
超越MobileNetV3的轻量级网络(文末论文下载)



这篇文章之前我们计算机视觉研究院已经分享过!今天我们再来说说这个框架~
虽然说mobileNet或者是shuffleNet提出了使用depthwise或者是shuffle等操作,但是引入的1x1卷积依然会产生一定的计算量。
为什么1x1依然会产生较大的计算量?
看卷积计算量的计算公式n∗h∗w∗c∗k∗kn*h*w*c*k*kn∗h∗w∗c∗k∗k,可以发现,由于c和n都是比较大的,所以会导致这个计算量也是比较大的,但是作者在分析输出的特征图的时候发现,其实有些特征图是比较相似的。
Introduction
目前,神经网络的研究趋向于移动设备上的应用,一些研究着重于模型的压缩方法,比如剪枝,量化,知识蒸馏等,另外一些则着重于高效的网络设计,比如MobileNet,ShuffleNet等。作者在分析输出的特征图的时候发现,其实有些特征图是比较相似的,如下图所示,作者认为可以通过简单的变换得到。

-
提出能用更少参数提取更多特征的Ghost模块,首先使用输出很少的原始卷积操作(非卷积层操作)进行输出,再对输出使用一系列简单的线性操作来生成更多的特征。这样,不用改变其输出的特征图,Ghost模块的整体的参数量和计算量就已经降低了; -
基于Ghost模块提出GhostNet,将原始的卷积层替换为Ghost模块。
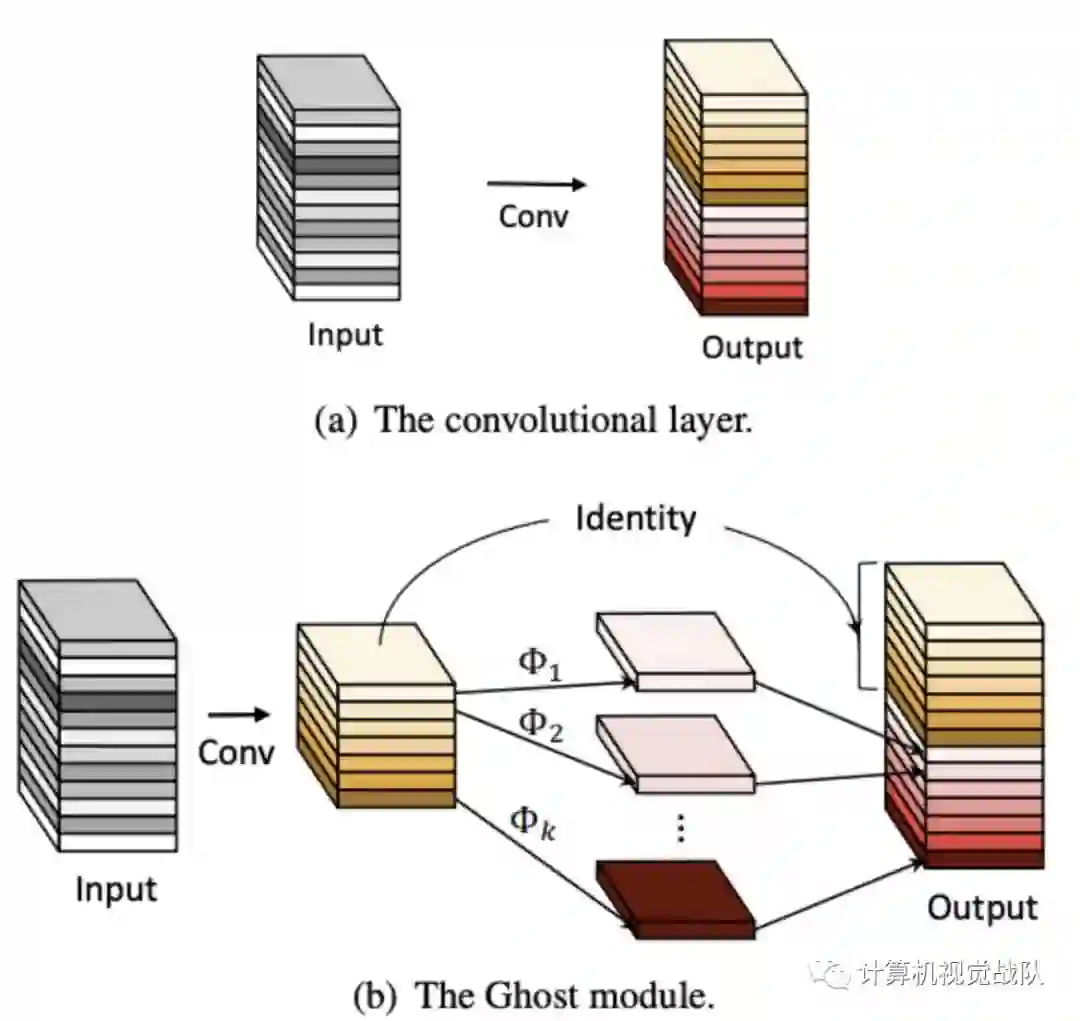
Ghost Module for More Features
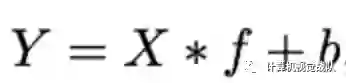
