性能超越谷歌MobileNet!依图团队提出新一代移动端网络架构MobileNeXt ,入选ECCV2020

新智元报道
新智元报道
编辑:白峰、梦佳
【新智元导读】AIoT的时代即将来临,移动端智能应用呈爆发式增长,但是大型神经网络在移动端的性能制约了AI在移动端的推广。最近,依图团队发表在ECCV的一篇论文,提出了新一代移动端神经网络架构MobileNeXt,大大优于谷歌的MobileNet、何恺明团队提出的ResNet等使用倒残差结构的模型,为移动端算力带来了新的突破。




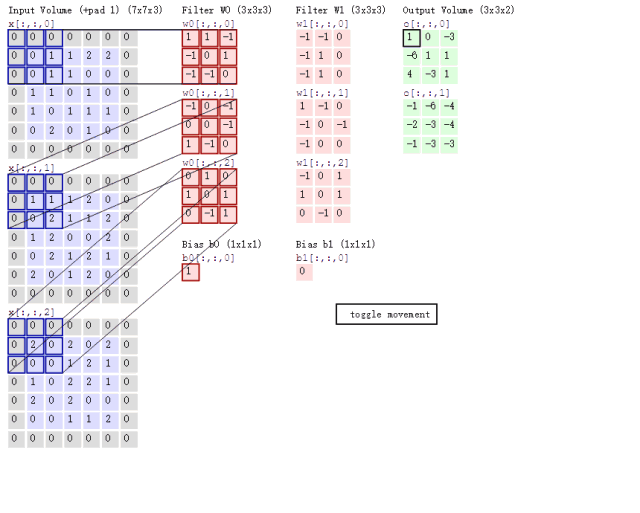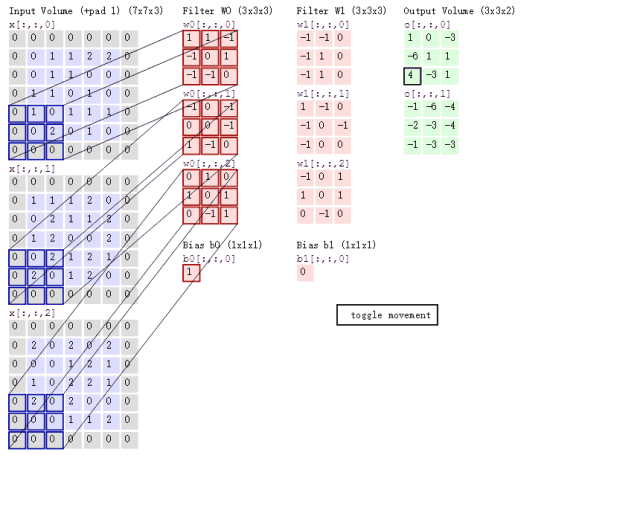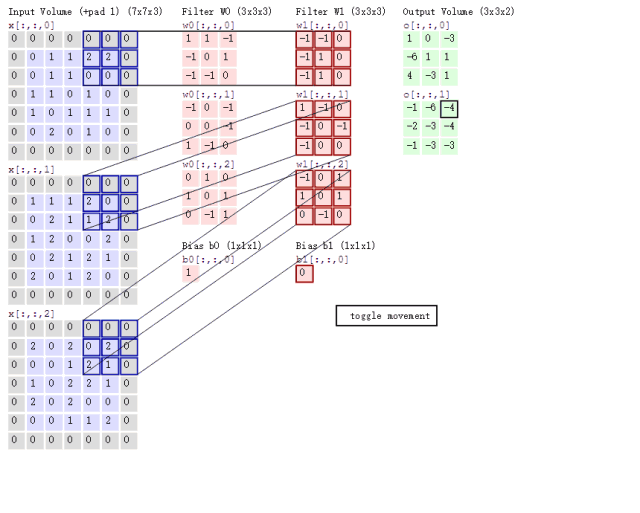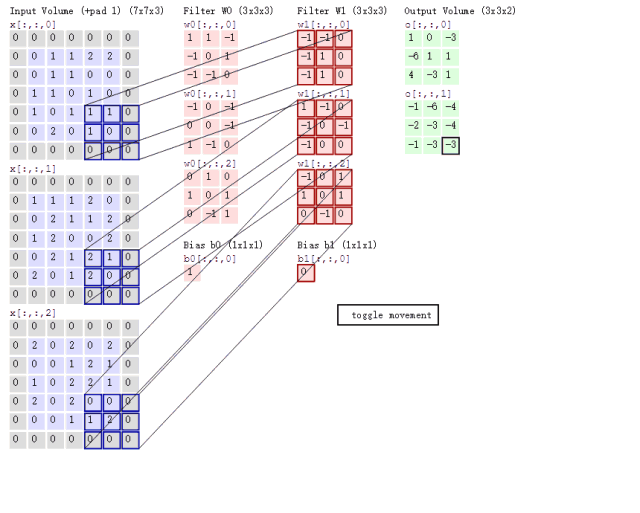
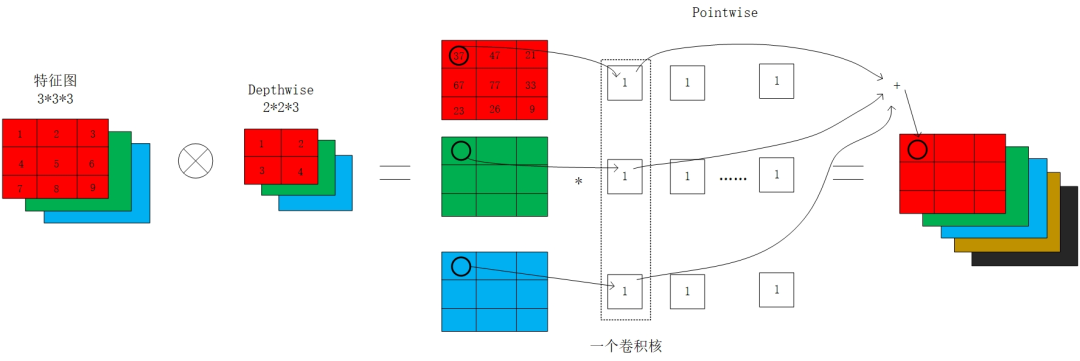
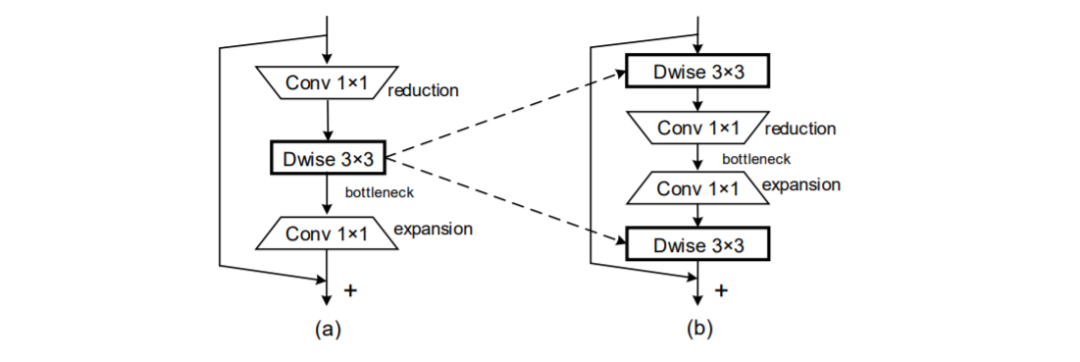
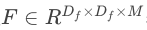 表示输入张量,
表示输入张量,
