是什么在支撑特斯拉的技术演进?| 清华叉院赵行解读FSD算法新进展

来源:智源社区
本文为约6318字,建议阅读12分钟
本文介绍了
清华大学交叉信息研究院助理教授
赵行
整理的
Tesla FSD算法方面值得重点关注的进展
。

导读:在北京时间10月1日的Tesla AI Day上,马斯克发布了初版的Optimus机器人,在造“人”之路上迈出了实质性的一步。而与此同时,自动驾驶FSD的更多细节也慢慢浮现在大众的眼前。清华大学交叉信息研究院助理教授、福布斯中国30位30岁以下精英(2020年),青源研究组成员赵行整理了Tesla FSD算法方面值得重点关注的进展与大家分享。
Autopilot负责人Ashok在一开场就讲到,特斯拉是一个典型的AI公司,过去一年训练了75,000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来作者分几个方面来解读特斯拉FSD的算法和模型进展。
-
感知 Occupancy Network -
规划 Interactive Planning -
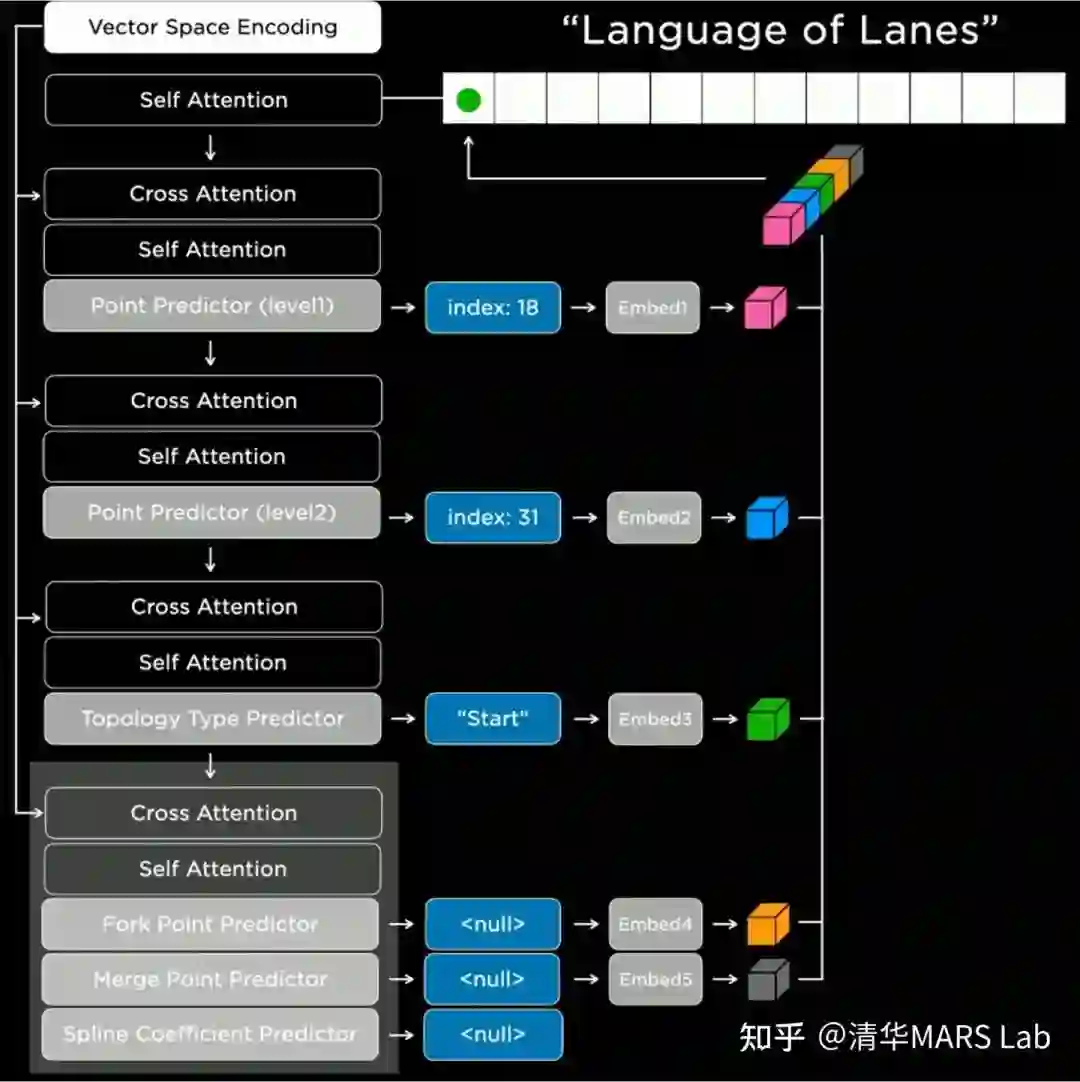
