十年内就能实现通用人工智能?先把组合泛化研究明白吧!

文 | Albert Yang
编 | 白鹡鸰
"乌鸦为什么像写字台?"
因为它们都能produce a few notes (鸟叫/笔记),因为乌鸦和写字台都是思想与记忆的象征(北欧神话),又或者因为,这本身就是一句没有道理的话,类比的是人类之间没有道理的情感。
一直以来,从事物中提取抽象的特征,然后建立新的联系都是人类的特权,我们一边试图用机器模拟这一思维过程,一边又批评机器没有学到精髓。可以说,建立通用人工智能 (Artificial General Intelligence, AGI) 的梦想在每个人工智能相关领域研究者都多少会占有一席之地,但是,该如何去实现呢?假如以自然语言处理为起点来考虑这个问题,我认为,组合泛化将是关键。
什么是组合泛化?
组合泛化(compositional generalization)是基于复合性(compositionality)衍生出来的一个问题,是分布外泛化的(Out-of-Ditribution generalization)的一个子类。组合泛化的目标是让模型基于已知对象的性质,推断未知对象组合的意义。比如说,已知“猫”和“狗”是较为相似的动物,已知“猫会叫”为真命题,那么我们是否能让模型知道,“狗会叫”也是真命题呢?这就是组合泛化的研究内容。
组合泛化并不是一个新议题,它的重要性经过了多年的斟酌并得到了肯定。只是近年来研究人员发现大模型在组合泛化问题上碰壁严重,才使之成为热点。我在参加ACL 2022和Redmond Mooney 聊天时,他感慨,30年前他研究语义解析(semantic parsing)时已经着重研究了组合泛化,10年前他已经把主要研究精力转而投入到多模态和机器人领域,而现在组合泛化和多模态才成为热点。
为大佬的前瞻性和对未来方向的把控能力惊叹。
组合泛化为什么重要?
要理解组合泛化的重要性,首先要回答,机器学习针对的最核心的问题是什么?那就是泛化(generalization)。如果模型缺乏泛化能力,那么模型表现的上限只能是已经见到过的数据。因此,泛化性向来是衡量模型能力的重要指标。
尽管大模型有着惊人的分布内泛化能力,但是分布外泛化仍是这些模型最关键最难以解决的问题。组合泛化是分布外泛化中的重要分支。另一方面,现有的学习模型普遍缺乏推理能力,而组合推理也是推理能力极为重要的一方面。可以说,组合泛化的研究,是针对机器学习中最大的痛点和难点对症下药。
组合推理依赖于常识推理(commonsense reasoning),同时,组合推理和关系推理(relational reasoning)、组合推理和多步推理(multi-hop reasoning)都有着极为密切的关系)。
近年来,随着机器学习在网络结构上的优化进入瓶颈,研究者们不约而同地将目光投向组合泛化。在ACL 2022以“The Next Big Ideas”为主题的演讲中,Heng Ji在强调结构的重要性时,提到使用结构的重要目标之一,就是增强组合泛化能力。Mirella Lapta在讨论故事理解和故事生成的任务时,提到了建模故事结构是可能的解决方案。Dan Roth在关于推理任务的演讲中指出,知识的解构(decompose),重组(compose)和规划(plan)是实现推理的关键步骤。Marco Baroni在关于“machine-to-machine interface”的演讲中,指出组合不同网络是实现这一目标的关键。Hang Li 提出,应当利用符号表达,来提升数值推理的效果。而Yejin Choi直接在她的keynote演讲中,展示了模型组合泛化能力的欠缺,并以此为依据,反驳了在短期内实现通用人工智能的可能性。

需要指出的是,组合泛化不仅在自然语言处理中十分重要,在计算机视觉/多模态中、在机器人学中也非常重要(例如语言到图像生成模型DALLE中Demo里的例子就是展示生成新的场景组合:宇航员在太空中骑马的图片来表明DALLE的强大能力;同样,机器人理解各种指令组合、各种视觉场景组合也是最关键的课题之一),这也是为什么完成组合泛化是实现AGI的重要一步。
自然语言与组合泛化
在NLP的背景下研究组合泛化,对于我而言非常有趣。语言是一种有结构的数据,而结构的规则中又存在相当多的特例和变体。机器学习中最关键问题——领域外泛化对应到语言的结构就是组合泛化。语言在字/词级别和句子级别都有复合性,本文主要关注句子级别的复合性。在这一前提下,语义解析是测试组合泛化能力最合适的任务之一。下面将从两篇我在NAACL 2022中的复合性语义解析(compositional semantic parsing)领域的工作出发,分别谈谈组合泛化的模型和数据两方面。
论文-1
SeqZero: Few-shot Compositional Semantic Parsing with Sequential Prompts and Zero-shot Models
https://arxiv.org/pdf/2205.07381.pdf
论文-2
SUBS: Subtree Substitution for Compositional Semantic Parsing
https://arxiv.org/pdf/2205.01538.pdf
如何改进模型以实现更好的组合泛化?
