双非硕的毕设复盘:数据库篇

极市导读
本文为作者在完成毕业设计的经验总结,主要围绕数据库搭建和处理方面。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言:
这个周末趁着点闲功夫把之前毕设所做的工作进行复盘,整理后发现之前涉及到的工作很杂很乱,因此这篇博客仅记录自己开展数据方面的工作。
背景
本人的毕业设计是围绕电动车数据集进行电梯楼道间在线检测系统的搭建,总的项目共分为两大模块,一是上层电动车检测算法(python,基于YOLOv4和YOLOv5改进),二是下位部署框架(C++,基于rknn部署)。电梯楼道间电动车在线检测系统的构建,需要先构建好数据库,该数据库需满足业务场景的多样性,而课题构建数据库的方式包括了数据爬取和数据采集两种方式:
1、数据爬取
这是数据库构建最主要的工作之一,由于没有钱购买数据库,那么就得从零开始搭建数据集,而网络爬虫是最主要的方式。网络爬取数据通过借鉴网络爬虫脚本进行修改,对市面上常见的电动车进行调研,发现最常见的电动车品牌有雅迪、小刀、艾玛、绿源等,种类共包括电摩托、锂电池电动车、折叠电动车和脚踏电动车等,依次进行爬取,如下所示:
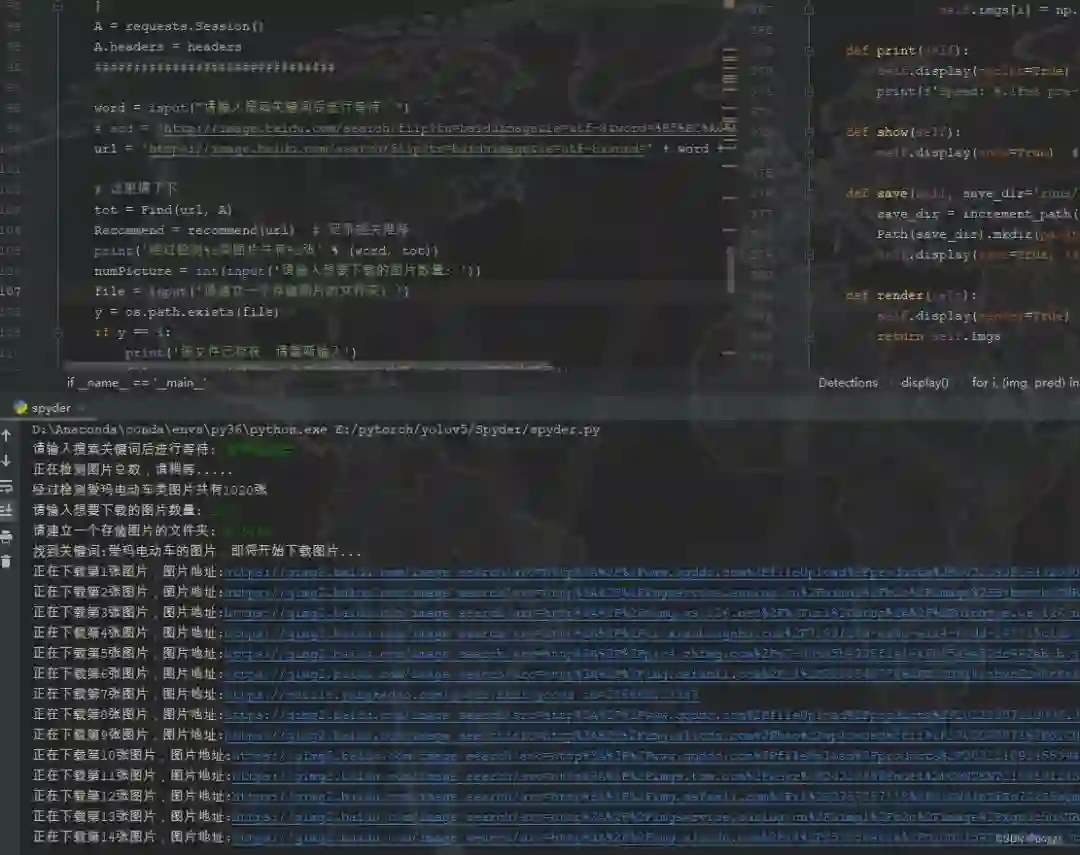
最终共获取到接近8000张左右的数据集,由于网页一般存在反爬机制,在摄取到一定量的数据后,脚本将不再获得新数据,另外爬取到的数据其实有很大重复性和无效性,需要通过以下几种方式进行处理:
-
拉普拉斯算子洗去模糊数据 -
opencv计算相似度矩阵删除重复数据 -
清洗掉一些失真、无法正常显示的图片
清洗后的数据大约还剩5000张左右,如下所示:

2、定点采集
这部分的工作其实是最难开展的,因为网络爬虫得到的图片大部分都缺少复杂背景,在模型训练时很难为模型增加有限抗燥源,因此在定点采集时需要尽可能多场景,多时段,多种类电动车进行采集,过程也是非常痛苦,该过程总历时接近两个月(不是每天都出工,看心情),该部分数据集无法进行展示,在毕设课题完成后已删除。
