安装FuxiCTR
FuxiCTR可以使用pip安装或者是源码安装。为了便于后续查看、修改源码,我们采用源码安装。
git clone https://github.com/xue-pai/FuxiCTR.git
下载后,目录结构如下
├── benchmarks
├── config
├── data
├── demo
├── docs
├── fuxictr # 我们真正需要的源码库
├── LICENSE
├── README.md
├── requirements.txt
├── setup.py
├── tests
└── UPDATES.md
我们将fuxictr复制到我们的代码根目录,其余的文件我们作为探索的参考。
基于FuxiCTR复现高性能xDeepFM
数据集
既然要体现“高性能”,采用较大的数据集那自然是必不可少的。本文选用的是4500W条数据的Criteo数据集,按照8:1:1的划分好训练、验证、测试集。建立data文件夹,并在data下建立criteo_x4, 将train.csv、valid.csv、test.csv放在criteo_x4下。目录结构如下
├── fuxictr
├── data
│ ├── criteo_x4
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── valid.csv
快速上手

整体看FuxiCTR的工作流程和一般的框架其实并没有特别大的区别。因此,接下来给出可用的代码,再补充细节。
目录架构
├── config
│ └── xdeepfm_criteo_x4
│ ├── dataset_config.yaml
│ ├── model_config.yaml
├── data
│ ├── criteo_x4
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── valid.csv
├── fuxictr
└── xdeepfm_criteo.py
配置文件
在config下建立xdeepfm_criteo_x4文件夹,分别填写数据集配置文件和模型配置文件。数据集配置文件: config/xdeepfm_criteo_x4/dataset_config.yaml
criteo_x4:
data_root: ./data/criteo_x4/
data_format: csv
train_data: ./data/criteo_x4/train.csv
valid_data: ./data/criteo_x4/valid.csv
test_data: ./data/criteo_x4/test.csv
min_categr_count: 2
feature_cols:
- {name: [I1,I2,I3,I4,I5,I6,I7,I8,I9,I10,I11,I12,I13],
active: True, dtype: float, type: categorical, preprocess: convert_to_bucket, na_value: 0}
- {name: [C1,C2,C3,C4,C5,C6,C7,C8,C9,C10,C11,C12,C13,C14,C15,C16,C17,C18,C19,C20,C21,C22,C23,C24,C25,C26],
active: True, dtype: str, type: categorical, na_value: ""}
label_col: {name: Label, dtype: float}
模型配置文件: config/xdeepfm_criteo_x4/dataset_config.yaml
Base:
model_root: './checkpoints/'
workers: 8
verbose: 1
patience: 2
pickle_feature_encoder: True
use_hdf5: True
save_best_only: True
every_x_epochs: 1
debug: False
version: 'pytorch'
gpu: 3
xDeepFM_criteo_x4:
model: xDeepFM
dataset_id: criteo_x4
loss: 'binary_crossentropy'
metrics: ['logloss', 'AUC']
task: binary_classification
optimizer: adam
learning_rate: 1.0e-3
embedding_regularizer: 0
net_regularizer: 0
batch_size: 1000
embedding_dim: 40
dnn_hidden_units: [500, 500, 500]
cin_layer_units: [32, 32, 32]
hidden_activations: relu
embedding_dropout: 0
net_dropout: 0
batch_norm: False
epochs: 100
shuffle: True
seed: 2019
monitor: {'AUC': 1, 'logloss': -1}
monitor_mode: 'max'
这里我们需要说明的一点是,FuxiCTR支持读取model_config文件夹下的所有yaml,包括base.yaml、xDeepFM.yaml,然后再合并所需要的字段。本文采用的方法就是直接给定配置文件的路径,因此我们将base.yaml和xDeep.yaml的内容放在一个配置文件的内容中,这也是FuxiCTR支持的方式。
上述的配置文件参考https://github.com/xue-pai/FuxiCTR/blob/main/config/model_config/base.yaml和https://github.com/xue-pai/FuxiCTR/blob/main/config/model_config/xDeepFM.yaml。如果是选择其他模型,那就合并base.yaml和提供的其他参考配置文件。
训练文件
我们在根目录下建立训练文件xdeepfm_criteo.py,参考的是FuxiCTR的Readme.md。
import sys
import os
from fuxictr.datasets import data_generator
from fuxictr.datasets.criteo import FeatureEncoder
from datetime import datetime
from fuxictr.utils import set_logger, print_to_json, load_config
import logging
from fuxictr.pytorch.models import xDeepFM
from fuxictr.pytorch.utils import seed_everything
if __name__ == '__main__':
# 加载参数
params = load_config('config/xdeepfm_criteo_x4','xDeepFM_criteo_x4')
