苹果官方首度发文披露脸部识别技术演变,乔布斯的“非成熟技术不用原则”贯穿始终
从 2007 年苹果推出第一部 iPhone 到现在已经十年了,回顾历年来的 iPhone 产品,其实很多新技术都并非首创。同时,苹果还会将较为成熟的技术搭载在最新产品上,以求给消费者较好的用户体验。
比如真正让 iPhone 成为业界标杆的触屏技术,其实早在 1999 年摩托罗拉就已经推出了搭载触屏技术的 A6188 ;还有从 iPhone 5S 开始使用的指纹识别技术,最先也由摩托罗拉在 2011年推出。

当年,乔布斯似乎为苹果定下了“非成熟技术不用”的原则,一方面为了照顾用户体验;而另一方面,他一直强势的认为一旦某一技术搭载在 iPhone 上,就必须成为业界典范。
而事实也的确如此。从普及智能手机到语音助理 Siri 、再到指纹识别、以及取消 3.5mm 耳机插孔,都在某种程度上设定了新的业界标准,使得其他手机厂商纷纷跟进。
现在,全新的 iPhone 8 及 iPhone X 已经上市,其面部识别功能 Face ID 无疑是一大亮点。和往常一样,这并不是一个全新的技术。
苹果早在 2013 年推出的 iOS 7 中其实就已经整合了相关的核心功能组件,而其中技术甚至可以追溯至 2001 年。但直到 2017 年,苹果才认为这项技术已经成熟,是时候搭载到最新的 iPhone 产品上了。

苹果机器学习开发团队于 11 月 16 日发表了一篇技术文章,主要介绍了 Vision 这个 API 背后所牵涉到的神经网络机制,以及最初如何靠简单的非神经网络算法,做出人脸识别的功能。
文章链接:https://machinelearning.apple.com/2017/11/16/face-detection.html
众所周知,iPhone X 中的 Face ID 功能利用人脸识别取代过去的指纹识别,在有效提升便利性之余,也凭借其基于机器学习的核心算法,以及对脸孔的 3D 扫描机制,确保手机能识别出真正的主人。且随着使用时间的增加,手机对主人脸孔的熟悉度也会跟着增加。
即便因为戴眼镜或者是口罩而识别不出,甚至是经过整容,但只要输入密码,手机就会把刚刚捕捉到的脸孔特征加进学习模型中,往后戴一样的眼镜或口罩时,手机还是可以认得你,不必担心会有被盗用等安全疑虑。
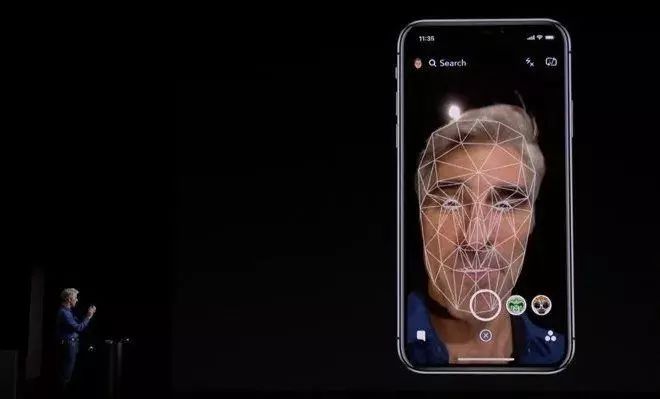
为了达到够高的识别正确率,苹果从算法到硬件设计可是花了很多心思。但这个过程可以回溯到 2011 年苹果在 iOS 5 上发表的一套图像识别框架 Core Image 身上。
虽然和 2004 年在 Mac OS X 上的 Core Image 名字完全一样,但内容完全不同,Mac OS X 上的 Core Image 主要就是用来作为图形处理使用,可在图形上实时套用一般图像处理软件可做到的特效滤镜。
苹果把 Core Image 搬到 iOS 5 上后,随着操作系统的改版也不断增加新功能,随着 2013 年的 iOS 7 的发布,苹果引进了 CIDetector 这个功能类,而其最重要的核心功能,就是用来进行面部识别。