矢量地图 Lanes Network -
自动标注 Autolabeling -
仿真 Simulation 基础设施 Infrastructure
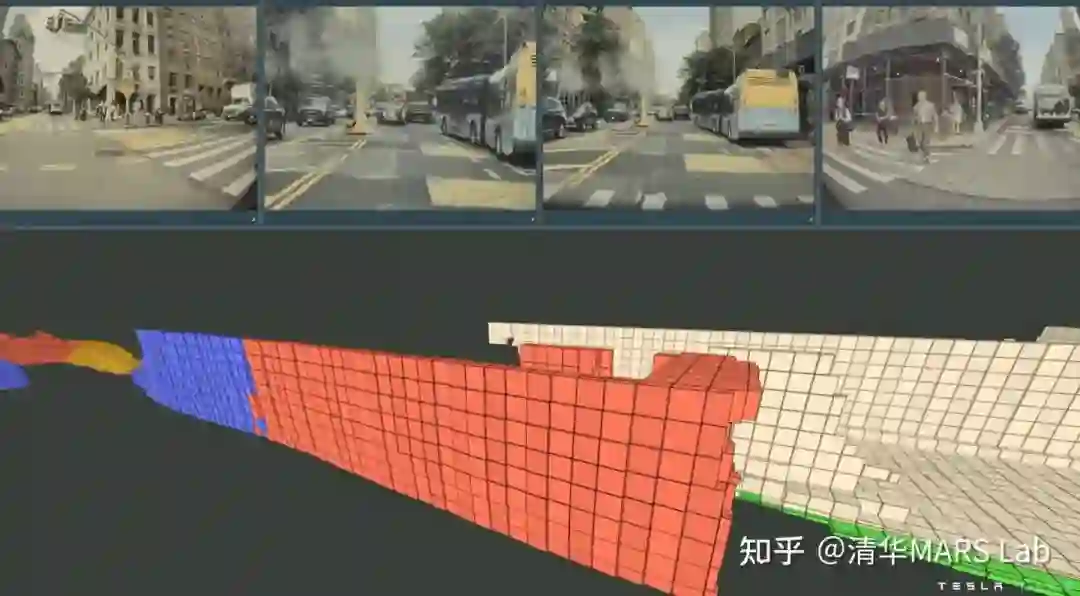
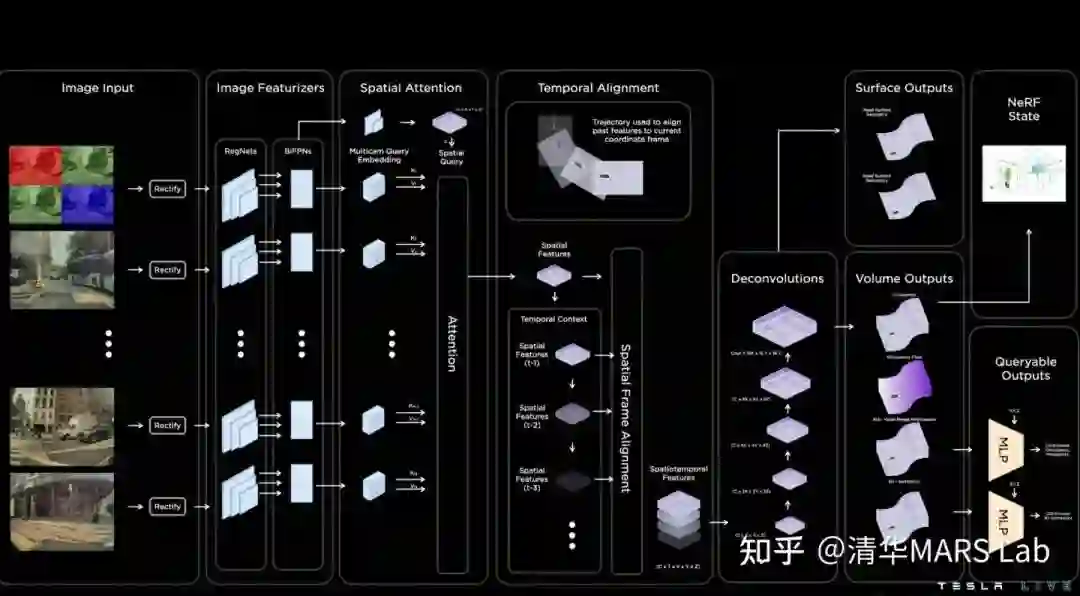
01. 感知 Occupancy Network
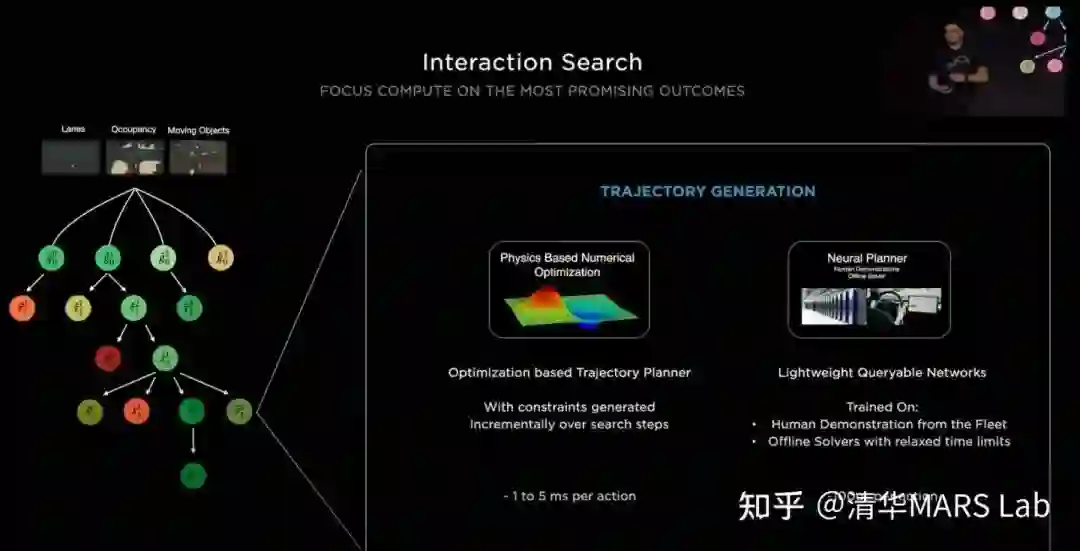
树搜索是轨迹规划常用的算法,可以有效地发现各种交互情形找到最优解,但用搜索的方法来解决轨迹规划问题遇到的最大困难是搜索空间过大。例如,在一个复杂路口可能有20辆与自车相关,可以组合成超过100种交互方式,而每种交互方式都可能有几十种时空轨迹作为候选。因此特斯拉并没有采用轨迹搜索的方法,而是用神经网络来给一段时间后可能到达的目标位置(goal)进行打分,得到少量较优的目标。