3、负样本
所谓的负样本其实是我们常说的背景样例或者易混淆样例,该部分数据集添加到数据库中以减少误报 (FP) 的发生。事实上,COCO数据集中有 1000 张背景图片左右的图片被当成负样本,接近1%左右,然而在实际项目生产中,可以根据模型的误检情况适当增多,如下所示:
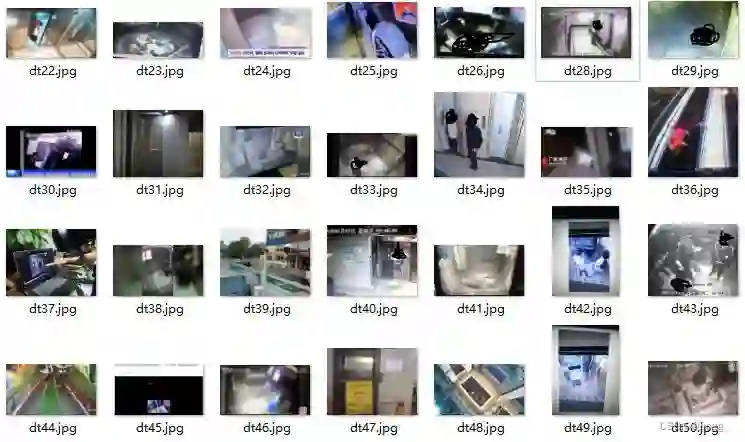
另外负样本不需要标签,也就是不需要标注,直接使用空的txt喂进网络即可。
4、半自动标注
起初数据库中共包含1万张左右的数据样本,光是标注都很吃力,实在不想在数据标注上浪费过多时间,在折腾了接近两天后果断放弃,而后去寻找一种更加高效的标注方式,半自动标注成为首选。这里推荐一个半自动标注的工具,叫做AutoLabelImg,链接:https://github.com/wufan-tb/AutoLabelImg该标注工具由LabelImg和YOLOv5结合的一款半自动标注工具,但该工具仅支持YOLOv5-v3.1版本,而在进行该毕设课题时,YOLOv5已经迭代到5.0版本,精度、速度、算力开销相对前几版都有提升,且本人自己也有开源repo在更新,因此花了一天时间对该工具进行了修改更新,而新版本支持YOLOv5-5.0版本以及YOLOv5-Lite版本的所有模型,由于原YOLOv5使用GPL-3.0 license开源协议,在复盘后本人也会将修改后的新版本放出。
4.1、环境准备
运行该工具所需环境满足以下两个条件即可:
-
沿用原始YOLOv5的环境即可 -
在1的条件下安装pyqt5
4.2、工具编译
因为本人是在Window环境下操作该工具,因此需要使用到以下命令,推荐使用git bash:
pyrcc5 -o libs/resources.py resources.qrc
而喜欢使用Ubantus的同志,则需要使用:
sudo apt-get install pyqt5-dev-tools
make qt5py3
4.3、工具包预览
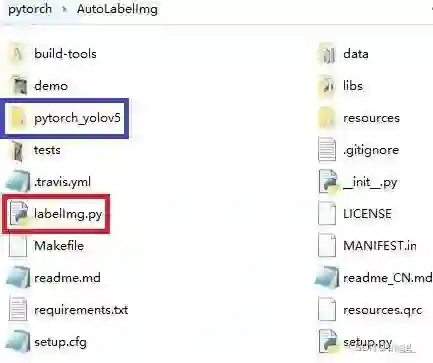
