周志华作序!高徒魏秀参新书《解析深度学习》试读(评论赠书)

新智元推荐
新智元推荐
【新智元导读】又到一年“双十一”,新智元也借机答谢读者,举办新一轮的赠书活动。这次推荐的是南京大学周志华教授高徒、旷视南京研究院负责人魏秀参最新出版的《解析深度学习:卷积神经网络原理与视觉实践》。还等什么,赶紧留言吧~
“市面上深度学习书籍已不少,但专门针对卷积神经网络展开,侧重实践又不失论释者尚不多见。本书基本覆盖了卷积神经网络实践所涉之环节,作者交代的若干心得技巧亦可一观,读者在实践中或有见益。”
这是周志华教授对他的学生、南京大学LAMDA研究所博士魏秀参所著新书《解析深度学习:卷积神经网络原理与视觉实践》的高度评价。
魏秀参专注于卷积神经网络及其视觉应用,先后师从周志华教授和吴建鑫教授,在相关领域重要国际期刊和国际会议发表论文十余篇,并两次获得国际计算机视觉相关竞赛冠、亚军,博士未毕业即被旷视科技聘为南京研究院负责人。
机器学习领域专业、实用的好书很多,但多是英文翻译而来,中文书籍委实不多,魏秀参的新书是其中令人眼前一亮的一本。正如作者所说,“这是一本面向中文读者的轻量级、偏实用的深度学习工具书”,向读者剖析了卷积神经网络的基本部件与工作机理,更重要的是系统性地介绍了深度卷积神经网络在实践应用方面的细节配置与工程经验。
【活动规则】即日起到2018年11月15日23点59分,评论留言,主题形式不限,你与深度学习的故事,对新智元的批评建议,对AI产业的洞见,只要让人眼前一亮。评论将在新智元全体编辑讨论后精选放出,获编辑部投票前10名的读者将得到我们的免费赠书一本!
卷积神经网络乃机器学习领域中深度学习技术最著名内容之一。魏秀参博士在LAMDA 求学数年,对卷积神经网络及其视觉应用颇有所长,博士未毕业即被旷视科技聘为南京研究院负责人,毕业之际将心得材料转撰成书请愚致序。师生之谊,盛情难却。
在国内计算机领域,写书乃吃力不讨好之事。且不论写一本耐读、令读者每阅皆有所获之书何等不易,更不消说众口难调出一本令各型读者皆赞之书何等无望,仅认真写书所耗时间精力之巨、提职时不若期刊论文之效、收入不比同等精力兼差打工之得,已令人生畏,何况稍有不慎就有误人子弟之嫌,令一线学者若不狠心苛己,实难着手。
然有志求学本领域之士渐增,母语优良读物之不足实碍科学技术乃至产业发展。毕竟未必众人皆惯阅外文书籍,亦未必尽能体会外文微妙表达变化之蕴义,更不消说母语阅读对新入行者之轻快适意。愚曾自认四十不惑前学力不足立著,但国内科研水准日新月异,青年才俊茁然成长,以旺盛之精力分享所学,诚堪嘉勉。
市面上深度学习书籍已不少,但专门针对卷积神经网络展开,侧重实践又不失论释者尚不多见。本书基本覆盖了卷积神经网络实践所涉之环节,作者交代的若干心得技巧亦可一观,读者在实践中或有见益。望本书之出版能有助于读者更好地了解和掌握卷积神经网络,进一步促进深度学习技术之推广。
周志华
2018 年10 月于南京
作者简介
魏秀参
旷视科技(Face++)南京研究院负责人。南京大学LAMDA研究所博士,主要研究领域为计算机视觉和机器学习。在相关领域重要国际期刊和国际会议发表论文十余篇,并两次获得国际计算机视觉相关竞赛冠、亚军。曾获CVPR 2017最佳审稿人、南京大学博士生校长特别奖学金等荣誉,担任ICCV、CVPR、ECCV、NIPS、IJCAI、AAAI等国际会议PC member。
前言
人工智能,一个听起来熟悉但却始终让人备感陌生的词汇。让人熟悉的是科幻作家艾萨克·阿西莫夫笔下的《机械公敌》和《机器管家》,令人陌生的却是到底如何让现有的机器人咿呀学语、邯郸学步;让人熟悉的是计算机科学与人工智能之父图灵设想的“图灵测试”,令人陌生的却是如何使如此的高级智能在现实生活中不再子虚乌有;让人熟悉的是2016 年初阿尔法狗与李世乭在围棋上的五番对决,令人陌生的却是阿尔法狗究竟是如何打通了“任督二脉”的……不可否认,人工智能就是人类为了满足自身强大好奇心而脑洞大开的产物。现在提及人工智能,就不得不提阿尔法狗,提起阿尔法狗就不得不提到深度学习。那么,深度学习究竟为何物?