在确定目标以后,我们需要确定一条到达目标的轨迹。传统的规划方法往往使用优化来解决该问题,解优化并不难,每次优化大约花费1到5毫秒,但是当前面步骤树搜索的给出的候选目标比较多的时候,时间成本我们也无法负担。因此特斯拉提出使用另一个神经网络来进行轨迹规划,从而对多个候选目标实现高度并行规划。训练这个神经网络的轨迹标签有两种来源:第一种是人类真实开车的轨迹,但是我们知道人开的轨迹可能只是多种较优方案中的一种,因此第二种来源是通过离线优化算法产生的其他的轨迹解。
在得到一系列可行轨迹后,我们要选择一个最优方案。这里采取的方案是对得到的轨迹进行打分,打分的方案集合了人为制定的风险指标,舒适指标,还包括了一个神经网络的打分器。
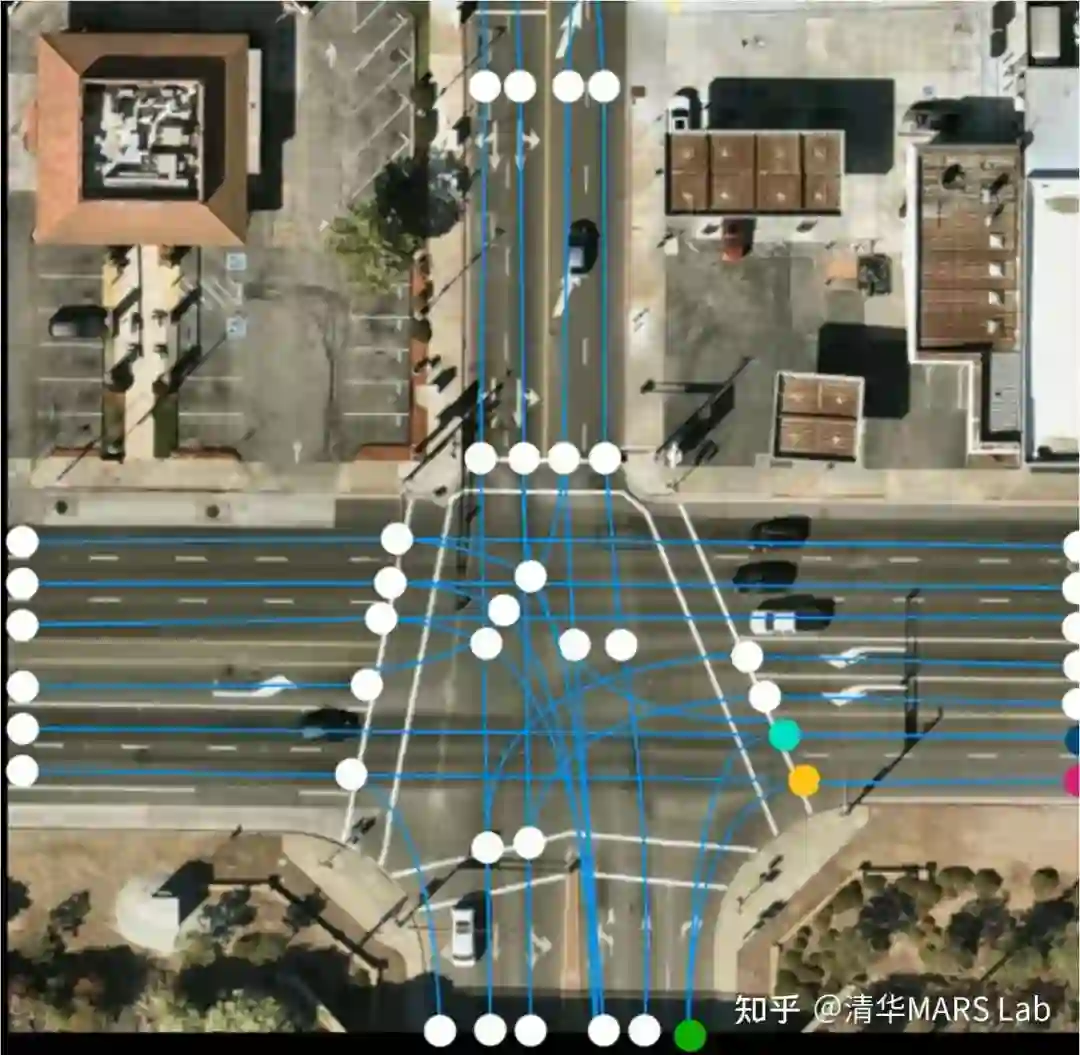
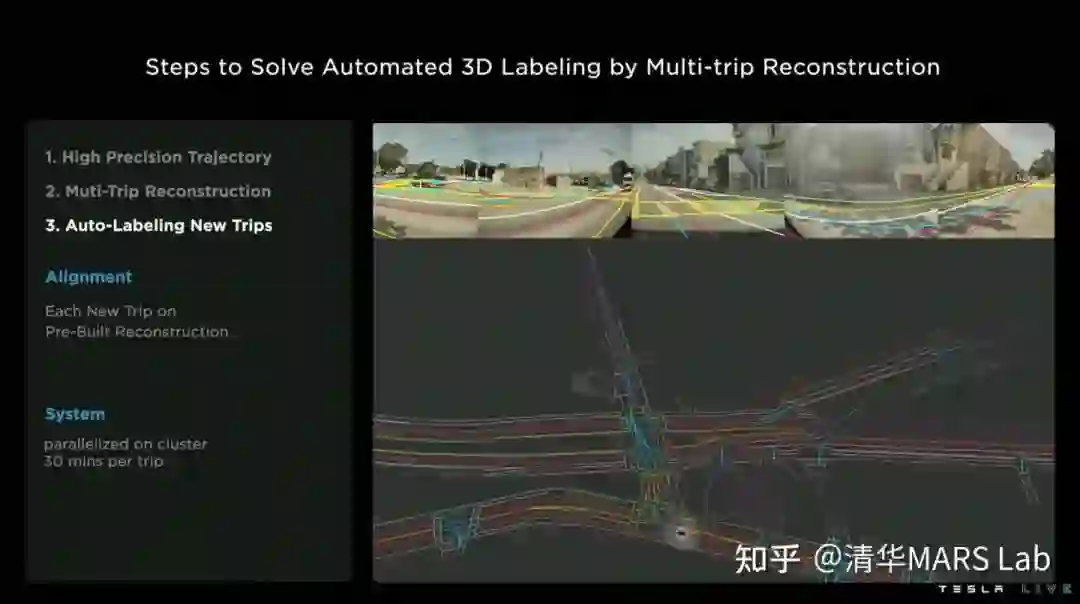
通过视觉惯性里程计(visual inertial odometry)技术,对所有的旅程进行高精度轨迹估计。
多车多旅程的地图重建,是该方案中的最关键步骤。该步骤的基本动机是,不同的车辆对同一个地点可能有不同空间角度和时间的观测,因此将这些信息进行聚合能更好地进行地图重建。该步骤的技术点包括地图间的几何匹配和结果联合优化。
