ICLR 2022 | 将GNN蒸馏给MLP:实现准确且快速的图机器学习模型部署

作者 | 张欣
单位 | 香港理工大学
研究方向 | 图神经网络、自监督学习

收录来源:
论文来源:

Background
图神经网络(Graph Neural Networks GNNs)最近在图机器学习(Graph Machine Learning GML)研究中很火,并在节点分类(node classification)任务上表现很好。但是,对于大规模工业界的应用来说,主流的模型仍然是多层感知机(Multilayer Perceptron MLP)(PS:一般而言,MLP 的表现要比 GNN 差很多)。造成这种学术届和工业届差距的原因之一是 GNNs 中的图依赖性(graph dependency)。这使得 GNNs 难以部署在需要快速推理(fast inference)或者对延迟(latency)敏感的应用中。
由图依赖性(graph dependency)引起的邻居节点获取(neighborhood fetching)是导致 GNN 延迟性高的主要来源之一。对目标节点的推理/预测(inference)需要获取许多邻居节点的拓扑结构(topology)和特征(feature/attribute),所有目前有工作关注在如何做 GNN 的推理加速(inference acceleration)。
常见的推理加速模型有剪枝(pruning)和量化(quantization)。它们是通过减少乘加运算(Multiplication-and-ACcumulation MAC)来在一定程度上加快 GNN 的推理速度。然而,由于来自 GNN 本质的图依赖性没有得到解决,剪枝(pruning)和量化(quantization)对于提升 GNN 的推理速度是有限的(limited)。

Motivation
与 GNNs 不同,MLPs 因为输入仅是节点的特征(node attribute),所以它对图数据没有图依赖性(graph dependency),且比 GNNs 更容易部署。同时,MLPs 还有另一个好处,即避开了图数据在线预测过程中经常发生的冷启动问题。这意味着,即使新节点的邻居信息不能立即获得,MLP 也能合理地推断出新节点的表征。
然而,也因为 MLP 不依赖于邻居信息,导致 MLP 的表现通常比 GNN差。这里我们提出一个问题:我们能否在 GNN 和 MLP 之间架起一座桥梁,既能享受 MLP 的低延迟和无图依赖性,又能达到和 GNN 表现得一样好?
即,这篇文章想要构建一个模型,这个模型既有 MLP 的低延迟和无图依赖性的优点,又可以达到和 GNN 相同的表现/预测准确率,从而解决 GNN 延迟性高的问题。具体分析如下:
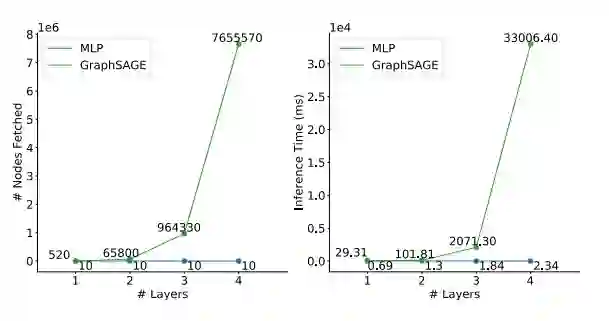
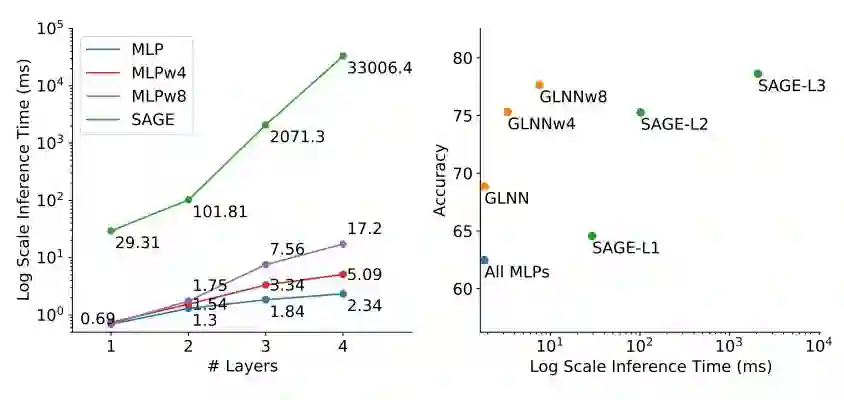
图 1 展示了 GNNs 随着层数的增加所需的邻居节点个数和推理时间呈指数级上升。反观 MLP,在相同的层数下,MLP 的推理时间会少很多,且只是线性增长。这一推理时间的差距可以解释 MLP 比 GNN 在业界用的更广泛的原因。
进一步,我们发现有两个因素加剧了邻居节点获取(node-fetching)的延迟:1. GNN 的架构有越来越深的趋势,从 64 层到甚至 1001 层。2. 工业场景下的图很大,无法装入单台机器的内存,所以邻居节点获取需要从内存和硬盘的交互,这进一步导致了延迟。
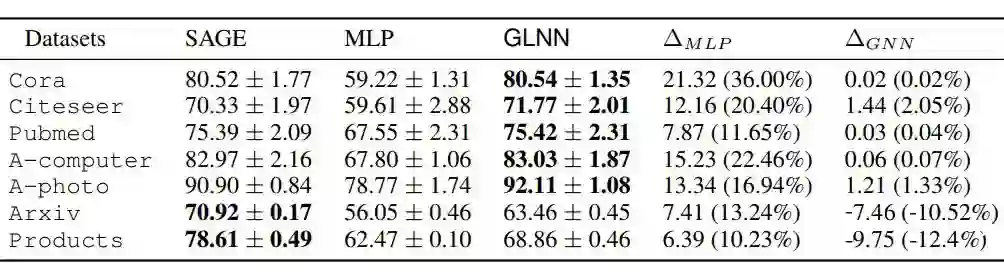
另一方面,MLPs 无法利用图的拓扑结构(graph topology),这降低了 MLPs 在节点分类(node classification)任务上的性能。例如,GraphSAGE 在 ogbn-Products 数据集上的准确率为 78.61%,而在相同层数的 MLP 上只有 62.47%。然而,最近在 CV 和 NLP 领域的研究表明,大型的或是轻微修改过的 MLPs 可以达到与 CNN 和 Transformer 差不多的表现。
所以,这篇文章想要将 GNN 和 MLP 的优点结合起来,以获得高准确率且低延迟的模型。