为了增强模型的组合泛化能力,一种直观的思路就是通过例如模块化网络、中间层的离散结构、神经符号系统等方法为模型设置归纳偏置。
我要说的第一篇论文SeqZero中,语义解析的目标是“将自然语言描述解析为SQL语句” [1]。促使我展开研究的契机是,在了解经典数据集和复现模型时,我发现模型如果在训练数据中只见到“多少人住在芝加哥”类型的数据(即每次见到“多少人住在”,后面总是跟着城市名),即使模型在其他训练数据点中见到过“犹他”是“州”的概念,在测试的时候遇到“多少人住在犹他”,也会将SQL 语句中的表格名称预测为“城市”(“FROM City”)而非“州”(“FROM State”)。模型实际上学到的是从“多少人住在xx”句式结构到“城市” 的虚假关系(spurious correlation),而非根据实际的地点名称来判断“州”或者“城市”。
于是,本文提出使用两种方式来进一步合理利用大型预训练语言模型的能力来实现更好的组合泛化:1. 子问题分解,2. 是预训练与精调模型的集成(ensemble)。
本文使用了以BART作为backbone的预训练模型,部分结论可能与以GPT3作为的预训练模型有所不同,并且本文采用的是prompt-based fine-tuning [2],而非基于示例prompt的in-context learning [3]。
子问题分解:
子问题分解的出发点是把复杂的问题转化为简单的子问题序列,逐步解决。在自然语言到SQL语句解析这个问题中,对应着逐步生成SQL语句的子从句(如“FROM”,“SELECT”,“WHERE”等从句)。对于上面的例子,如果模型可以先解决好“FROM”从句中表格名称(“城市”或“州”)的生成,那么就能更好地预测整句SQL语句。进而,在每一个子问题(子从句)的预测中,可以更好地设计合适的自然语言prompt来帮助挖掘预训练模型中的知识,得到更好的泛化能力。这样的子问题分解和prompt 序列填充的方法在近期预训练模型的推理能力研究(例如本文NAACL的同期或后期工作“Chain of Thought Prompting”等[4]-[6])中,被应用于更广泛的场景。