对新旅程进行车道自动标注。当我们有了高精度的离线地图重建结果后,当有新的旅程发生时,我们就可以进行一个简单的几何匹配,得到新旅程车道线的伪真值(pseudolabel)。这种获取伪真值的方式有时候(在夜晚、雨雾天中)甚至会优于人工标注。

路面生成:根据路沿进行路面的填充,包括路面坡度、材料等细节信息。
车道线生成:将车道线信息在路面上进行绘制。
植物和楼房生成:在路间和路旁随机生成和渲染植物和房屋。生成植物和楼房的目的不仅仅是为了视觉的美观,它也同时仿真了真实世界中这些物体引起的遮挡效应。
其他道路元素生成:如信号灯,路牌,并且导入车道和连接关系。
加入车辆和行人等动态元素。
06. 基础设施 Infrastructure

参考文献
[2] Li, Z., Wang, W., Li, H., Xie, E., Sima, C., Lu, T., Yu, Q. and Dai, J., 2022. BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers. arXiv preprint arXiv:2203.17270.
[3] Jiang, Y., Zhang, L., Miao, Z., Zhu, X., Gao, J., Hu, W. and Jiang, Y.G., 2022. PolarFormer: Multi-camera 3D Object Detection with Polar Transformers. arXiv preprint arXiv:2206.15398.
[4] Liu, Y., Wang, T., Zhang, X. and Sun, J., 2022. Petr: Position embedding transformation for multi-view 3d object detection. arXiv preprint arXiv:2203.05625.
[5] Cao, A.Q. and de Charette, R., 2022. MonoScene: Monocular 3D Semantic Scene Completion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 3991-4001).