Method
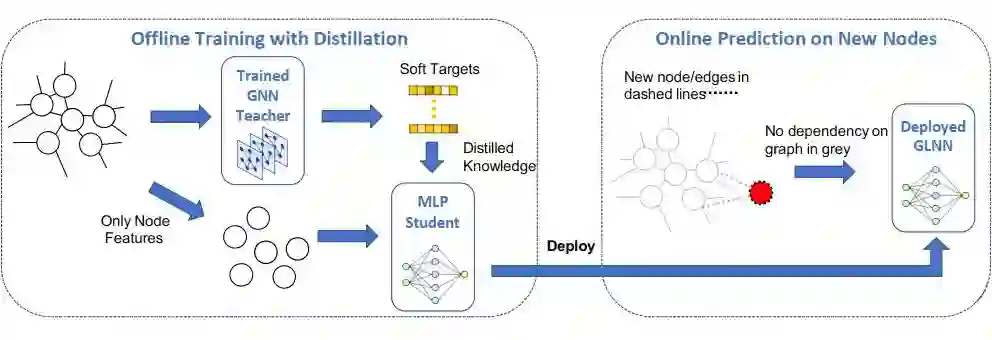
为了结合 GNN 和 MLP 的优点来搭建一个高准确率且低延迟的模型,这篇文章提出了一个模型叫做 Graph-less Neural Network(GLNN)。具体来说,GLNN 是一种涉及从教师 GNN 到学生 MLP 的知识蒸馏(knowledge distillation)模型。经过训练后的学生 MLP 即为最终的 GLNN,所以 GLNN 在训练中享有图拓扑结构(graph topology)的好处,但在推理中没有图依赖性(graph dependency)。
知识蒸馏(knowledge distillation KD)是在 Hinton 等人在 2015 年提出的一个范式,可以将知识从一个繁琐复杂的教师转移到一个更简单的学生。这篇文章就想要通过知识蒸馏(knowledge distillation)从复杂的教师 GNN 中训练一个优质的 MLP。
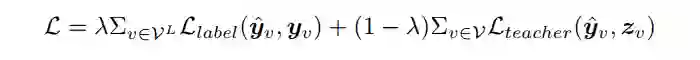
▲ 公式1
经过 KD 训练完后的学生模型,即 GLNN,本质上是一个 MLP。因此,GLNN 在推理过程中没有图依赖性(graph dependency),并且和 MLP 一样快。另一方面,通过 KD,GLNN 的参数会被优化到和 GNN 具体同样的预测和泛化的能力,并有更快的推理和更容易部署的额外好处。图 2 展示了 GLNNs 的框架图。