对于输入数据X∈ℝc×h×w,卷积层操作如上公式,Y∈ℝh′×w′×n为输出的n维特征图,f∈ℝc×k×k×nf为该层的卷积核,可得该层的计算量为n⋅h′⋅w′⋅c⋅k⋅k,这个结果一般较大,是由于n和c一般都很大。上面公式的参数量与输入和输出的特征图数息息相关,而从图1可以看出中间特征图存在大量冗余,且存在相似的特征(Ghost),所以完全没必要占用大量计算量来计算这些Ghost。
假设原输出的特征为某些内在特征进行简单的变换得到Ghost,通常这些内在特征数量都很少,并且能通过原始卷积操作如下公式获得,Y′∈ℝh′×w′×m为原始卷积输出,f′∈ℝc×k×k×m为使用的卷积核,m≤n,bias直接简化了:

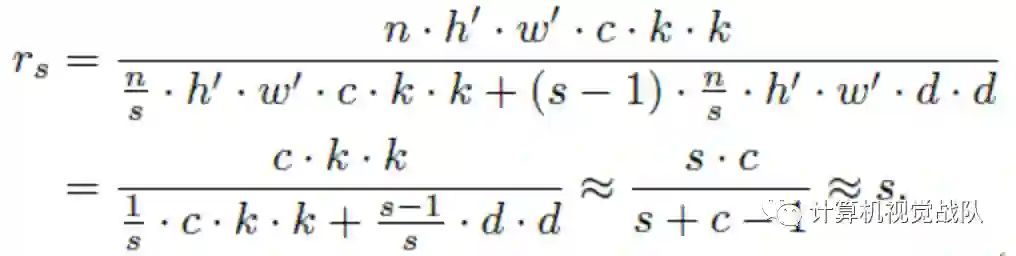
通过这么分析,可以体会到,其实GhostNet的方法也很简单,无外乎就是将原本的乘法变成了两个乘法相加,然后在代码实现中,其实第二个变换是用depthwise conv实现的。作者在文中也提到,前面的卷积使用pointwise效率比较高,所以网络嫣然类似一个mobilenet的反过来的版本,只不过GhostNet采用了拼接的方式,进一步减少了计算量。
class GhostModule(nn.Module):def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):super(GhostModule, self).__init__()self.oup = oupinit_channels = math.ceil(oup / ratio)new_channels = init_channels*(ratio-1)self.primary_conv = nn.Sequential(nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),nn.BatchNorm2d(init_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)self.cheap_operation = nn.Sequential(nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),nn.BatchNorm2d(new_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)def forward(self, x):x1 = self.primary_conv(x)x2 = self.cheap_operation(x1)out = torch.cat([x1,x2], dim=1)return out[:,:self.oup,:,:]
与目前主流的卷积操作对比,Ghost模块有以下不同点:
对比Mobilenet、Squeezenet和Shufflenet中大量使用1×1pointwise卷积,Ghost模块的原始卷积可以自定义卷积核数量;
目前大多数方法都是先做pointwise卷积降维,再用depthwise卷积进行特征提取,而Ghost则是先做原始卷积,再用简单的线性变换来获取更多特征;
目前的方法中处理每个特征图大都使用depthwise卷积或shift操作,而Ghost模块使用线性变换,可以有很大的多样性;
-
Ghost模块同时使用identity mapping来保持原有特征。
下图是Ghost bottleneck结构图,很类似resnet结构,不同的是channel是先升维再降维。
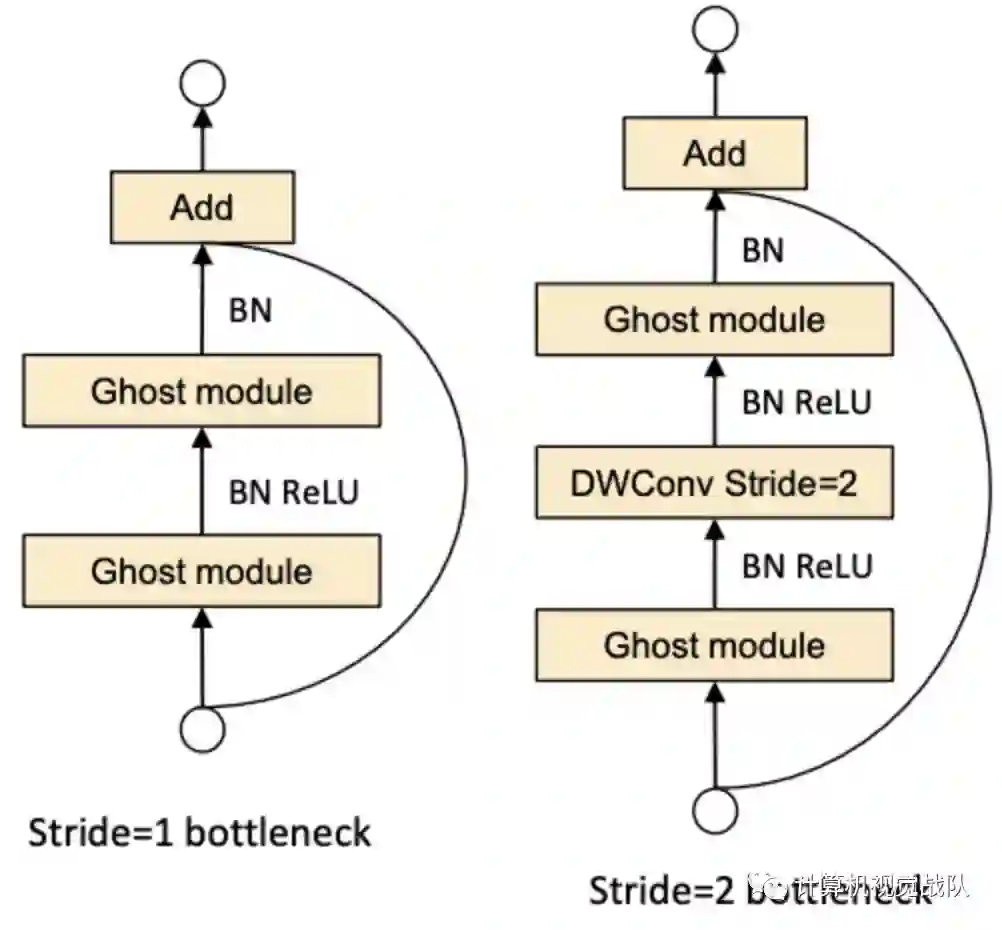