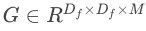 表示输出张量(注:此时尚未考虑深度卷积),那么该模块的计算可以写成如下形式,
表示输出张量(注:此时尚未考虑深度卷积),那么该模块的计算可以写成如下形式,
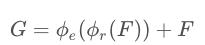
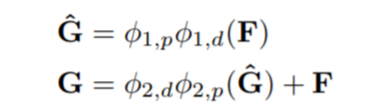

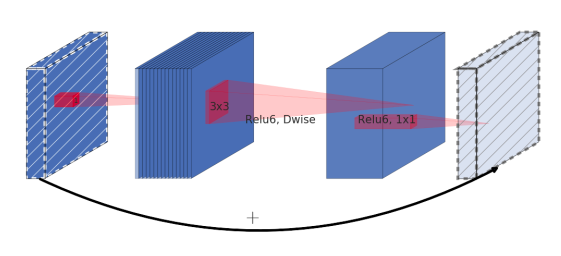
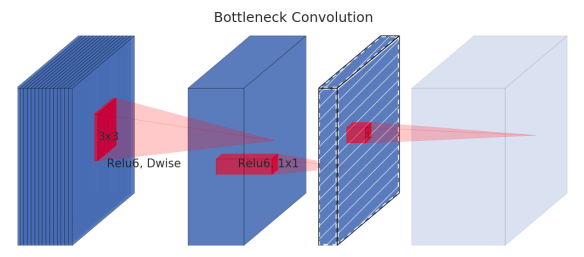
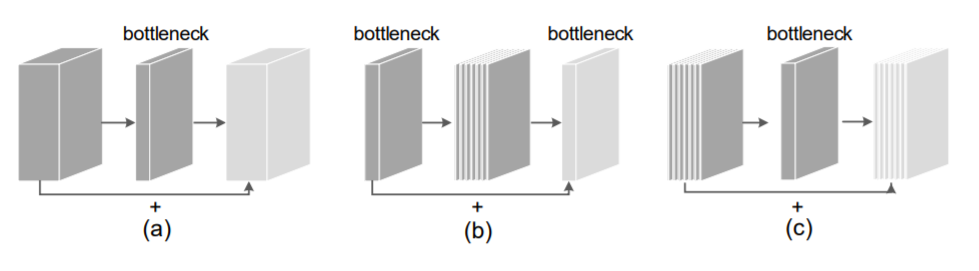