Experiment
由于 GLNN 的模型非常简单,所以实验部分是这篇文章的重点,从各个角度证明并阐述了 GLNN 的有效性且有效的原因。实验部分主要是回答如下 6 个问题
1. GLNN与MLPs和GNNs相比如何?
我们首先将 GLNN 与具有相同层数和隐藏维度(hidden dimension)的 MLPs 和 GNNs,在标准的直推设置(transductive setting)下进行比较。
实验结果如表 1 所示,所有 GLNN 的性能都比 MLPs 有很大的提高。在较小的数据集上(前5行),GLNNs 甚至可以超过教师 GNNs。换句话说,在相同的条件下,存在一组 MLP 参数,其性能可以与 GNN 相匹敌。对于大规模(large-scale)OGB 数据集(最后2行),GLNN 的性能比 MLP 有所提高,但仍然比教师 GNN 差。然而这种 GLNN 和教师 GNN 在大规模数据集上的这种差距可以通过增加 MLP 的层数来缓解,如表 2 所示。
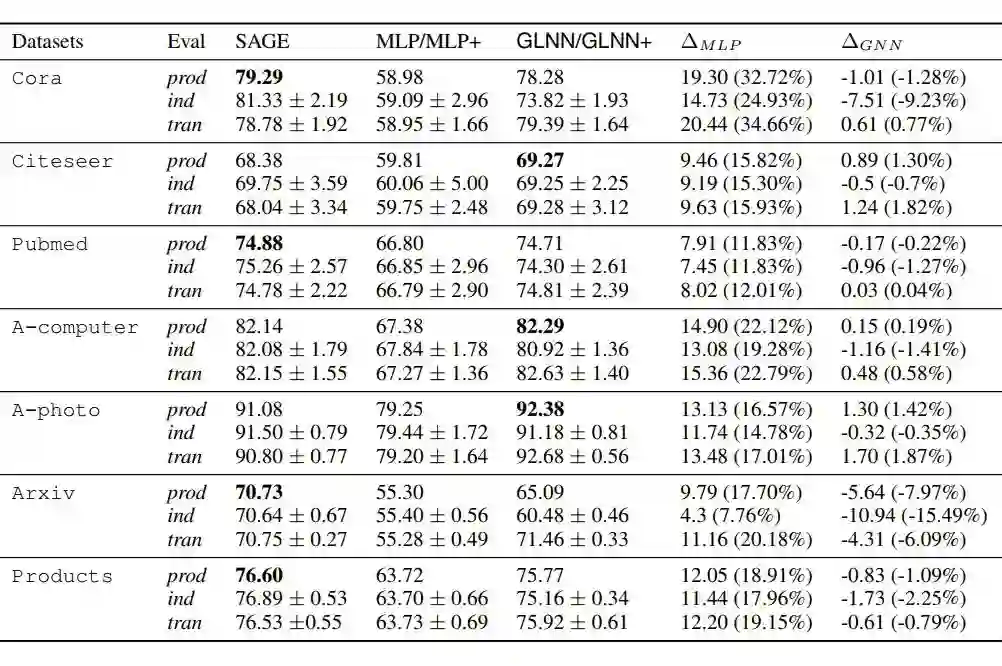
由图 3(右图)所示,一方面逐渐增加 GLNN 的层数可以使其性能接近于 SAGE。另一方面,当 SAGE 的层数减少时,准确率会迅速下降到比 GLNNs 更差。

