机器推理系列文章概览:七大NLP任务最新方法与进展

本文来自公众号 微软研究院AI头条,AI科技评论 获授权转载,如需转载请联系原公众号。
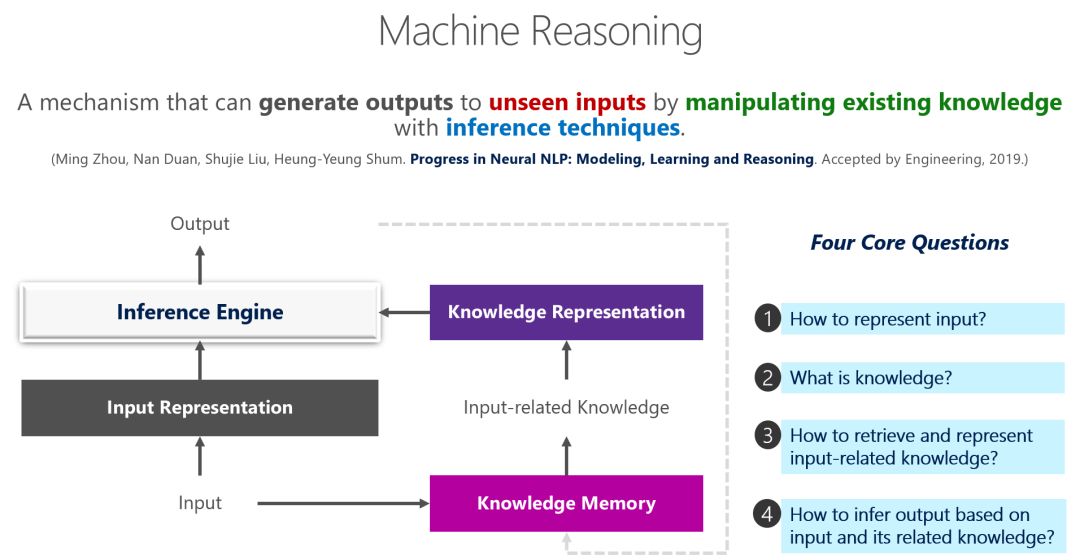
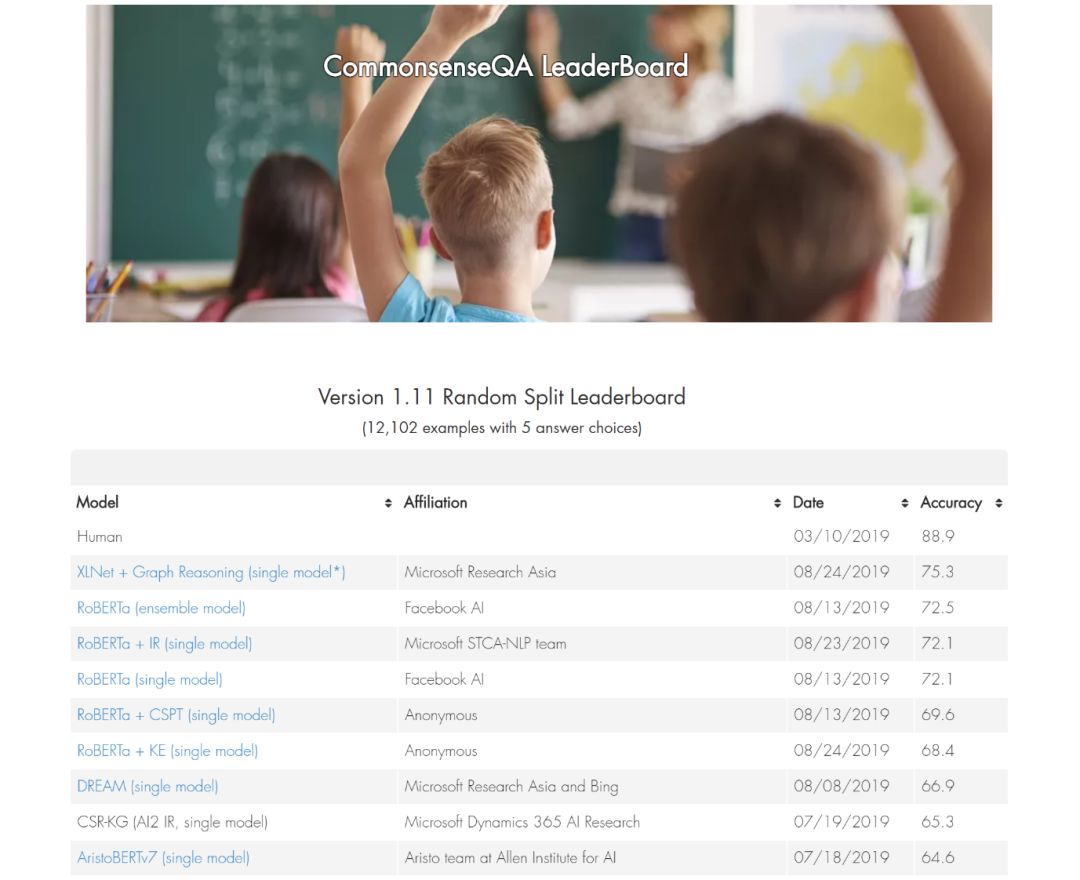
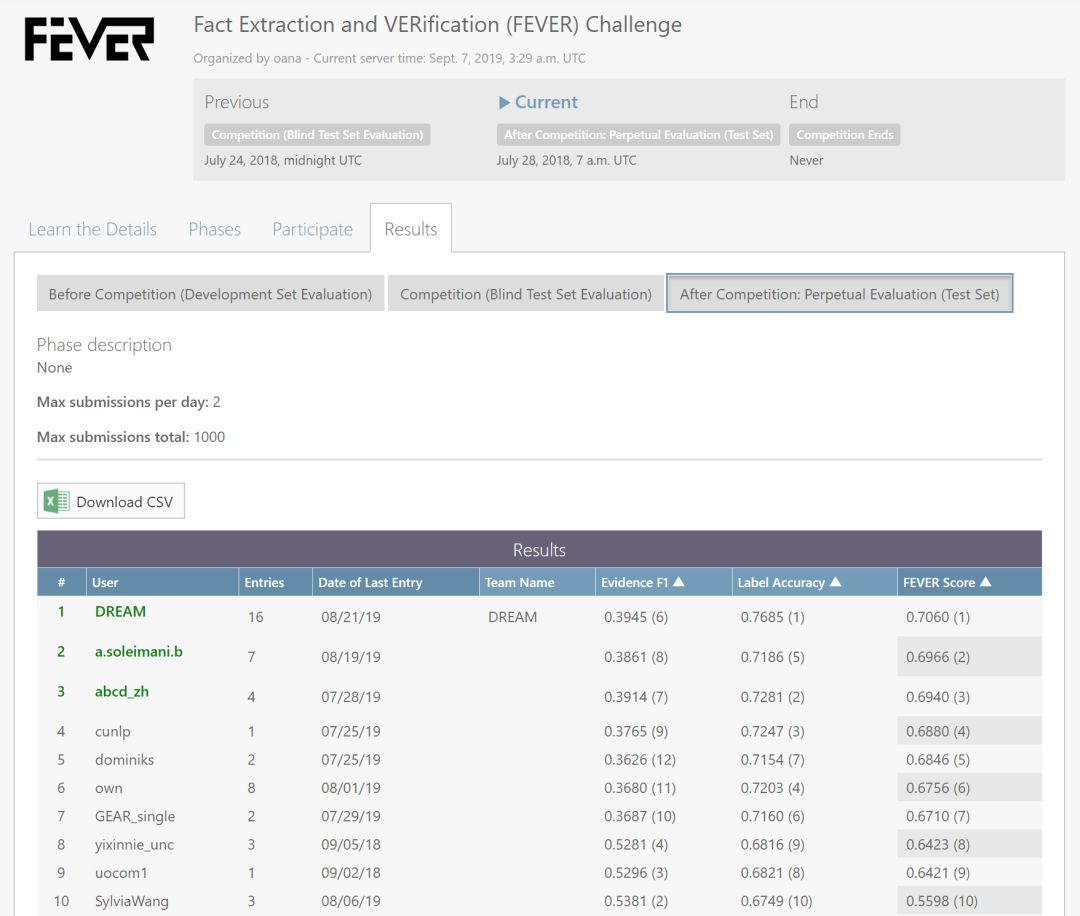
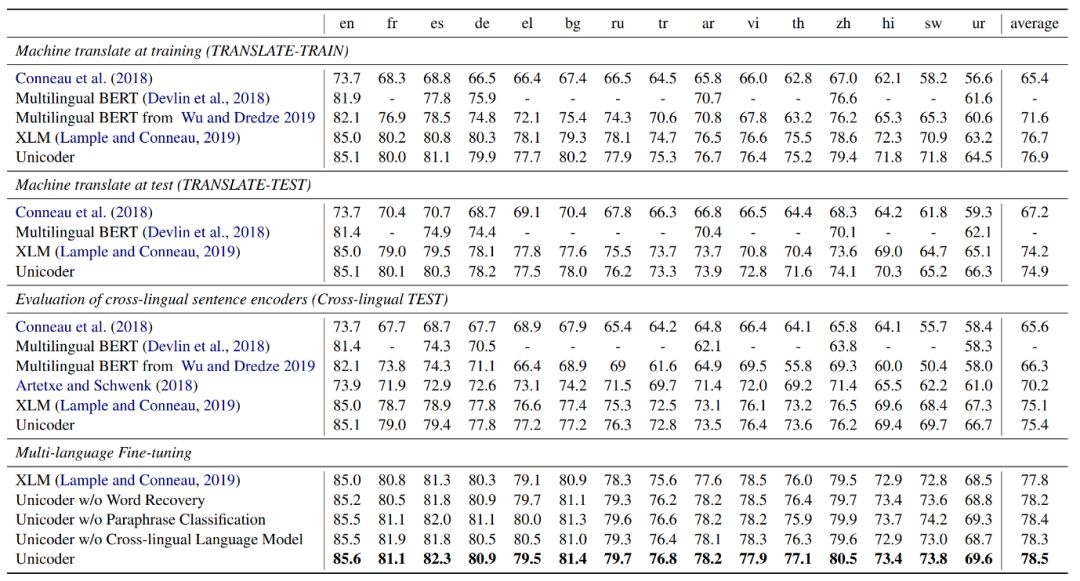
编者按:自然语言处理的发展进化带来了新的热潮与研究问题,研究者们在许多不同的任务中推动机器推理(Machine Reasoning)能力的提升。基于一系列领先的科研成果,微软亚洲研究院自然语言计算组将陆续推出一组文章,介绍机器推理在常识问答、事实检测、自然语言推理、视觉常识推理、视觉问答、文档级问答、多轮语义分析和问答等任务上的最新方法和进展。

更多内容
「LSTM之父」 Jürgen Schmidhuber访谈:畅想人类和 AI 共处的世界 | WAIC 2019
历年 AAAI 最佳论文(since 1996)
一份完全解读:是什么使神经网络变成图神经网络?

登录查看更多
相关内容
Arxiv
15+阅读 · 2018年10月11日




相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日