但这时的面部识别并没有太大的商用价值,因为它只能识别是不是人脸,却无法从人脸特征认出本人。后来苹果转而在 2014 年投入深度学习研究,经过 3 年的时间,推出 OpenML 这个完整的深度学习生态,以及与之搭配的 Neuro engine 硬件 AI 处理单元,且推出首个基于硬件处理的手机深度学习应用 Face ID 。
Face ID 的雏形 CIDetector ,源自 2001 年
Core Image 演进到 iOS 7 ,其功能包含了 CIImage 、CIContex 、CIFilter 以及 CIDetecor ,而重点中的重点,就是 CIDetecor 这个功能类。
所以说,当 iOS 7 引入 CIDetecor 之后,基本上就具备了面部识别的能力,但各位可能会有疑惑,那怎么从 iOS 7 进展到 iOS 11 ,隔了这么久才使出 Face ID 这个大绝招?
既然是大绝招,当然前期练功运气的过程不可避免,且 iOS 7 所使用的脸部识别算法有很大的缺陷,苹果也认为要把这个技术用来做高精度的脸孔识别还为时过早。

实际上,iOS 7 中 CIDetector 的面部识别技术,使用了 Viola-Jones 这种基于简单特征的对象识别技术,此技术早在 2001 年就由 Paul Viola(目前就职于亚马逊) 及 Michael Jones(现供职于三菱电机研究实验室,MERL ) 两人共同提出。基于 AdaBoost 算法,使用 Haar-like 小波特征(简称类 haar 特征,是一种用来描述图像的数字特征)和积分图方法进行人脸检测。

虽然这两人并非是最早使用并提出小波特征的研究者,但是他们设计了针对人脸检测更有效的特征,并对 AdaBoost 训练出的强分类器进行级联。这可说是人脸检测史上里程碑式的一笔,也因此当时提出的这个算法被称为 Viola-Jones 算法。
毫无疑问,对于 2001 年计算机还不是那么普及的时代背景下,能够创造出针对人脸的识别算法虽有其开创性的意义,但是该算法太过粗糙,采用的特征点数量太小,因此容易造成误判,或者是被干扰的状况。
也因为这个问题,苹果不敢贸然把脸部识别的功能放到产品中,毕竟误判率太高,对产品的使用体验会是严重伤害。

但还是有不少“勇敢”的厂商直接把这种脸部识别技术做到产品中:比如微软的 Surface 平板,以及三星的 Galaxy 手机和平板,早在 2016 年就先后强调其集成在产品中的脸部识别功能。
理所当然,其识别出错机率高不说,只要拍张账号所有人的脸部照片,就可以打印出来让机器识别,并可认证通过 —— 可以想象,这样的安全性表现,自然过不了苹果对产品要求的基本门坎。
但到了 iOS 8 ,CIDetector 这个功能类又增加了针对条形码、物体形状以及文本的识别能力,用的都还是同一套计算逻辑。人脸识别的功能依旧保留,但只用在非关键的照相或者是图片处理上,并且通过 GPU 加速来增加其识别效率。
在这时,CIDetector 的人脸识别功能最主要是用来判断“是不是人脸”,而不是判别出“这是谁的脸”,离现在的 Face ID 功能还有相当遥远的距离,反而在条形码判读方面的应用还比较广,而其对象识别能力,亦逐渐被用在 AR 功能上。

无论如何,可以见得苹果对于新兴技术的运用相当谨慎。不久前,苹果现任 CEO 蒂姆·库克 ( Tim Cook )接受采访时被问及:“如何看待很多人认为苹果在 AI 领域正在落后于谷歌、微软、亚马逊等公司?”的时候,他的回答是:“不仅仅是人工智能,其他方面也是一样。大家经常把我们正在卖的东西跟别人规划的东西做比较。很多人卖的是概念,他们有他们的理由,我没有批评谁的意思,只是我们不这么做。”
"消费者是不会在意整合进产品的机器学习技术,他们甚至都不知道这种技术的存在。而恰恰是有了机器学习,iPhone 的电池续航时间更长。其实 iPhone 里有一大堆东西都会让你感觉 —— 哦,原来那也是机器学习啊。我们从来不觉得需要告诉消费者我们的产品里有哪些用到了机器学习,因为这不是消费者最关心的。我们关心,因为我们在技术领域工作,但用户不在乎,他们只在乎好不好用。"蒂姆·库克说。
云端 AI 牵扯到隐私问题,苹果转而寻求终端解法
到了 2014 年,苹果看到深度学习在大型计算平台上的应用已经越来越成熟,进而想到了逐渐实用化的深度学习在移动平台应该同样有着极高的应用潜力,研发人员产生了一个想法:如果把深度学习放在手机上,那是不是可以做到更酷炫、更精确的识别功能?
然而,理想很丰满,现实很骨感。先不论现在的手机已经逐渐集成用来处理 AI 计算的专用处理单元,比如说华为在麒麟 970 使用的 NPU ,2014 年的手机芯片计算性能非常羸弱,不堪作为深度学习的视觉模型计算平台。