[6] Zhao, H., Gao, J., Lan, T., Sun, C., Sapp, B., Varadarajan, B., Shen, Y., Shen, Y., Chai, Y., Schmid, C. and Li, C., 2020. Tnt: Target-driven trajectory prediction. In Conference on Robot Learning 2020, arXiv:2008.08294
[7] InterSim, https://tsinghua-mars-lab.github.io/InterSim/
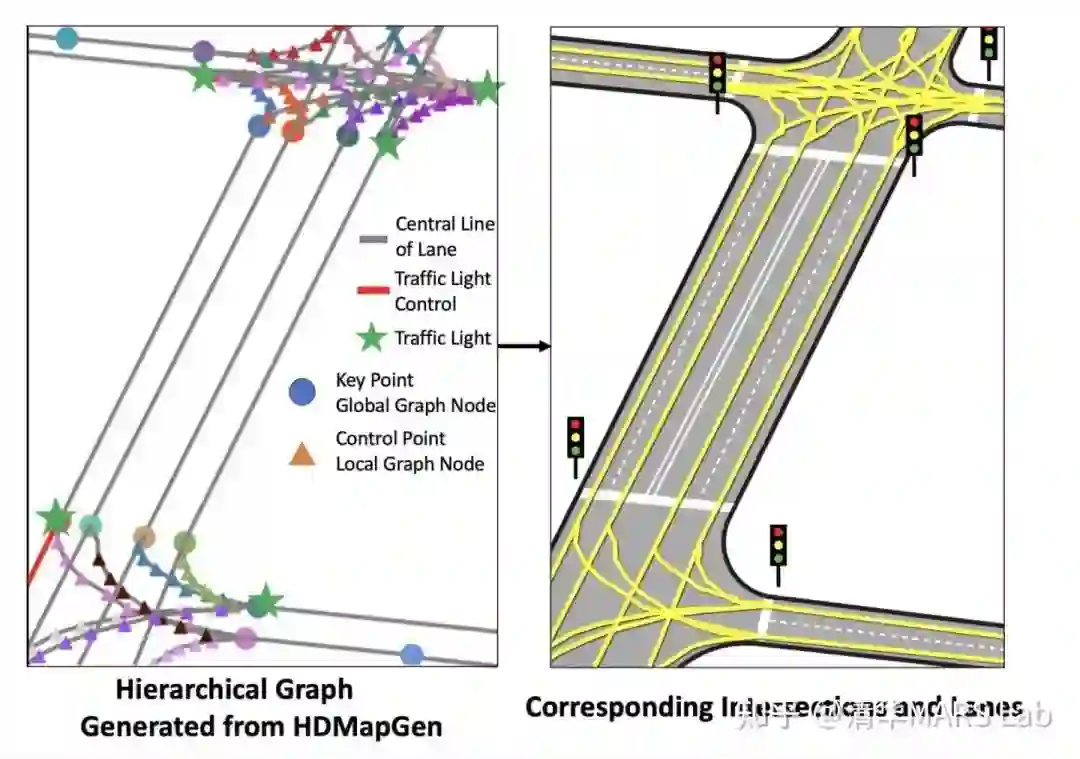
[8] Mi, L., Zhao, H., Nash, C., Jin, X., Gao, J., Sun, C., Schmid, C., Shavit, N., Chai, Y. and Anguelov, D., 2021. HDMapGen: A hierarchical graph generative model of high definition maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4227-4236).
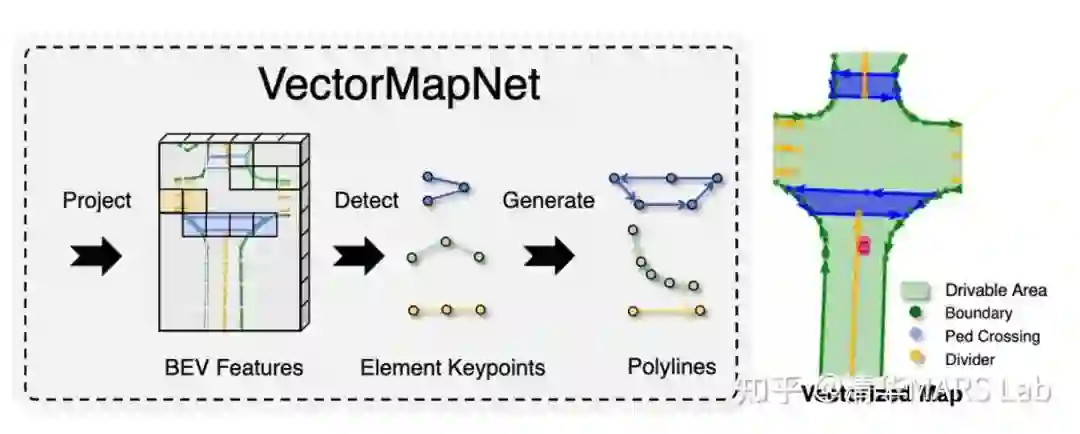
[9] Liu, Y., Wang, Y., Wang, Y. and Zhao, H., 2022. VectorMapNet: End-to-end Vectorized HD Map Learning. arXiv preprint arXiv:2206.08920.