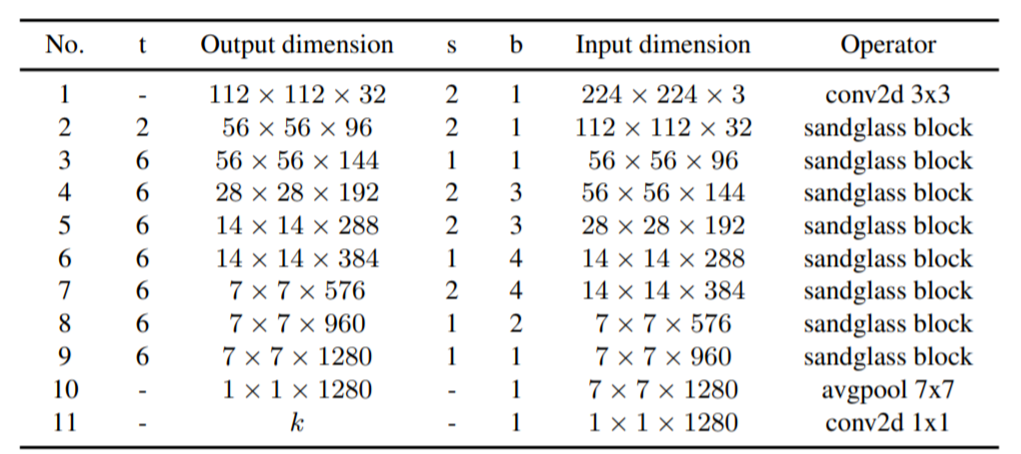 图五:依图团队提出的新的移动端网络架构
图五:依图团队提出的新的移动端网络架构
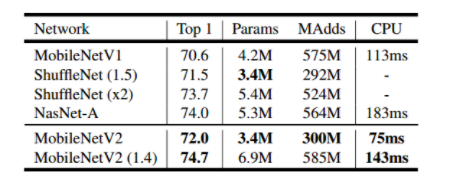
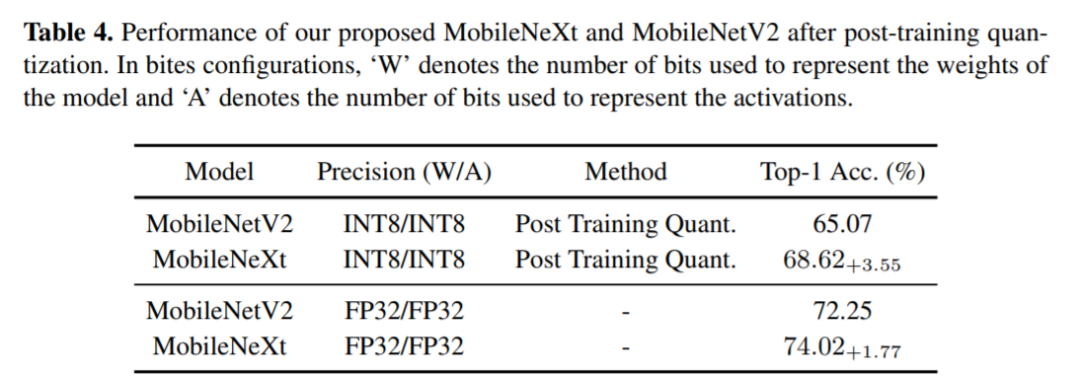
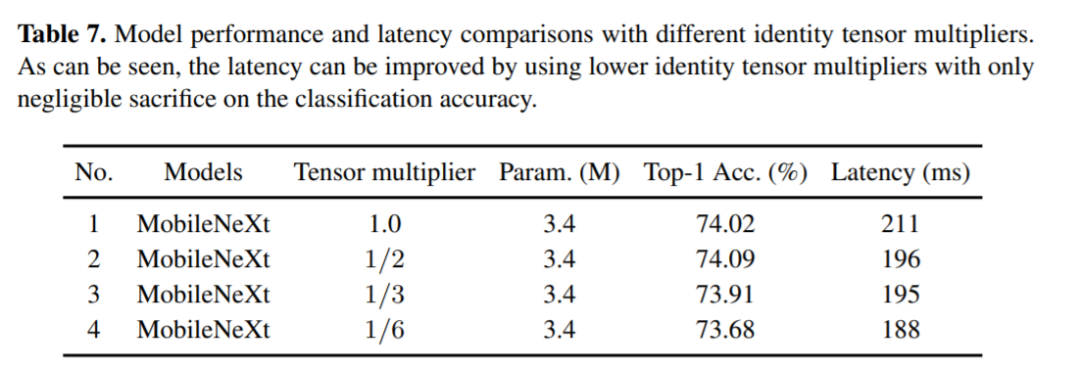
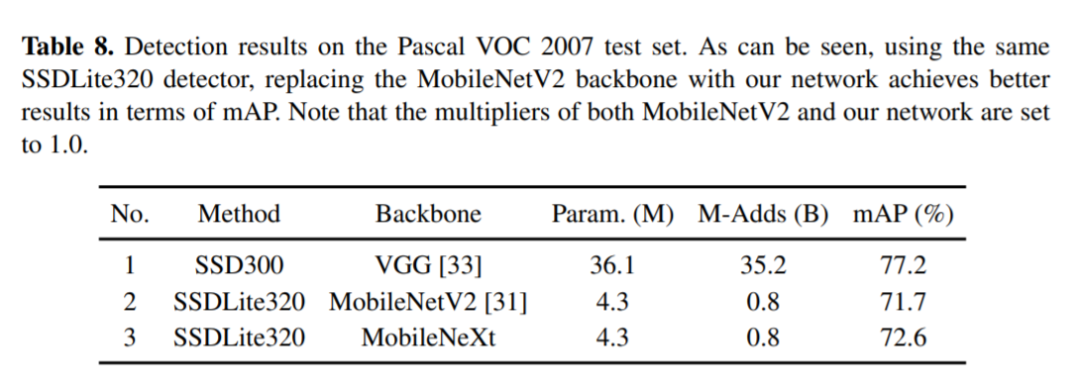
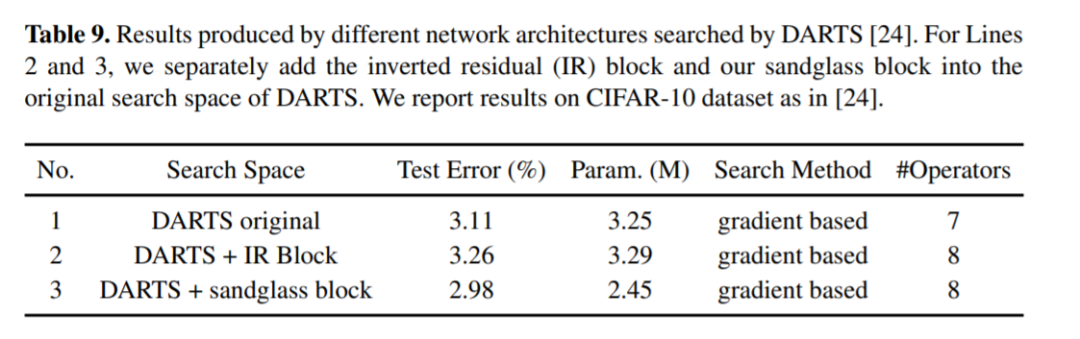