预训练与精调模型的集成:
在子问题中,由于精调的模型有更好的领域内泛化能力,而预训练模型有更好的领域外泛化能力,我们希望能够集成预训练模型与精调模型,以达到在保证领域内泛化能力的同时,实现更好的领域外泛化能力。
研究问题中的“领域外”对于预训练模型来说可能是“领域内”,因为我们的领域指是相对于给定的少量训练数据而言,而预训练模型可能已经见过我们定义的领域外的组合并且存储有相关的知识。
研究的任务是生成问题(基于prompt的自然语言生成或者SQL语句生成),在生成的每一步,直接集成预训练模型与精调模型的概率并不是一个好的选择,因为未精调的预训练模型的概率几乎分布在词表所有的词上,而精调的模型概率几乎完全只分布在词表中几个允许的词上——比如生成表格名称的步骤,精调模型给出的概率几乎都集中在训练数据中出现的表格名称上。在词表中几个允许的词上,预训练模型与精调模型的概率差别巨大,预训练模型极小的概率分布几乎不会对集成后的结果造成影响。为了解决这个问题,我们在生成的每一步,先用前缀树(trie,常用于实现高效限制解码)高效计算出给定已生成前缀条件下下一个步骤允许生成的所有词,再在这些词上归一化预训练模型的原始概率。最后即可集成预训练模型的归一化概率与精调模型的概率,得到最终在这一步解码时的生成概率。计算公式公式如下:
其中 代表给定已生成的前缀(或者给定的prompt) 时,当前步骤允许生成的词表。 是预训练模型在当前步骤的原始概率。我们提出的通过限制解码对预训练模型归一化再与精调模型集成,这一简单的步骤有望应用于生成任务中更广泛的场景得到具有更强的泛化能力的生成模型。
我们的方法在常用的组合泛化测试数据集GeoQuery和一个我们自建的EcommerceQuery数据集上都取得了明显的提升:
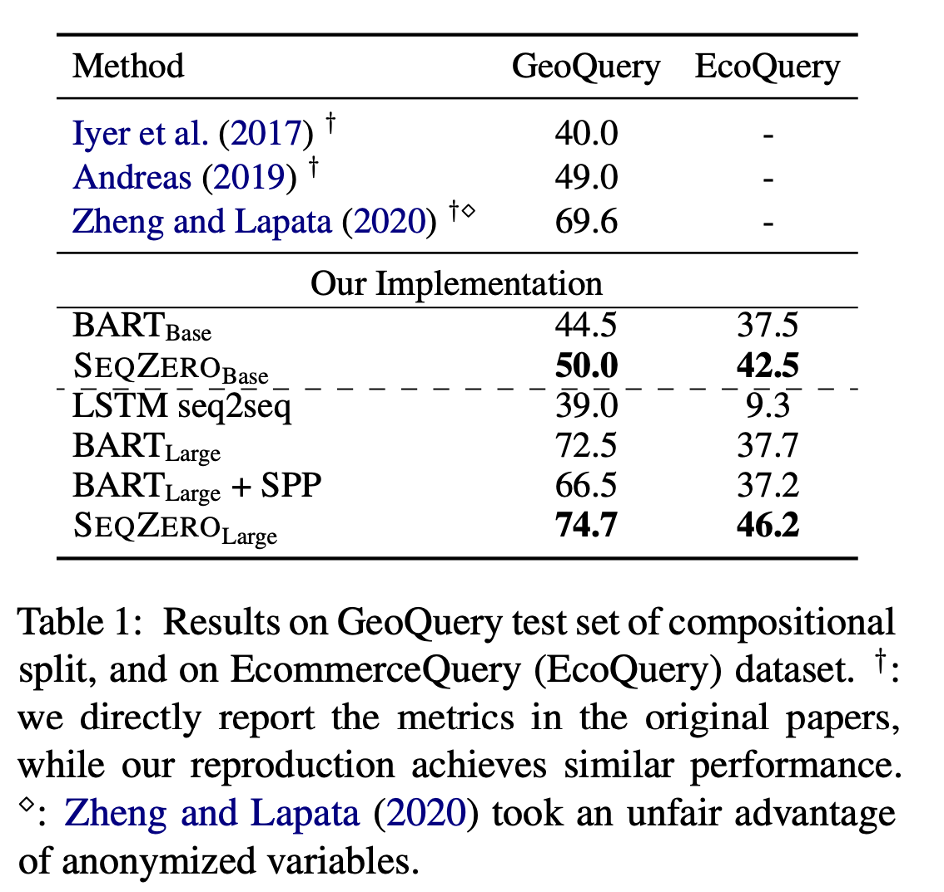
如何调整数据以实现更好的组合泛化?
