入门 | 单样本学习:使用孪生神经网络进行人脸识别
选自towardsdatascience
作者:Firdaouss Doukkali
机器之心编译
参与:Nurhachu Null、刘晓坤
这篇文章简要介绍单样本学习,以孪生神经网络(Siamese neural network)进行人脸识别的例子,分享了作者从论文 FaceNet 以及 deeplearning.ai 中学到的内容。

图片来自 pixabay.com(https://pixabay.com/)
如果你对这个主题很感兴趣并希望深入了解的话,可以参考论文:
FaceNet:人脸识别和聚类的统一嵌入(FaceNet: A Unified Embedding for Face Recognition and Clustering)。
让我们开始吧!
单样本学习
为了理解使用单样本学习的原因,我们需要讨论一下深度学习和数据。通常,在深度学习中,我们需要大量的数据,拥有的数据越多,结果就会越好。然而,仅从少量数据中学习会更加方便,因为并不是所有的人都拥有丰富的数据。
此外,为了识别一个对象,人脑也不需要成千上万张这类对象的图片。我们现在不谈论对人脑的模拟,因为它过于复杂和强大并且很多东西都与学习和记忆有关,例如感觉、先验知识、交互等。
这里的主要思想就是,我们需要仅仅从少量的数据中就能学会一个对象分类,这就是单样本学习(one-shot learning)算法。
人脸识别
在人脸识别系统中,我们希望通过输入一张人脸图片就能够识别对应的人的身份。而如果系统并没有成功地识别图片,是因为这个人的人脸图片并不在系统的数据库中。
为了解决这个问题,我们不能仅使用单个卷积神经网络的原因有两个:1)CNN 在小数据集上是不起作用的;2)如果每次向系统中加入一位新人的一幅图片时再去重新训练模型,也是极其不方便的。为此,我们在人脸识别中使用了孪生神经网络。
孪生神经网络
孪生神经网络的目标是寻找两个可比较对象的相似程度(例如,签名验证、人脸识别等)。这个网络有两个相同的子网络,两个子网络有相同的参数和权重。
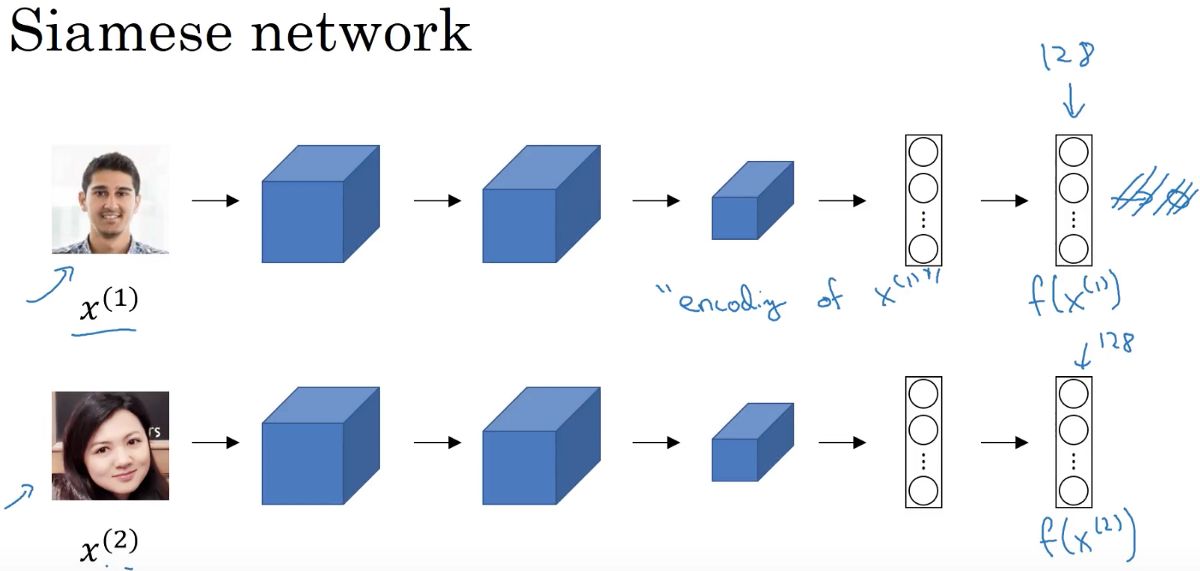
图片来源于 C4W4L03 Siamese Network(https://www.youtube.com/watch?v=6jfw8MuKwpI),感谢 Andrew Ng。
上图是 deeplearning 中利用孪生网络架构做人脸识别的例子。正如你所看到的,第一个子网络的输入是一幅图片,然后依次馈送到卷积层、池化层和全连接层,最后输出一个特征向量(我们并没有使用 softmax 函数来做分类)。最后的向量 f(x1) 是对输入 x1 的编码。然后,向第二个子网络(与第一个子网络完全相同)输入图片 x2,我们对它做相同的处理,并且得到对 x(2) 的编码 f(x2)。
为了比较图片 x(1) 和 x(2),我们计算了编码结果 f(x1) 和 f(x2) 之间的距离。如果它比某个阈值(一个超参数)小,则意味着两张图片是同一个人,否则,两张图片中不是同一个人。
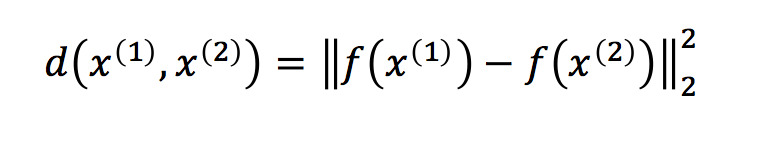
上式是 x1 和 x2 的编码之间的距离。
这适用于任何两张图片。
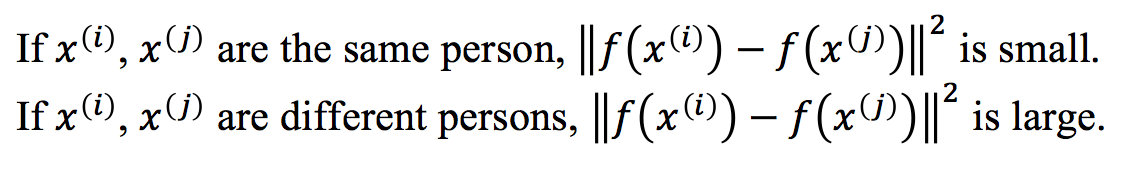
那么,为了得到对输入图片的良好编码,我们如何学习相应的参数呢?