当时行业里如果要做到 AI 功能,通常都是通过云端 API 提供相关的深度学习方案。如果使用基于云的深度学习方案,那么诸如脸孔识别,就可以通过手机收集脸孔图像,然后发送至云端来进行学习以检测人脸。
这些基于云的服务通常使用强大的桌面级 GPU 架构,并且同时使用了庞大的内存。通过这些云服务设备,手机这样的终端也能使用深度学习来解决问题。
但这又产生了另一个问题,苹果的 iCloud 受到严格的隐私与数据使用限制,所以 iCloud 上虽然存在庞大的照片数据,但这些数据都不能被用来进行深度学习。
理论上发送到 iCloud 的照片和视频都会再发送到云存储设备前先经过加密,并且只能通过注册到 iCloud 的账户来进行解密,所以,要进行深度学习,苹果只能选择在手机上直接进行相关计算,而不是在云端处理。
也正因为此,挑战就来了:要在 iPhone 上进行深度学习,就必须占用相当庞大且珍贵的 NAND 存储空间,且学习时必须将整个数据库都加载到内存中,并且耗用大量的 CPU 或 GPU 计算能力。
另外,与基于云计算的服务不同,云计算的资源只需要专注于视觉问题,反观终端设备上的深度学习计算必须与其它正在运行的应用程序共享系统资源。
最后,这些计算必须获得足够高效的处理,要能在相当短的时间内处理庞大的照片库,且不能带来显著的功耗或热量增加。
用 OverFeat 深度学习算法取代传统 Viola-Jones 的特征识别方式
2014 年,苹果的研发人员开始探讨如何通过深度学习来检测图像中的人脸时,深度卷积网络( DCN ) 其实才刚刚开始在物体检测上有所发挥,并产生相当可靠的结果。
而 DCN 算法中,最突出的是一种名为“ OverFeat ”的作法,靠由相对简单的逻辑,可以达到相当有效且可靠的图像描绘结果。
研发人员使用了基于 OverFeat 论文中的见解来架构最初的 Face ID 里面的人脸识别算法,并以之建立了一个完整的卷积网络,靠以达成两个任务目标:
使用二进制分类来预测输入数据中脸部的存在与否;
预测边界框架的参数回归,靠以更好的定位输入中的脸部数据。
研究人员使用了几个训练这种网络的方法:
最简单的训练过程是创建一个固定大小图像块的大数据集,该图像对应网络的最小单一有效输入,靠以优化整个网络算法的多任务目标计算能力。
训练的数据集代表了理想状态下的学习判读过程,研发人员靠此判断整个网络的计算潜力以及弹性,并针对更多不同的可能性来调整网络的参数。
而训练完毕之后,网络就能够预测任一图像中是否包含了人脸,如果判断为是,那它还能指出人脸在图像中的坐标和比例。
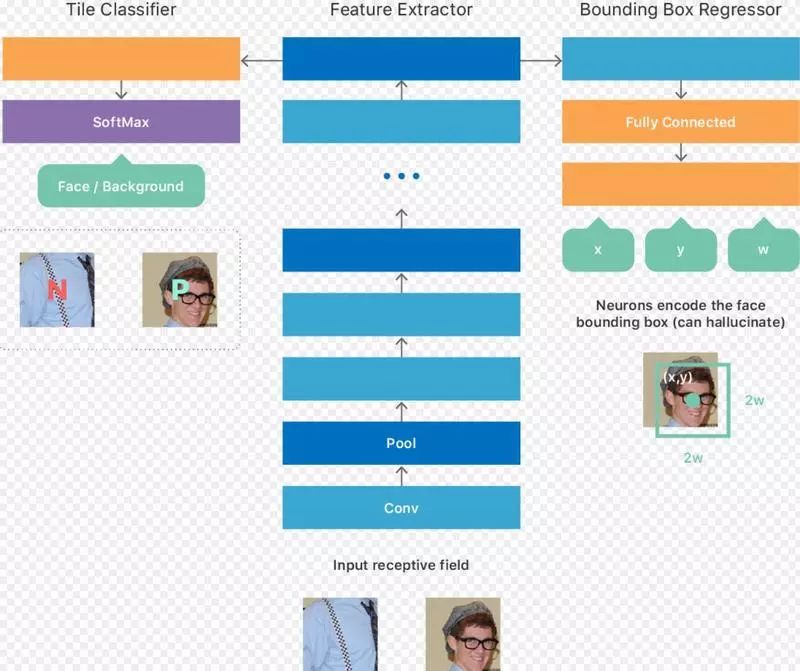
由于网络是完全卷积的,所以能够高效的处理任意大小的图像,并且生成 2D 输出对应地图。而对应地图上的每个点都可对应到输入图像中的任何区块,而这些点也包含了来自网络中,对于该图块是否存在人脸以及该人脸在图块中的相对位置和比例的预测。
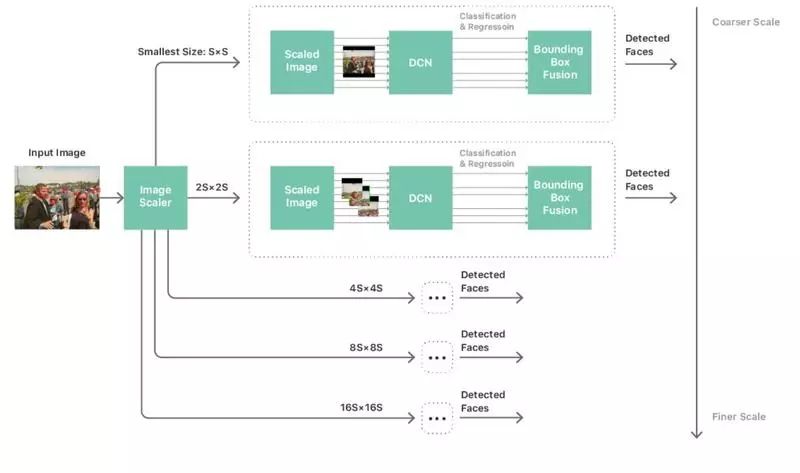
当我们完整定义网络后,就可建立标准的处理流水线来执行人脸检测,这个流水线里面包含了多尺度的图像金字塔、人脸检测器以及后处理模块等三大部分。
多尺度的金字塔主要是用来处理各种尺寸的脸孔。当收集到脸孔数据,我们把网络应用到金字塔的每个不同尺度级别,并从每一层收集候选检测资料。
后处理模块则是用来把这些检测结果跨度进行组合,靠以产生对网络映对图像中,脸部检测的最终预测边界框的列表。
打造基于深度学习计算的 OpenML ,创造人脸识别的基础平台 Vision
虽然苹果过去为其终端设备设计了不少针对图像处理的 API ,但这些基于旧时代逻辑的 API 其实已经无法很好的应对未来复杂应用的计算需求了,而因为深度学习的应用不论在云端或者是终端已经是不可避免的趋势,所以苹果研发人员推出了 OpenML 这个深度学习开发环境,以及 Vision 这个针对深度学习优化的图像成像信道。
凭借 Vision ,开发人员大部分的基本图形操作可以自动完成。另外,在内存耗用以及功耗表现方面,尤其是流媒体,以及图像捕捉过程,内存的占用过去一直是个悬而未决的问题。
随着摄影镜头的照相解析能力越来越高,其所能捕获的图像质量以及容量需求也不断增加。研发人员通过部分二次采样解码以及自动平铺技术来解决内存占用过高的问题,因此,机器视觉可以被应用到各种图像中,即便是全景照片这种非常规高宽比的大型图像也能顺利工作。
Vision 也能妥善且有效率的使用中间体来优化图像识别的工作。诸如人脸识别,或者是人脸标志检测的工作都可以通过相通的中间体来加以处理。研发人员把相关算法的接口抽象出来,找到要处理的图像或缓冲区的所有权位置后,Vision 就可以自动创件以及缓存中间图像,靠以提高相关的视觉任务计算性能。
师徒制神经网络训练法解决过高的系统资源占用问题
Vision 的人脸检测工作也需要大量的 GPU 计算,但 GPU 本身是一种相当耗电的架构,且计算过程中也会占用一定的内存空间。为了减少内存的占用,研发人员通过分析计算图来分配神经网络的珠间曾,靠以让多个图层能够对应到同一个缓冲区。
这个技术能够减少内存占用,且不会明显影响性能,并且可在 CPU 或是 GPU 上进行处理,兼顾了效率和弹性表现。