除了将组合性归纳偏置直接注入到模型中,我们还可以先把组合性的归纳偏置先注入到数据中,以生成大量的扩增数据,然后再让模型从数据中学到这种偏置以实现更好的组合泛化。这就是组合性数据扩增。
我们可以根据重组规则将已有的自然语言与形式语言对数据重组,形成更多样的自然语言与形式语言对,添加到现有数据中,一起训练简单的Seq2seq模型。这样的规则可以是人工设计的(SCFG [7], GECA [8]),也可以是学习出来的。
之前的基于规则的方法往往只能重组交换比较简单的结构,对于复杂的结构,由于自然语言和形式语言的对齐非常困难,重组交换得到的结果往往非常不准确。于是在我们的第二篇文章中,我们提出语义树子树替换的方法来进行组合性数据扩增 [9]。由于语义树子树已经实现了较好的自然语言到形式语言的对齐,我们的子树替换可以发现更复杂的可交换结构,并且较为准确地扩增出更复杂多样的数据。注意在文章中目标是把自然语言解析为另一种形式语言FunQL。
具体来说,如果两个语义树子树根结点的语义表示相近,那么我们就认为这两个子树就是可交换的,于是我们交换两颗子树对应的自然语言与形式语言的部分得到新的自然语言与形式语言对。如下图所示:

从已有的两个句子“美国最小的州的最大的城市是什么”和“最大的州的人口有多少”以及相应的语义表示,可以准确扩增出“美国最小的州的最大的城市的人口有多少”以及相应的形式语义表示。
这样的重组能够在数据扩增的阶段就让模型见到更多可能的组合(甚至扩增出来的数据就已经覆盖了一些测试集中的数据),从而提升模型的组合泛化能力。
那么怎么得到这样的语义树呢?对于小的数据集,可以通过规则辅助少量的人工标注得到,对于更大规模的数据集,我们可以从自然语言和形式语言归纳得出(Tree Induction),例如,作为Span based Semantic Parsing [10] 中Hard EM 中间表示的副产品,我们可以归纳得出语义树。需要注意的是,因为可以利用形式语言中丰富且严格的语义表示信息,基于自然语言和形式语言的Tree Induction要比自然语言本身的Tree Induction要准确很多。这也是为什么我们能得到较为准确的语义树,从而让这种数据扩增奏效的原因。如下实验结果表明我们的数据扩增方法在GeoQuery数据集尤其是组合泛化的测试场景中带来了显著提升:
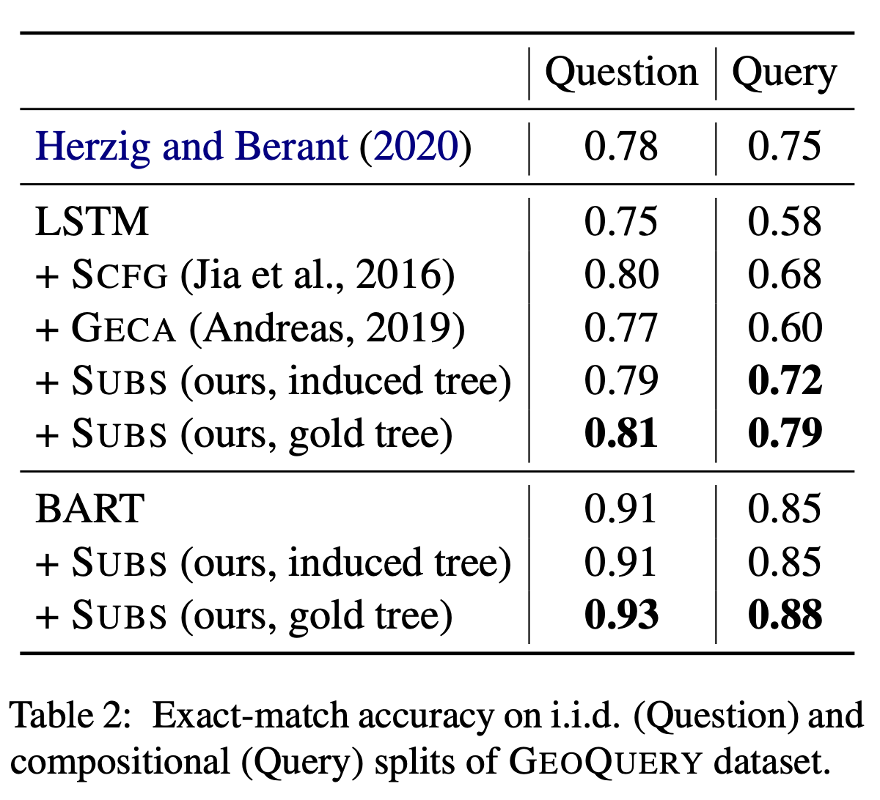
数据与模型关系的探讨
或许有人会问,既然Span-based Semantic Parsing通过直接将Span和Tree的结构偏置注入到模型中,已经可以提升组合性语义解析表现,那为什么还要用中间产物Tree来做数据扩增,进而训练模型呢?这就涉及到另一个有趣且宽泛的问题:将归纳偏置通过某种结构直接注入到模型中,或者先将归纳偏置注入到数据中再训练一个统一的模型架构从而使之具有相应的归纳偏置,哪一个效果更好呢?