本书从实用角度着重解析了深度学习中的一类神经网络模型——卷积神经网络,向读者剖析了卷积神经网络的基本部件与工作机理,更重要的是系统性地介绍了深度卷积神经网络在实践应用方面的细节配置与工程经验。
笔者希望本书“小而精”,避免像某些国外相关教材一样浅尝辄止的“大而空”。
写作本书的主因源自笔者曾于2015 年10 月在个人主页(http://lamda.nju.edu.cn/weixs)上开放的一个深度学习的英文学习资料“深度神经网络之必会技巧”(Must Know Tips/Tricks in Deep Neural Networks)。该资料随后被转帖至新浪微博,受到不少学术界和工业界朋友的好评,至今已有逾36 万的阅读量,后又被国际知名论坛 KDnuggets 和 Data Science Central 特邀转载。在此期间,笔者频繁接收到国内外读过此学习资料的朋友微博私信或邮件来信表示感谢,其中多人提到希望开放一个中文版本以方便国人阅读学习。另一方面,随着深度学习领域发展的日新月异,当时总结整理的学习资料现在看来已略显滞后,不少最新研究成果并未涵盖其中,同时加上国内至今尚没有一本侧重实践的深度学习方面的中文书籍。因此,笔者笔耕不辍,希望将自己些许的所学所知所得所感及所悟汇总于本书中,分享给大家学习和查阅。
这是一本面向中文读者的轻量级、偏实用的深度学习工具书,本书内容侧重深度卷积神经网络的基础知识和实践应用。为了使尽可能多的读者通过本书对卷积神经网络和深度学习有所了解,笔者试图尽可能少地使用晦涩的数学公式,而尽可能多地使用具体的图表形象表达。本书的读者对象为对卷积神经网络和深度学习感兴趣的入门者,以及没有机器学习背景但希望能快速掌握该方面知识并将其应用于实际问题的各行从业者。为方便读者阅读,本书附录给出了一些相关数学基础知识简介。
全书共有14 章,除“绪论”外可分为两个部分:第一部分“基础理论篇”包括第1~4 章,介绍卷积神经网络的基础知识、基本部件、经典结构和模型压缩等基础理论内容;第二部分“实践应用篇”包括第5~14 章,介绍深度卷积神经网络自数据准备开始,到模型参数初始化、不同网络部件的选择、网络配置、网络模型训练、不平衡数据处理,最终到模型集成等实践应用技巧和经验。另外,本书基本在每章结束均有对应小结,读者在阅读完每章内容后不妨掩卷回忆,看是否完全掌握了此章重点。对卷积神经网络和深度学习感兴趣的读者可通读全书,做到“理论结合实践”;对希望迅速应用深度卷积神经网络来解决实际问题的读者,也可直接参考第二部分的有关内容,做到“有的放矢”。
笔者在本书写作过程中得到很多同学和学术界、工业界朋友的支持与帮助,在此谨列出他们的姓名以致谢意(按姓氏拼音序):高斌斌、高如如、罗建豪、屈伟洋、谢晨伟、杨世才、张晨麟等。感谢高斌斌和罗建豪帮助起草本书第3.2.4节和第4章的有关内容。此外,特别感谢南京大学周志华教授、吴建鑫教授和澳大利亚阿德莱德大学沈春华教授等众多师长在笔者求学科研过程中不厌其烦细致入微的指导、教育和关怀。同时,感谢电子工业出版社的刘皎老师为本书出版所做的努力。最后非常感谢笔者的父母,感谢他们的养育和一直以来的理解、体贴与照顾。写就本书,笔者自认才疏学浅,仅略知皮毛,更兼时间和精力有限,书中错谬之处在所难免,若蒙读者不弃,还望不吝赐教,笔者将不胜感激!