对标MobileNetV2,MobileNeXt参数更少精度更高
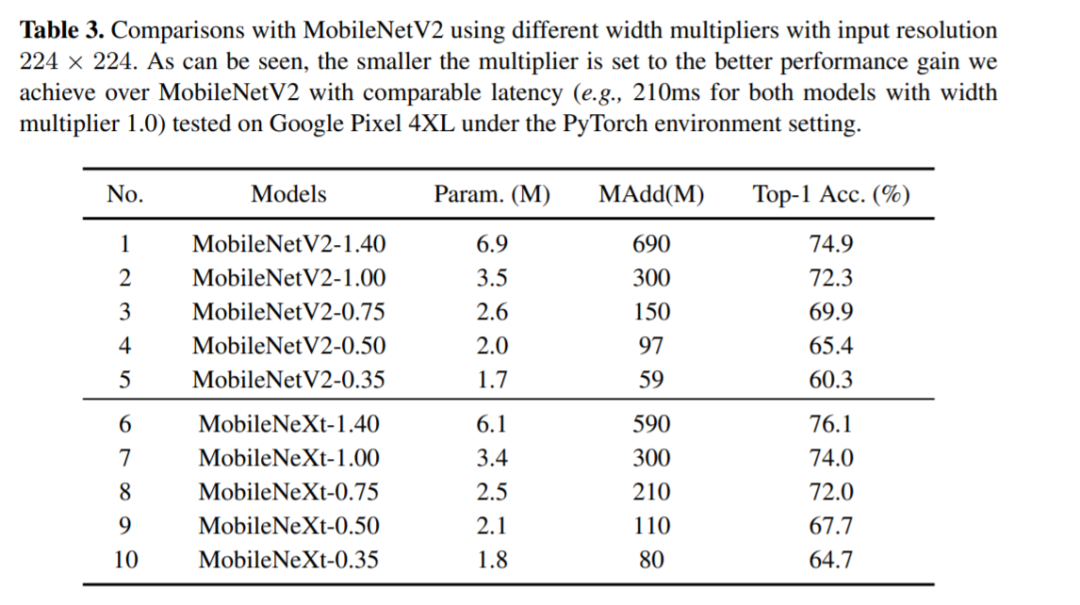 图六:与MobileNetV2 对比的实验结果
图六:与MobileNetV2 对比的实验结果


登录查看更多
相关内容
专知会员服务
27+阅读 · 2019年11月24日
Arxiv
7+阅读 · 2019年4月16日

相关VIP内容
专知会员服务
27+阅读 · 2019年11月24日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年4月16日