▲ 图3:加深的GLNN与GNN的表现比较
2. GLNN在两种不同的实验设置下都能很好地工作吗?
直推设置(transductive setting)是对节点分类任务常见的设置,但在这个设置下模型只能对见过的节点进行进行预测(即会使用完整的邻接矩阵 adjacency matrix)。为了更好地评估 GLNN 的表现,这篇文章还考虑了在归纳设置(inductive setting)下进行实验(即训练时用的邻接矩阵不是完整的,而是剔除了测试集的节点及相应的边)。具体的实验设置请参考原文。实验结果如表 3 所示。
在表 3 中,我们可以看到 GLNN 在归纳设置(inductive setting)下的性能仍能比 MLP 提升许多。在 6/7 个数据集上,GLNN 的性能可以和 GNNs 的接近。在大规模的 Arxiv 数据集上,GLNN 的性能明显低于 GNNs,文章中给出的原因是 Arxiv 数据集的数据分割(data split)比较特殊,会导致测试节点和训练节点之间的分布转移(distribution shift),从而使 GLNN 很难通过 KD 学习到邻居信息。
3. GLNN与其他推理加速方法相比如何?
常见的推理加速(inference accerleration)方法有剪枝(pruning)和量化(quantization)。这两个方法通过减少模型的乘加运算(Multiplication-and-ACcumulation MAC)来进行加速。但本质上它们没有解决因为需要获取邻居信息(neighbor-fetching)而导致的延迟(latency)。所以,这一类方法在 GNNs 上加速的提升没有在 NNs 上的那么多。
对于 GNNs 来说,邻居采样(neighbor sampling)也被用来减少延迟。所以在这一实验中,我们的基线(baseline)有SAGE、QSAGE(从 FP32 到 INT8 的量化 SAGE 模型)、PSAGE(有 50% 权重剪枝的 SAGE)、Neighbor Sample(采样 15 个邻居 fan-out 15)。实验结果如表 4 所示,GLNN 要比所有的基线快得多。

▲ 表4:GLNN和其基线在归纳设置(inductive setting)下的推理时间(inference time)
另两种被视为推理加速的方法是 GNN-to-GNN 的 KD(即教师和学生网络都是GNN),比如 TinyGNN 和 Graph Augmented-MLPs(GA-MLPs),比如 SGC 和 SIGN。GNN-to-GNN KD 的推理时间会比相同层数下的普通 GNNs 慢,因为通常会有一些额外的开销,比如 TinyGNN 中的 Peer-Aware Module(PAM)。
GA-MLPs 通常需要预先计算增强的节点特征并对其应用MLPs。因为有预计算(预计算不计入推理时间),所以 GA-MLPs 的推理时间和 MLPs 相同。因此,对于 GLNN 和 GNN-to-GNN 和 GA-MLPs 的推理时间比较,可以等价为 GLNN 和 GNN 和 MLP 进行比较。
实验结果如图 3 左图所示,GNN 比 MLP 在推理上慢得多。而由于 GA-MLPs 无法对归纳节点进行完全的预计算,GA-MLPs 仍然需要获取邻居节点,这会让它在归纳设置(inductive setting)中比 MLP 慢得多,甚至要比剪枝过的 GNN 和 TinyGNN 还要慢。所以,GLNN 要比 GNN-to-GNN 和 GA-MLPs 的基线快得多。
4. GLNN如何从KD中获益?
通过损失曲线的图证明 KD 可以通过正则化(regularization)和归纳偏见的转移来找到使得 MLP 达到和 GNN 类似表现的参数,证明 GLNN 受益于教师输出中包含的图拓扑结构信息(graph topology knowledge)。具体细节,有兴趣的读者可以自行阅读原文。
5. GLNN是否有足够的模型表现力?
直观来说,在节点分类任务中,利用邻居信息的 GNN 表现比 MLP 更强大。因此,MLPs 是否与 GNNs 有同样的表现里来代表图数据呢?这篇文章给出的结论是:在节点特征(node attribute)非常丰富的前提下,MLPs 和 GNNs 具有相同的表现力。具体细节,有兴趣的读者可以自行阅读原文。
6. GLNN何时会失效?
当每个节点都由其的度(degree)或是否形成一个三角形来标记。那么 MLPs 就无法拟合即 GLNN 失效。但这种情况是非常罕见的。对于实际的图机器学习任务,节点特征和该节点在拓扑结构中的角色往往是高度相关的。因此 MLPs 即使只基于节点特征也能取得合理的结果,而 GLNNs 则有可能取得更好的结果。