魏秀参
模型集成方法
集成学习 (ensemble learning) 是机器学习中的一类学习算法,指训练多个学习器并将它们组合起来使用的方法。这类算法通常在实践中能取得比单个学习器更好的预测结果,颇有“众人拾柴火焰高”之意。特别是历届国际重量级学术竞赛,如 ImageNet、KDD Cup以及许多 Kaggle 竞赛的冠军做法,或简单或复杂但最后一步必然是集成学习。尽管深度网络模型已经拥有强大的预测能力,但集成学习方法的使用仍然能起到“锦上添花”的作用。因此有必要了解并掌握一些深度模型方面的集成方法。一般来讲,深度模型的集成多从“数据层面”和“模型层面”两方面着手。
13.1 数据层面的集成方法
13.1.1 测试阶段数据扩充
本书在第5章“数据扩充”中曾提到了训练阶段的若干数据扩充策略,实际上,这些扩充策略在模型测试阶段同样适用,诸如图像多尺度(multi-scale)、随机抠取(random crop)等。以随机抠取为例,对某张测试图像可得到 n 张随机抠取图像,测试阶段只需用训练好的深度网络模型对 n 张图像分别做预测,之后将预测的各类置信度平均作为该测试图像最终预测结果即可。
13.1.2 “简易集成”法
“简易集成”法 (easy ensemble) [59]是 Liu 等人提出的针对不平衡样本问题的一种集成学习解决方案。具体来说,“简易集成”法对于样本较多的类别采取降采样(undersampling),每次采样数依照样本数目最少的类别而定,这样可使每类取到的样本数保持均等。采样结束后,针对每次采样得到的子数据集训练模型,如此采样、训练反复进行多次。最后对测试数据的预测则从对训练得到的若干个模型的结果取平均或投票获得(有关“多模型集成方法”内容请参见13.2.2节)。总结来说,“简易集成”法在模型集成的同时,还能缓解数据不平衡带来的问题,可谓一举两得。
13.2 模型层面的集成方法
13.2.1 单模型集成
多层特征融合
多层特征融合 (multi-layer ensemble) 是针对单模型的一种模型层面集成方法。由于深度卷积神经网络特征具有层次性的特点(参见3.1.3节内容),不同层特征富含的语义信息可以相互补充,在图像语义分割[31]、细粒度图像检索[84]、基于视频的表象性格分析[97]等任务中常见到多层特征融合策略的使用。一般地,在进行多层特征融合操作时可直接将不同层网络特征级联(concatenate)。而对于特征融合应选取哪些网络层,一个实践经验是,最好使用靠近目标函数的几层卷积特征,因为愈深层特征包含的高层语义性愈强,分辨能力也愈强;相反,网络较浅层的特征较普适,用于特征融合很可能起不到作用,有时甚至会起到相反作用。
网络“快照”集成法
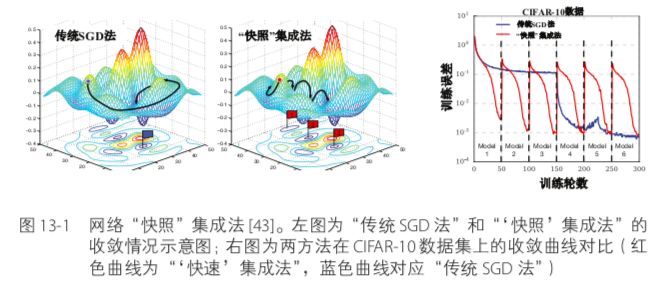
我们知道,深度神经网络模型复杂的解空间中存在非常多的局部最优解,但经典批处理随机梯度下降法(mini-batch SGD)只能让网络模型收敛到其中一个局部最优解。网络“快照”集成法(snapshot ensemble)[43]便利用了网络解空间中的这些局部最优解来对单个网络做模型集成。通过循环调整网络学习率(cyclic learning rate schedule)可使网络依次收敛到不同的局部最优解处,如图13-1左图所示。
具体而言,是将网络学习率 η 设置为随模型迭代轮数 t(iteration,即一次批处理随机梯度下降称为一个迭代轮数)改变的函数,即:
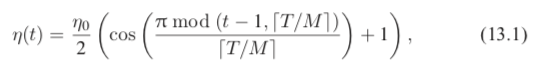