Ghost Bottleneck(G-bneck)与residual block类似,主要由两个Ghost模块堆叠二次,第一个模块用于增加特征维度,增大的比例称为expansion ration,而第二个模块则用于减少特征维度,使其与shortcut一致。
G-bneck包含stride=1和stride=2版本,对于stride=2,shortcut路径使用下采样层,并在Ghost模块中间插入stride=2的depthwise卷积。为了加速,Ghost模块的原始卷积均采用pointwise卷积。
下面是GhostNet的网络结构图,可以看到channel控制的比较小,并且引入了SE结构。
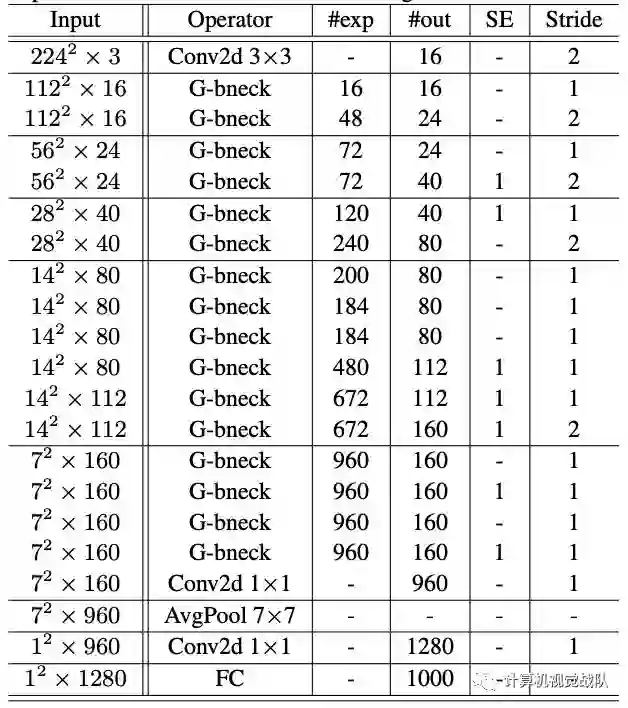
实验
作者首先采用控制变量法,测试不同的s以及d的效果。经过测试发现在s=2,d=3的情况下模型表现较好。
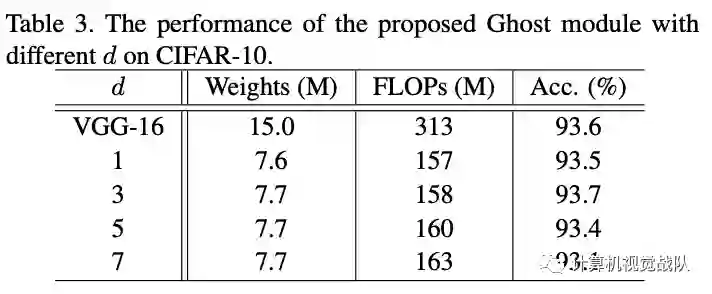
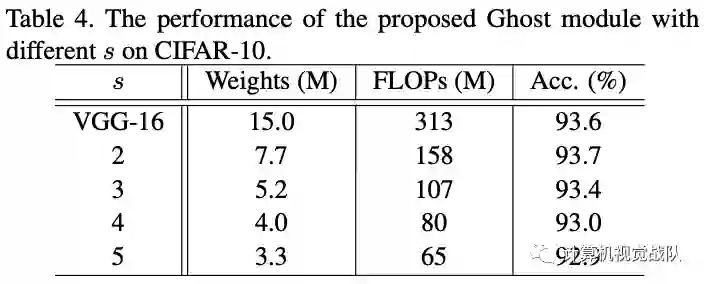
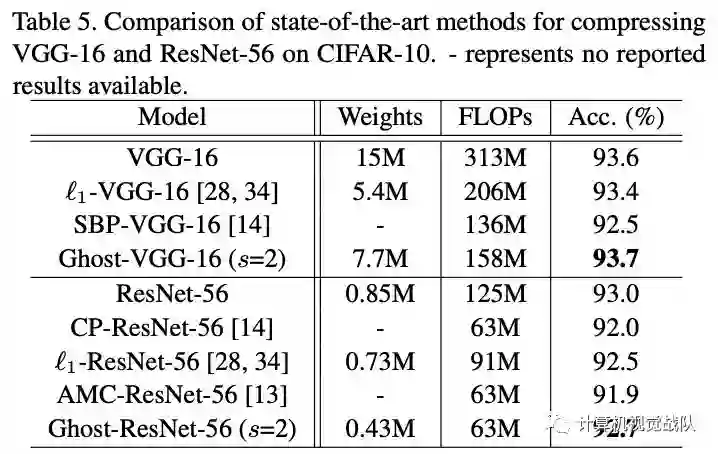
可以看到使用Ghost模块不仅比其它压缩方法更能降低模型的体量,也最能保持模型准确率:

The feature maps in the 2nd layer of Ghost-VGG-16. The left-top image is the input, the feature maps in the left red box are from the primary convolution, and the feature maps in the right green box are after the depthwise transformation.