为了确保深层神经网络在后台运行时,前台的系统操作流畅性仍能维持一致,研发人员更将网络的每一层分割 GPU 工作,直到每个工作线程的占用的 CPU 时间都少于 1 毫秒,让操作系统可以快速将应用情境切换到优先级更高的任务上,比如说 UI 动画的处理,靠以确保使用者得到的使用体验仍能维持一致。
研发人员虽靠由 Vision 建立起基本的神经网络。然而网络复杂度和规模仍是要把这个网络放到计算资源有限的终端设备上的最大挑战。为了克服这个挑战,研发人员必须把网络限制在相对简单的拓朴结构中,而且网络层数、信道数量以及卷积滤波器的内核大小也要受到限制。
这是个两难的问题,如果网络规模太小,那就不足以构成可以快速判断图像的流水线;太大,性能又会受到手机硬件的计算性能限制,导致反应迟缓,且功耗和发热会严重影响使用体验。
事实上,不论怎么尝试,当时要把整个神经网络搭载到仅仅只有 1GB 的手机内存,可说是完全不可能的任务。
研发人员最终采用了类似“师生”的培训方法。也就是使用 1 个具有完整规模的“大师”网络,以之来训练另 1 个较小,且层数较少的“学生”网络,靠由这个训练,最终只具备简单卷积网络结构的学生网络,也能呈现出极为接近大师网络的识别结果。最终,把神经网络放到手机上的计划终于获得实现。
结合 Neural Engine 芯片,GPU 和 CPU 更可专注于使用体验的改善
开发了 3 年的 Vision 成为苹果在今年的 WWDC 发表泛用 AI 的机器学习框架 OpenML 的重要部件之一。而除了 Vision 以外,还加入了用于协助自然语言处理的 Fundation 、及让游戏开发商可以在游戏中导入 AI 的 GameplayKit 等三大应用框架,这些开发环境也都用上了深度学习技术。