其中,η0 为初始学习率,一般设为 0.1 或 0.2。t 为模型迭代轮数(即 mini- batch 批处理训练次数)。T 为模型总的批处理训练次数。M 为学习率“循环退火”(cyclic annealing)次数,其对应了模型将收敛到的局部最优解个数。式13.1利用余弦函数 cos() 的循环性来循环更新网络学习率,将学习率从 0.1 随 t 的增长逐渐减缓到 0,之后将学习率重新放大从而跳出该局部最优解,自此开始下一循环的训练,此循环结束后可收敛到新的局部最优解处,如此循环往复......直到 M 个循环结束。因式13.1中利用余弦函数循环更新网络参数,所以这一过程被称为“循环余弦退火”过程 (cyclic cosine annealing)[61]。
当经过“循环余弦退火”对学习率调整后,每个循环结束可使模型收敛到一个不同的局部最优解,若将收敛到不同局部最优解的模型保存便可得到 M 个处于不同收敛状态的模型,如图13-1右图中红色曲线所示。对于每个循环结束后保存的模型,我们称之为模型“快照” (snapshot)。测试阶段在做模型集成时,由于深度网络模型在初始训练阶段未必拥有较优性能,因此一般挑选最后 m 个模型“快照”用于集成。关于对这些模型“快照”的集成策略可采用本章后面提到的“直接平均法”。
13.2.2 多模型集成
上一节我们介绍了基于单个网络如何进行模型集成,本节向大家介绍如何产生多个不同网络训练结果和一些多模型的集成方法。
多模型生成策略
同一模型不同初始化。我们知道,由于神经网络训练机制基于随机梯度下降法,故不同的网络模型参数初始化会导致不同的网络训练结果。在实际使用中,特别是针对小样本(limited examples)学习的场景,首先对同一模型进行不同初始化,之后将得到的网络模型进行结果集成会大幅缓解随机性,提升最终任务的预测结果。
同一模型不同训练轮数。若网络超参数设置得当,则深度模型随着网络训练的进行会逐步趋于收敛,但不同训练轮数的结果仍有不同,无法确定到底哪一轮训练得到的模型最适用于测试数据。针对上述问题,一种简单的解决方式是将最后几轮训练模型结果做集成,这样一方面可降低随机误差,另一方面也避免了训练轮数过多带来的过拟合风险。这样的操作被称为“轮数集成”(epoch fusion 或 epoch ensemble)。具体使用实例可参考 ECCV 2016 举办的“基于视频的表象性格分析”竞赛冠军做法[97]。
不同目标函数。目标函数(或称损失函数)是整个网络训练的“指挥棒”,选择不同的目标函数势必使网络学到不同的特征表示。以分类任务为例,可将“交叉熵损失函数”、“合页损失函数”、“大间隔交叉熵损失函数”和“中心损失函数”作为目标函数分别训练模型。在预测阶段,既可以直接对不同模型预测结果做“置信度级别”(score level)的平均或投票,也可以做“特征级别”(feature level)的模型集成:将不同网络得到的深度特征抽出后级联作为最终特征,之后离线训练浅层分类器(如支持向量机)完成预测任务。
不同网络结构。也是一种有效的产生不同网络模型结果的方式。操作时可在如 VGG 网络、深度残差网络等不同网络架构的网络上训练模型,最后对从不同架构网络得到的结果做集成。
多模型集成方法
使用上一节提到的多模型生成策略或网络“快照”集成法均可得到若干网络训练结果,除特征级别直接级联训练离线浅层学习器外,还可以在网络预测结果级别对得到的若干网络结果做集成。下面介绍四种最常用的多模型集成方法。假设共有 N 个模型待集成,对某测试样本 x,其预测结果为 N 个 C 维向量(C 为数据的标记空间大小): s1,s2,...,sN。
直接平均法 (simpleaveraging) 是最简单有效的多模型集成方法,通过直接将不同模型产生的类别置信度进行平均得到最后预测结果:
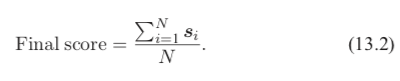