Ablation Study
我们对 GLNN 的有噪声的节点特征、归纳设置下的分割率(inductive split rates)和教师 GNN 结构做了消融研究。下述仅展现结论,实验细节有兴趣的读者可自行阅读原文。
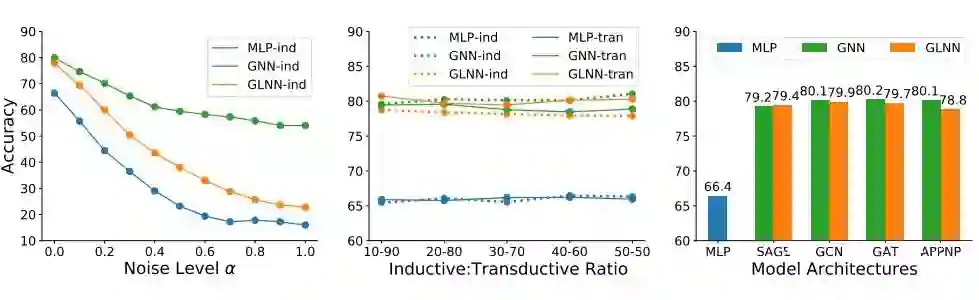
▲ 图4
5.1 Noisy node features
我们通过在节点特征(node features)中加入不同程度的高斯噪声以减少其与标签的相关性。我们用 表示添加噪声的程度。实验结果如图 4-左图所示,随着 的增加,MLP 和 GLNN 的性能比 GNN 下降得更快。当 较小时,GLNN 和 GNN 的性能仍然相当。
5.2 Inductive split rate
在图 5-中图,我们展示了不同分割率下 MLP、GNN、GLNN 的性能。根据实验结果,随着分割率的增加即归纳部分的增加,GNN 和 MLP 的性能基本保持不变,而 GLNN 的归纳性能略有下降。当遇到大量的新数据时,从业者可以选择在部署前对根据所有的数据重新训练模型。
5.3 Teacher GNN architecture
在图 5-右图中,我们展示了使用其他各种 GNN 作为教师的结果,比如 GCN、GAT 和 APPNP。我们看到 GLNN 可以从不同的老师那里学习,并都比 MLPs 有所提高。四个老师中,从 APPNP 中提炼出来的 GLNN 比其他老师的表现要稍差一些。一个可能的原因是,APPNP 的第一步是利用节点自身的特征进行预测(在图上传播之前),这与学生 MLP 的做法非常相似,因此提供给 MLP 的额外信息比其他教师少,导致表现较差。

Conclusion
这篇文章研究了是否可以结合 GNN 和 MLP 的优点,以实现准确且快速的图机器学习模型部署。我们发现,从 GNN 到 MLP 的 KD 有助于消除推理图的依赖性,从而使 GLNN 比 GNN 快 146×-273x 倍且性能不会降低。我们对 GLNN 的特性做了全面研究。在不同领域的 7 个数据集上取得的好结果表明,GLNN 可以成为部署延迟约束模型的一个好选择。

Personal Comments
这篇文章提出了一个非常落地的科研问题,即如何解决 GNN 的推理时间过长无法在现实世界应用上使用。它选择使用了知识蒸馏(knowledge distillation)的方法来解决这个问题,即把 GNNs 的知识转换到 MLPs 上,使得 MLP 可以达到与 GNN 相匹敌的性能。笔者是非常喜欢这篇文章的,这篇文章的模型简单且有效,通过大量的实验从各个角度验证 GLNN 的有效性。

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