# 获取特征列
feature_cols = params['feature_cols']
label_col = params['label_col']
set_logger(params)
logging.info(print_to_json(params))
seed_everything(seed=params['seed'])
# 特征编码
feature_encoder = FeatureEncoder(feature_cols,
label_col,
dataset_id=params['dataset_id'],
data_root=params["data_root"],
version=params['version'])
feature_encoder.fit(train_data=params['train_data'],
min_categr_count=params['min_categr_count'])
# 构建训练、验证、测试集的数据生成器
train_gen, valid_gen, test_gen = data_generator(feature_encoder,
train_data=params['train_data'],
valid_data=params['valid_data'],
test_data=params['test_data'],
batch_size=params['batch_size'],
shuffle=params['shuffle'],
use_hdf5=params['use_hdf5'])
# 创建模型
model = xDeepFM(feature_encoder.feature_map, **params)
# 模型训练
model.fit_generator(train_gen, validation_data=valid_gen, epochs=params['epochs'],
verbose=params['verbose'])
# 加载模型
model.load_weights(model.checkpoint)
# 在验证集上测试
logging.info('***** validation results *****')
model.evaluate_generator(valid_gen)
# 在测试集上测试
logging.info('***** test results *****')
model.evaluate_generator(test_gen)
其实这个文件也就很好地体现了FuxiCTR的工作流。
运行及其结果
终于到了令人激动的运行时刻。我们切换到正确配置的环境下,运行
# 运行命令
python xdeepfm_criteo.py
# 本文执行的命令
nohup python xdeepfm_criteo.py > train_xdeepfm_criteo.log &
最终我们得到结果如下
2021-11-25 10:57:37,205 P2176383 INFO {
"batch_norm": "False",
"batch_size": "1000",
"cin_layer_units": "[32, 32, 32]",
"data_format": "csv",
"data_root": "./data/",
"dataset_id": "criteo_x4",
"debug": "False",
"dnn_hidden_units": "[500, 500, 500]",
"embedding_dim": "40",
"embedding_dropout": "0",
"embedding_regularizer": "0",
"epochs": "100",
"every_x_epochs": "1",
"feature_cols": "[{'name': ['I1', 'I2', 'I3', 'I4', 'I5', 'I6', 'I7', 'I8', 'I9', 'I10', 'I11', 'I12', 'I13'], 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}, {'name': ['C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9', 'C10', 'C11', 'C12', 'C13', 'C14', 'C15', 'C16', 'C17', 'C18', 'C19', 'C20', 'C21', 'C22', 'C23', 'C24', 'C25', 'C26'], 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}]",
"gpu": "3",
"hidden_activations": "relu",
"label_col": "{'name': 'Label', 'dtype': 'float'}",
"learning_rate": "0.001",
"loss": "binary_crossentropy",
"metrics": "['logloss', 'AUC']",
"min_categr_count": "2",
"model": "xDeepFM",
"model_id": "xDeepFM_criteo_x4",
"model_root": "./checkpoints/",
"monitor": "{'AUC': 1, 'logloss': -1}",
"monitor_mode": "max",
"net_dropout": "0",
"net_regularizer": "0",
"optimizer": "adam",
"patience": "2",
"pickle_feature_encoder": "True",
"save_best_only": "True",
"seed": "2019",
"shuffle": "True",
"task": "binary_classification",
"test_data": "./data/criteo_x4/test.csv",
"train_data": "./data/criteo_x4/train.csv",
"use_hdf5": "True",
"valid_data": "./data/criteo_x4/valid.csv",
"verbose": "1",
"version": "pytorch",
"workers": "8"
}
2021-11-25 10:57:37,206 P2176383 INFO Set up feature encoder...
2021-11-25 10:57:37,206 P2176383 INFO Reading file: ./data/criteo_x4/train.csv
2021-11-25 11:01:34,809 P2176383 INFO Preprocess feature columns...
2021-11-25 11:21:06,292 P2176383 INFO Fit feature encoder...