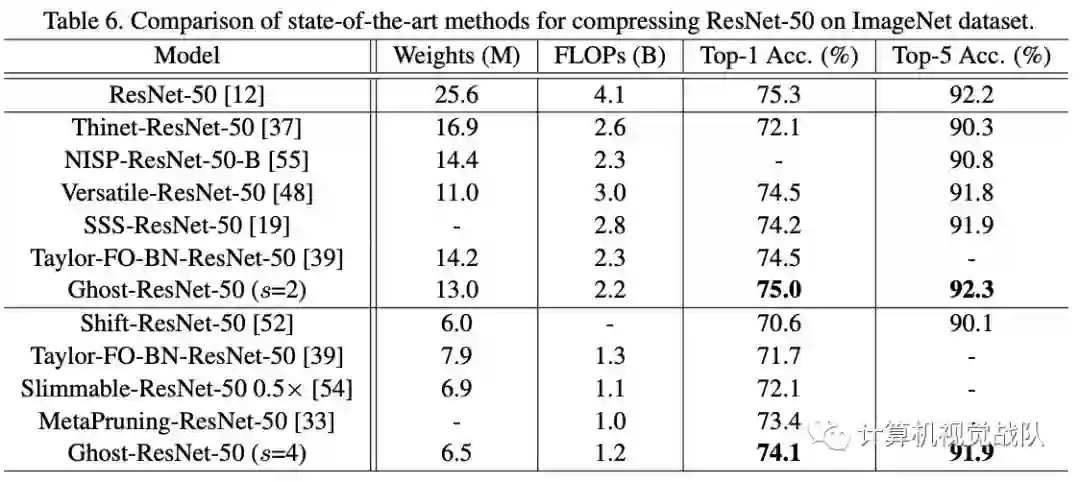

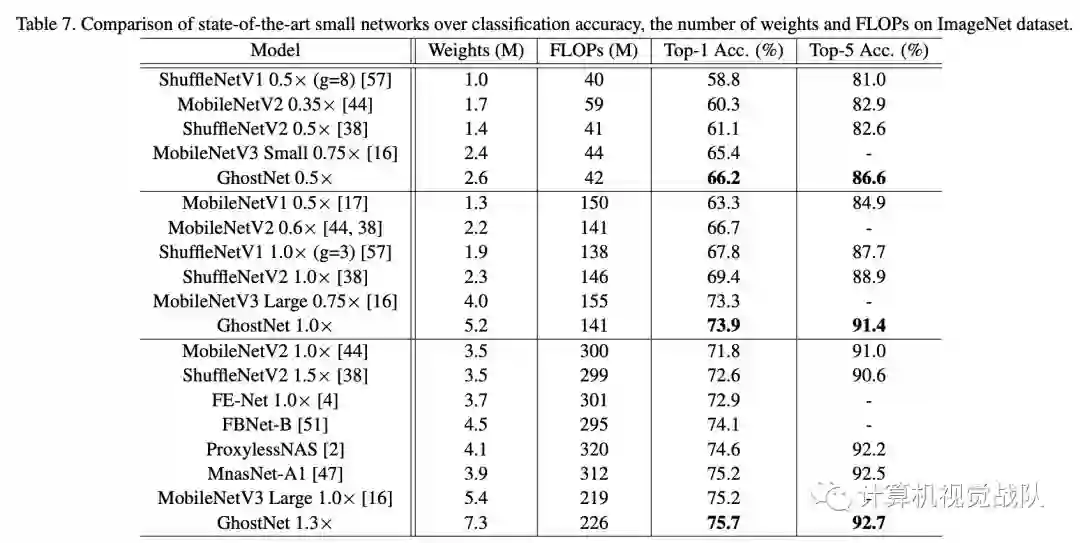
ImageNet效果对比:

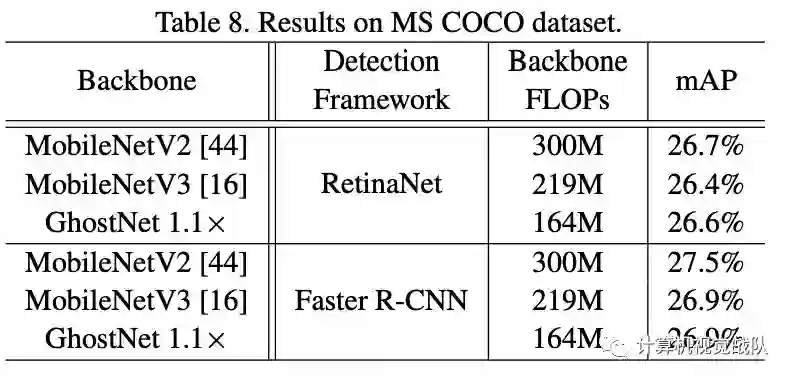
目标检测的效果:
小结
为了减少神经网络的计算消耗,论文提出Ghost模块来构建高效的网络结果。该模块将原始的卷积层分成两部分,先使用更少的卷积核来生成少量内在特征图,然后通过简单的线性变化操作来进一步高效地生成ghost特征图。从实验来看,对比其它模型,GhostNet的压缩效果最好,且准确率保持也很不错,论文思想十分值得参考与学习。
论文地址:https://arxiv.org/pdf/1911.11907.pdf
通知
计算机视觉战队正在组建深度学习技术群,欢迎大家申请加入!
如果想加入我们“计算机视觉研究院”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。

登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文