我们可以在三重损失函数上应用梯度下降,所谓三重损失函数指的是使用三幅图片计算一个损失函数:一副固定影像 A,一副正例图像 P(与固定影像是同一人),以及一张反例图像 N(与固定影像不是同一人)。所以,我们想让固定影像 A 与正例 P 的编码之间的距离 d(A,P) 小于等于 A 与 N 的编码之间的距离 d(A,N)。也就是说,我们要让同一个人的图片更加相互接近,而不同人的照片要互相远离。
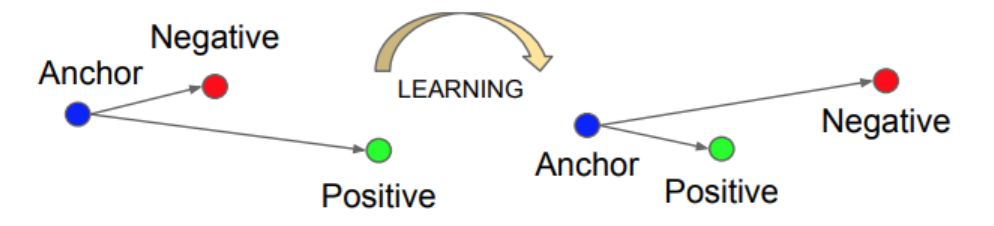
三重损失将固定影像 A 与正例 P 之间的距离最小化了,这两者具有同样的身份,同时将固定影像 A 与反例 N 之间的距离最大化了。来自论文《FaceNet: A Unified Embedding for Face Recognition and Clustering》。
这里的问题是,模型可能学习给不同的图片做出相同的编码,这意味着距离会成为 0,不幸的是,这仍然满足三重损失函数。因为这个原因,我们加入了边际α(一个超参数)来避免这种情况的发生。让 d(A,P) 与 d(N,P) 之间总存在一个差距。
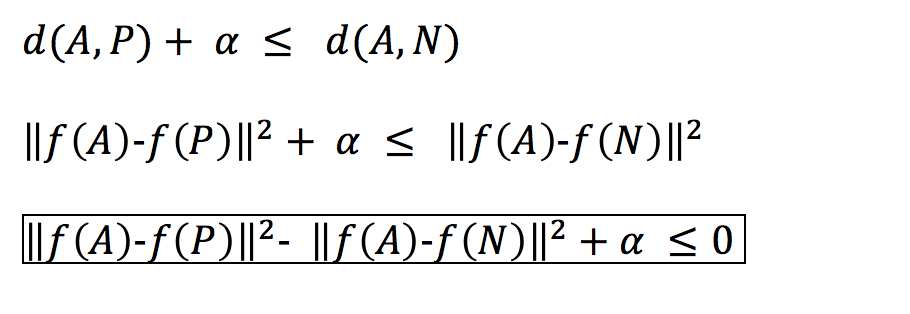
三重损失函数:
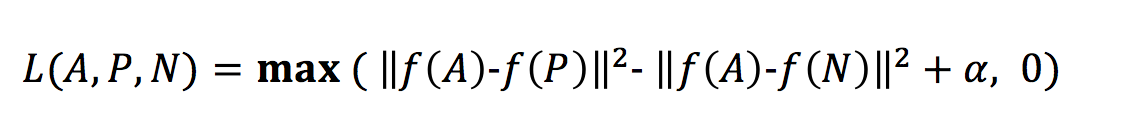
这里的最大化处理意味着只要 d(A, P)—d(A, N)+ α小于等于 0,那么 loss L(A, P, N) 就会是 0,但是一旦它大于 0,那么损失值就是正的,这个函数就会将它最小化成 0 或者小于 0。
代价函数是训练集的所有个体的三重损失的和。
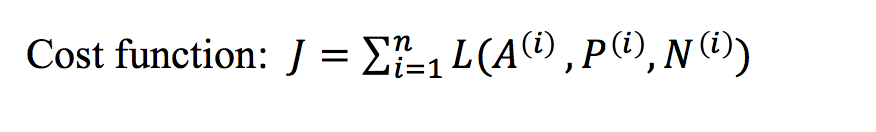
训练集
为了定义 A 和 P,训练集应该包含同一个人的多张图片,一旦模型训练完毕,我们就可以仅仅通过一张图片来识别出一个人。
我们如何选择用于训练模型的图片呢?
如果我们随机选择图片,可能很容易就能满足损失函数的限制,因为大多数情况距离都是很大的,而且梯度下降也不会从训练集中学到很多(大幅更新权重)。因为这个原因,我们需要寻找这样的 A、P 和 N,使得 A 和 P 很接近 N。我们的目标是让训练模型变得更加困难,以使得梯度下降学到更多。

原文链接:https://towardsdatascience.com/one-shot-learning-face-recognition-using-siamese-neural-network-a13dcf739e
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