2021-11-25 11:21:06,308 P2176383 INFO Processing column: {'name': 'I1', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:21:16,542 P2176383 INFO Processing column: {'name': 'I2', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:21:29,117 P2176383 INFO Processing column: {'name': 'I3', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:21:41,664 P2176383 INFO Processing column: {'name': 'I4', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:21:53,779 P2176383 INFO Processing column: {'name': 'I5', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:22:07,014 P2176383 INFO Processing column: {'name': 'I6', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:22:19,484 P2176383 INFO Processing column: {'name': 'I7', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:22:31,678 P2176383 INFO Processing column: {'name': 'I8', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:22:43,962 P2176383 INFO Processing column: {'name': 'I9', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:22:57,546 P2176383 INFO Processing column: {'name': 'I10', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:23:07,657 P2176383 INFO Processing column: {'name': 'I11', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:23:19,668 P2176383 INFO Processing column: {'name': 'I12', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:23:28,232 P2176383 INFO Processing column: {'name': 'I13', 'active': True, 'dtype': 'float', 'type': 'categorical', 'preprocess': 'convert_to_bucket', 'na_value': 0}
2021-11-25 11:23:40,264 P2176383 INFO Processing column: {'name': 'C1', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:23:46,144 P2176383 INFO Processing column: {'name': 'C2', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:23:52,315 P2176383 INFO Processing column: {'name': 'C3', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:24:08,290 P2176383 INFO Processing column: {'name': 'C4', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:24:19,137 P2176383 INFO Processing column: {'name': 'C5', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:24:24,848 P2176383 INFO Processing column: {'name': 'C6', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:24:30,073 P2176383 INFO Processing column: {'name': 'C7', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:24:37,312 P2176383 INFO Processing column: {'name': 'C8', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:24:42,694 P2176383 INFO Processing column: {'name': 'C9', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:24:47,982 P2176383 INFO Processing column: {'name': 'C10', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:24:57,009 P2176383 INFO Processing column: {'name': 'C11', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:25:03,783 P2176383 INFO Processing column: {'name': 'C12', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:25:18,792 P2176383 INFO Processing column: {'name': 'C13', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:25:25,291 P2176383 INFO Processing column: {'name': 'C14', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:25:30,836 P2176383 INFO Processing column: {'name': 'C15', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:25:37,443 P2176383 INFO Processing column: {'name': 'C16', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:25:51,408 P2176383 INFO Processing column: {'name': 'C17', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:25:57,257 P2176383 INFO Processing column: {'name': 'C18', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:26:03,305 P2176383 INFO Processing column: {'name': 'C19', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:26:07,949 P2176383 INFO Processing column: {'name': 'C20', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:26:12,389 P2176383 INFO Processing column: {'name': 'C21', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:26:27,117 P2176383 INFO Processing column: {'name': 'C22', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:26:30,500 P2176383 INFO Processing column: {'name': 'C23', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:26:35,900 P2176383 INFO Processing column: {'name': 'C24', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:26:43,601 P2176383 INFO Processing column: {'name': 'C25', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:26:48,382 P2176383 INFO Processing column: {'name': 'C26', 'active': True, 'dtype': 'str', 'type': 'categorical', 'na_value': ''}
2021-11-25 11:26:54,715 P2176383 INFO Set feature index...
2021-11-25 11:26:54,715 P2176383 INFO Pickle feature_encode: ./data/criteo_x4/feature_encoder.pkl
2021-11-25 11:26:58,843 P2176383 INFO Save feature_map to json: ./data/criteo_x4/feature_map.json
2021-11-25 11:26:58,872 P2176383 INFO Set feature encoder done.
2021-11-25 11:27:12,368 P2176383 INFO Loading data...
2021-11-25 11:27:12,405 P2176383 INFO Loading data from h5: ./data/criteo_x4/train.h5
2021-11-25 11:28:10,408 P2176383 INFO Loading data from h5: ./data/criteo_x4/valid.h5
2021-11-25 11:28:24,382 P2176383 INFO Train samples: total/36672493, pos/9396350, neg/27276143, ratio/25.62%
2021-11-25 11:28:24,530 P2176383 INFO Validation samples: total/4584062, pos/1174544, neg/3409518, ratio/25.62%
2021-11-25 11:28:24,530 P2176383 INFO Loading data from h5: ./data/criteo_x4/test.h5
2021-11-25 11:28:32,099 P2176383 INFO Test samples: total/4584062, pos/1174544, neg/3409518, ratio/25.62%
2021-11-25 11:28:32,099 P2176383 INFO Loading data done.
2021-11-25 11:28:48,907 P2176383 INFO Start training: 36673 batches/epoch
2021-11-25 11:28:48,908 P2176383 INFO ************ Epoch=1 start ************
100%|█████████▉| 36671/36673 [46:29<00:00, 4.78it/s]2021-11-25 12:16:38,448 P2176383 INFO [Metrics] logloss: 0.444146 - AUC: 0.807888
2021-11-25 12:16:38,467 P2176383 INFO Save best model: monitor(max): 0.363741
2021-11-25 12:16:44,215 P2176383 INFO --- 36673/36673 batches finished ---
100%|██████████| 36673/36673 [47:55<00:00, 12.75it/s]
2021-11-25 12:16:44,754 P2176383 INFO Train loss: 0.447797
2021-11-25 12:16:44,755 P2176383 INFO ************ Epoch=1 end ************
100%|█████████▉| 36671/36673 [46:25<00:00, 6.31it/s]2021-11-25 13:03:45,687 P2176383 INFO [Metrics] logloss: 0.458652 - AUC: 0.797808
2021-11-25 13:03:45,688 P2176383 INFO Monitor(max) STOP: 0.339156 !