加权平均法 (weighted averaging) 是在直接平均法基础上加入权重来调节不同模型输出的重要程度:
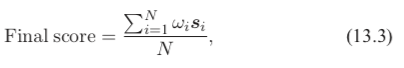
其中,ωi 对应第 i 个模型的权重,且须满足:
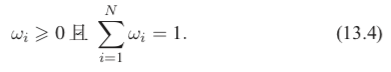
在实际使用时,关于权重 ωi 的取值可根据不同模型在验证集上各自单独的准确率而定,高准确率的模型权重较高,低准确率模型可设置稍小权重。
投票法 (voting) 中最常用的是多数表决法 (majority voting),表决前需先将各自模型返回的预测置信度 si 转化为预测类别,即最高置信度对应的类别标记ci ∈{1,2,...,C}作为该模型的预测结果。在多数表决法中,在得到样本 x 的最终预测时,若某预测类别获得一半以上模型投票,则该样本预测结果为该类别;若对于该样本无任何类别获得一半以上投票,则拒绝做出预测(称为“rejection option”)。
投票法中另一种常用方法是相对多数表决法 (plurality voting),与多数表决法会输出“拒绝预测”不同的是,相对多数表决法一定会返回某个类别作为预测结果,因为相对多数表决是选取投票数最高的类别作为最后预测结果。
堆叠法 (stacking) 又称“二次集成法”,是一种高阶的集成学习算法。在刚才的例子中,样本 x 作为学习算法或网络模型的输入,si 作为第 i 个模型的类别置信度输出,整个学习过程可记作一阶学习过程 (first-level learning)。堆叠法则是以一阶学习过程的输出作为输入开展二阶学习过程 (second-level learning),有时也称作“元学习” (meta learning)。拿刚才的例子来说,对于样本 x,堆叠法的输入是 N 个模型的预测置信度 [s1s2 . . . sN ],这些置信度可以级联作为新的特征表示。之后基于这样的“特征表示”训练学习器将其映射到样本原本的标记空间。注意,此时的学习器可为任何学习算法习得的模型,如支持向量机 (support vector machine)、随机森林 (random forest),当然也可以是神经网络模型。不过在此需要指出的是,堆叠法有较大的过拟合风险。
13.3 小结
深度网络的模型集成往往是提升网络最终预测能力的一剂“强心针”,本章从“数据层面”和“模型层面”两个方面介绍了一些深度网络模型集成的方法。
数据层面常用的方法是数据扩充和“简易集成”法,均操作简单但效果显著。
模型层面的模型集成方法可分为“单模型集成”和“多模型集成”。基于单一模型的集成方法可借助单个模型的多层特征的融合和网络“快照”法进行。关于多模型集成,可通过不同参数初始化、不同训练轮数和不同目标函数的设定产生多个网络模型的训练结果。最后使用平均法、投票法和堆叠法进行结果集成。
需要指出的是,第10章提到的随机失活 (dropout) 实际上也是一种隐式的模型集成方法。有关随机失活的具体内容请参考10.4节。
更多关于集成学习的理论和算法请参考南京大学周志华的著作“Ensemble Methods: Foundations and Algorithms”[99]。






赠书活动时间从即日起到2018年11月15日23点59分,在评论区留言,主题内容不限,根据评论的创意和启发性,新智元编辑部投票前10名的读者将获得免费赠书一本!届时请静候新智元小助手联系,活动最终解释权归新智元所有。
想更快拿到书的小伙伴,可点击“阅读原文”,直达京东优惠链接→
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。