虽然通过 OpenML 可以妥善利用 GPU 和 CPU 的计算性能,达到不错的深度学习性能,但苹果并不满足于现况,并认为要达到最好的使用体验,就必须加入专用的深度学习硬件。
这么一来不但可以增加神经网络的规模、强化识别的正确性,同时也不会造成系统的延迟,而这也就是苹果为何要与 Vision 同步研发 A11 内建 Neuro Engine 的主要原因。
凭借 Neuro Engine ,所有深度学习相关的工作都可通过这个专属的核心来进行处理,CPU 和 GPU 可以专注进行前台任务,不会被后台的任务所干扰,比过去所有的架构都更有效率,使用此计算架构加速的 Face ID ,也表现出极高的识别速度以及正确性。
Neural Engine 可做到 6 亿次 / 秒的操作效率,也就是 0.6 TOPS ,在其功耗限制的条件下能做到这样的效能输出,其实已经算是业界数一数二了。
而作为苹果软硬生态未来不可缺的一部份,Neural Engine 也将会在整个苹果终端的开发环境中占有非常重要的地位,不仅是目前的图像识别或脸孔识别工作,未来在 AR 或 VR 图像的绘制或迭加到真实世界的处理,肯定都会发挥其增进深度学习计算效能,并优化整体系统功耗表现,靠此更加强化苹果在相关应用的使用体验。
责任编辑:李雨侬

点击下方图片即可阅读

恒生电子研发中心总经理章乐焱:“全领域”金融软件企业的 Fintech 探索之路