2021-11-25 13:03:45,688 P2176383 INFO Reduce learning rate on plateau: 0.000100
2021-11-25 13:03:45,688 P2176383 INFO --- 36673/36673 batches finished ---
100%|██████████| 36673/36673 [47:01<00:00, 13.00it/s]
2021-11-25 13:03:46,285 P2176383 INFO Train loss: 0.416490
2021-11-25 13:03:46,285 P2176383 INFO ************ Epoch=2 end ************
100%|█████████▉| 36672/36673 [46:34<00:00, 6.19it/s]2021-11-25 13:50:55,974 P2176383 INFO [Metrics] logloss: 0.504352 - AUC: 0.777503
2021-11-25 13:50:55,974 P2176383 INFO Monitor(max) STOP: 0.273150 !
2021-11-25 13:50:55,974 P2176383 INFO Reduce learning rate on plateau: 0.000010
2021-11-25 13:50:55,974 P2176383 INFO Early stopping at epoch=3
2021-11-25 13:50:55,974 P2176383 INFO --- 36673/36673 batches finished ---
100%|█████████▉| 36672/36673 [47:10<00:00, 12.96it/s]
2021-11-25 13:50:56,503 P2176383 INFO Train loss: 0.345457
2021-11-25 13:50:56,503 P2176383 INFO Training finished.
2021-11-25 13:50:56,504 P2176383 INFO Load best model: /data/slc/homework/data_analysis/rs/code_4/checkpoints/criteo_x4/xDeepFM_criteo_x4_model.ckpt
2021-11-25 13:50:57,507 P2176383 INFO ***** validation results *****
2021-11-25 13:51:49,503 P2176383 INFO [Metrics] logloss: 0.444146 - AUC: 0.807888
2021-11-25 13:51:49,503 P2176383 INFO ***** test results *****
2021-11-25 13:52:42,773 P2176383 INFO [Metrics] logloss: 0.443692 - AUC: 0.808363
从上述的结果来看,在测试集上的结果:logloss: 0.443692,AUC: 0.808363。xDeepFM的原论文汇报的结果:AUC: 0.8052, logloss: 0.4418。从AUC来看,相比原论文提升了3个千分点。这至少说明FuxiCTR的实现是有效的。但是,这个结果与FuxiCTR汇报的结果(AUC: 0.813)仍有差距。不过,这是尚未调参的结果。而且由于机器的限制,本文将batchsize大小调小到1000,FuxiCTR推荐的batchsize是10000,这一点可能对结果还是有比较显著的影响。如果想要看其他参数的配置结果,可以先行参考基于FuxiCTR的Bars-CTR-Prediction(https://openbenchmark.github.io/ctr-prediction)。
后续
在后续的部分,本文将会对xDeepFM模型进行解读,并使用FuxiCTR提供的工具进行调参,实现更高性能的xDeepFM。
可能出现的报错和解决方案
如果读者在复现的过程中遇到问题,欢迎留言探讨或者直接向FuxiCTR仓库提issue。
Yaml加载报错
报错可能原因: yaml版本较低,推荐使用pyyaml>=5.1的版本
解决方案:
pip install pyyaml>=5.1
后记: 突然发现很久没有写文章,遣词造句都显得很生疏。本意想记录探索FuxiCTR的全过程,但兼顾着读者易读易懂易上手,最终还是选择了像是文档一般的写作方式。回到FuxiCTR工作本身,我自认为这一篇工作还是极具参考价值的,至少未来的工作在CTR预估上进一步探索模型的时候,有一个更具比较意义的基线。
参考文献
[1] Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. XDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD '18). Association for Computing Machinery, New York, NY, USA, 1754–1763. DOI:https://doi.org/10.1145/3219819.3220023
[2] Jieming Zhu, Jinyang Liu, Shuai Yang, Qi Zhang, and Xiuqiang He. 2021. Open Benchmarking for Click-Through Rate Prediction. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management (CIKM '21). Association for Computing Machinery, New York, NY, USA, 2759–2769. DOI:https://doi.org/10.1145/3459637.3482486