基于我的实验与阅读经验,将特定的归纳偏置直接注入到模型中,在很多情况下并不能按我们的期望奏效,甚至会影响模型原有的效果。尤其是在大模型时代,我们已经看到了随着模型规模和预训练数据量的增加,简单统一的Transformer架构已经可以实现越来越惊人的效果。例如,虽然ViT没有利用卷积这个显著帮助计算机视觉的特有结构化偏置操作,但在一定数据规模和模型规模下仍然能够匹配甚至超过之前的卷积网络。由于我们对Transformer架构为什么能够奏效还缺乏统一有效的理解,按我们的预想魔改模型架构就甚至可能会阻碍模型的预训练效果。另一方面,越来越多的证据表明,在数据量与模型越来越大的情况下,特定的模型结构偏置注入带来的效果会越来越小。于是在不影响模型结构的情况下,通过数据扩增给模型提供更多领域外泛化的困难样例,就成了一个重要选项。
总结
我们已经看到,随着模型规模增大,组合泛化的能力已经越来越强。并且,似乎有证据表明,prompt-tuning 似乎可以比精调整个模型(或者prompt-based fine-tuning)具有更好的组合泛化能力 [11]。但是总体来讲,模型的组合泛化能力和分布内泛化能力比起来却仍有欠缺,这也再次说明了即使在大模型时代,组合泛化仍是值得被研究的最关键问题之一。
作者简介
本科毕业于北大,Georgia Tech硕士(导师为杨笛一教授)毕业后,暂时放弃UW CS NLP的PhD,在工业界Amazon做了Applied Scientist。
个人主页:
https://jingfengyang.github.io/
Twitter:
https://twitter.com/JingfengY
知乎:
https://www.zhihu.com/people/albertyang-86
公众号:
AGI之路 ID: ZenOfAGI
扫码关注:

另外如果有意向来Amazon Search Query Understanding组(https://amazonsearchqu.github.io/)做research internship,可联系jingfe@amazon.com (杨靖锋).
邮件标题:Research Internship + Name + Time (Spring / Summer / Fall / Winter) + 个人简历
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Yang, Jingfeng, et al. "SEQZERO: Few-shot Compositional Semantic Parsing with Sequential Prompts and Zero-shot Models." NAACL 2022 Findings.
[2] Gao, Tianyu, Adam Fisch, and Danqi Chen. "Making pre-trained language models better few-shot learners."ACL 2021.
[3] Brown, Tom, et al. "Language models are few-shot learners." NeurlPS 2020.
[4] Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arxiv 2022.
[5] Zhou, Denny, et al. "Least-to-Most Prompting Enables Complex Reasoning in Large Language Models." arxiv 2022.
[6] Kojima, Takeshi, et al. "Large Language Models are Zero-Shot Reasoners." arxiv 2022.
[7] Jia, Robin, and Percy Liang. "Data recombination for neural semantic parsing." ACL 2016.
[8] Andreas, Jacob. "Good-enough compositional data augmentation." ACL 2020.
[9] Yang, Jingfeng, Le Zhang, and Diyi Yang. "SUBS: Subtree Substitution for Compositional Semantic Parsing." NAACL 2022.
[10] Herzig, Jonathan, and Jonathan Berant. "Span-based semantic parsing for compositional generalization. ACL 2021.
[11] Qiu, Linlu, et al. "Evaluating the Impact of Model Scale for Compositional Generalization in Semantic Parsing." arxiv 2022.
 后台回复关键词【入群】
后台回复关键词【入群】
