ICCV2019 | 北航、百度与华为联合提出贝叶斯优化的1-Bit CNNs

前言
研究现状
方法
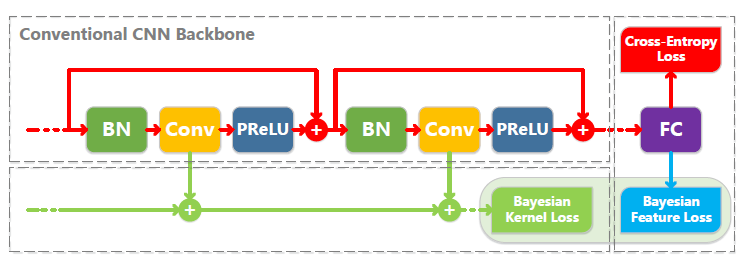

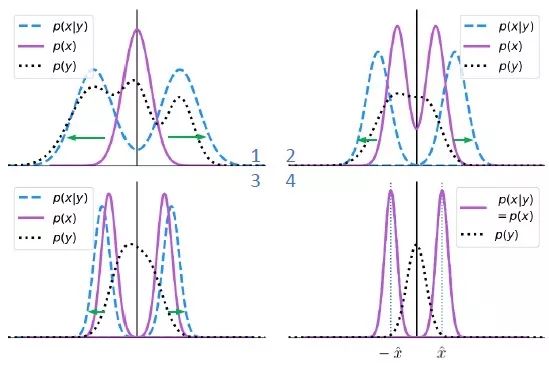






实验
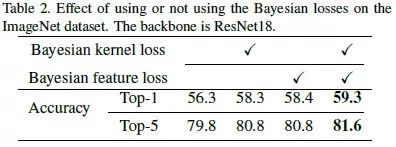
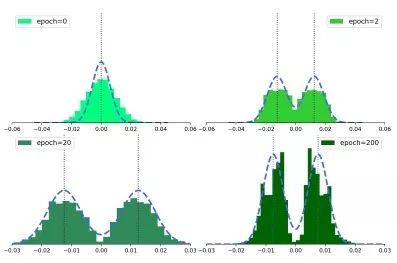
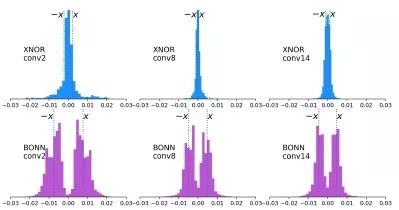
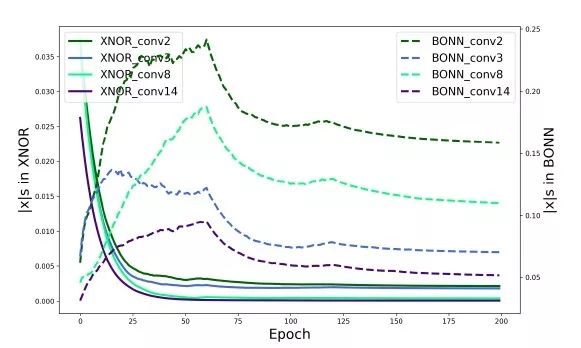
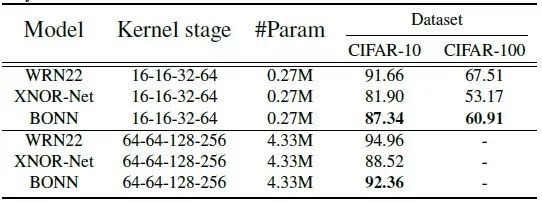
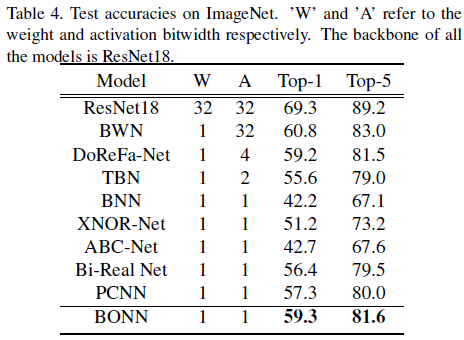
总结
登录查看更多
相关内容
专知会员服务
54+阅读 · 2020年3月5日
Arxiv
4+阅读 · 2018年4月23日
Arxiv
6+阅读 · 2018年4月9日


相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
相关资讯
相关论文
Arxiv
4+阅读 · 2018年4月23日
Arxiv
6+阅读 · 2018年4月9日