如上所示,最重要的文件包有两个,一个为pytorch_yolov5,(蓝框),一个为labelImg.py(红框),一个是后续需要配置的文件包,一个是主函数文件。
4.4、模型配置
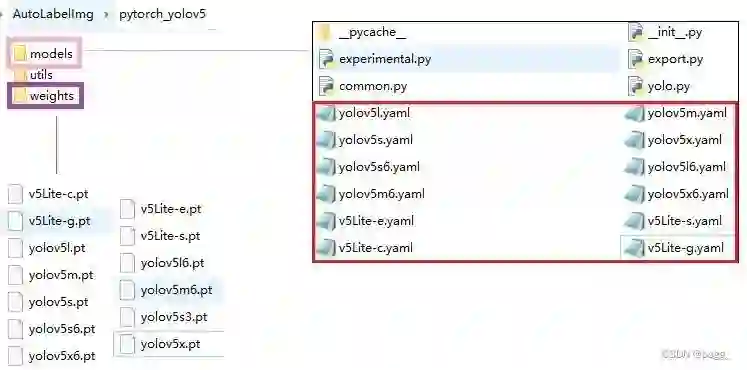
在pytorch_yolov5/models文件夹中添加xx.yaml模型网络文件,在pytorch_yolov5/weights中添加xx.pt训练权重。
4.5、数据标注
使用以下命令启动程序:
python labelImg.py
打开图片文件夹:
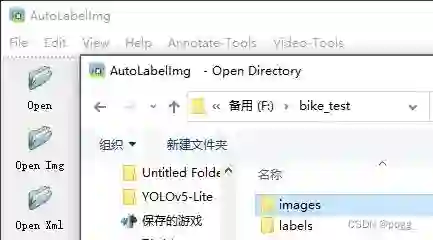
打开数据标注存放的文件夹:
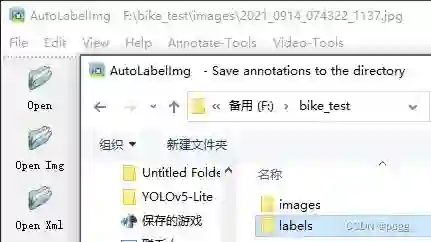
选择标注形式为YOLO格式(YOLOv3、YOLOv4、YOLOv5、YOLOv6、YOLOX),并选择自动标注功能:
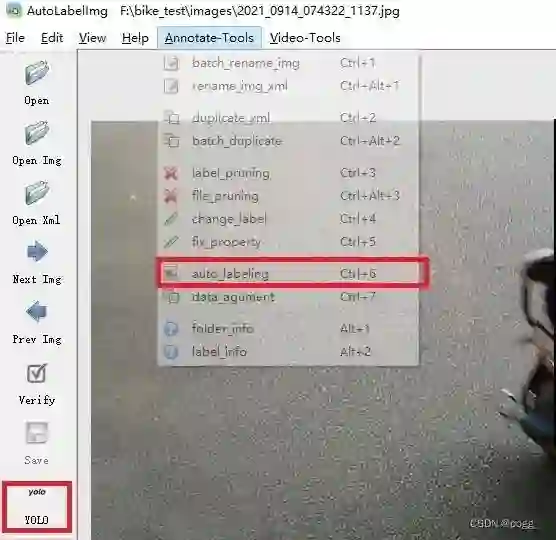
可选择你想要使用的模型进行标注:
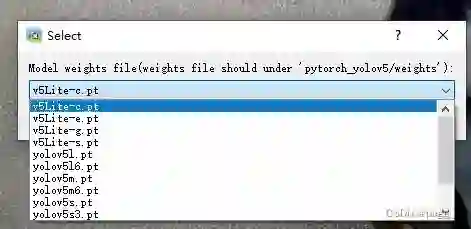
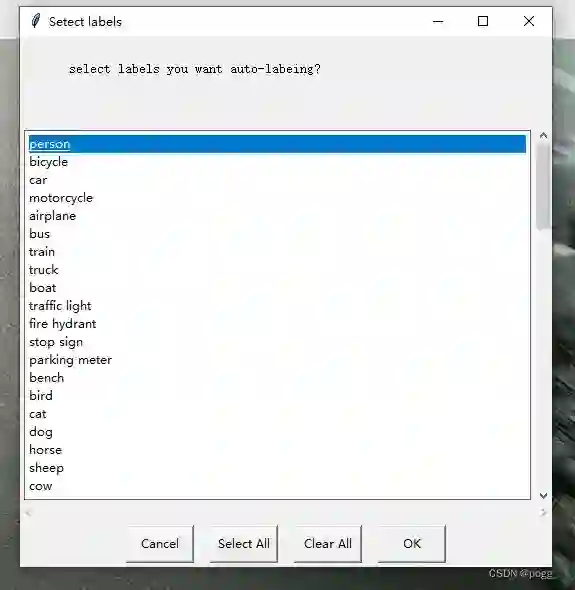
选择自动标注的类别,无脑Select All:
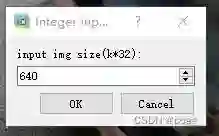
选择保存的图片尺寸,建议640:
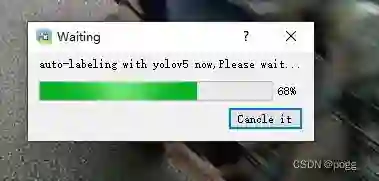
大约30秒标注完所有图片:
而后就是对数据的小修小补

4.6、复检误检消除
其实使用半自动标注工具还会出现一个物体重复出框,一些场景误检的情况,如下所示:
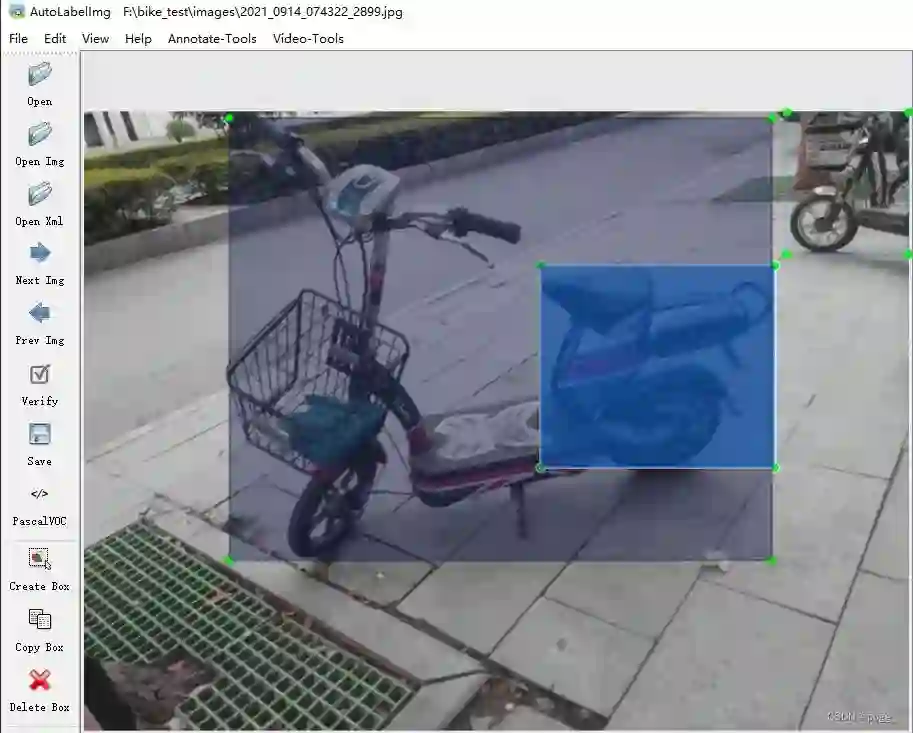
此时需要修改源码中labelimg.py的阈值进行卡段,可减少一定的工作量,如下:
def yolov5_auto_labeling(self):
# 使用yolov5进行半自动标注
try:
tree = ET.ElementTree(file='./data/origin.xml')
root=tree.getroot()
for child in root.findall('object'):
template_obj=child
root.remove(child)
tree.write('./data/template.xml')
#=====def some function=====
def change_obj_property(detect_result,template_obj):
temp_obj=template_obj
for child in temp_obj:
key=child.tag
if key in detect_result.keys():
child.text=detect_result[key]
if key=='bndbox':
for gchild in child:
gkey=gchild.tag
gchild.text=str(detect_result[gkey])
return temp_obj
def change_result_type_yolov5(boxes,scores,labels):
# 保存标注结果
result=[]
for box, score, label in zip(boxes, scores, labels):
if score>0.8: # 阈值卡断
try:
new_obj={}
new_obj['name']=label
new_obj['xmin']=int(box[0])
new_obj['ymin']=int(box[1])
new_obj['xmax']=int(box[2])
new_obj['ymax']=int(box[3])
result.append(new_obj)
except:
print('labels_info have no label: '+str(label))
pass
return result
在 change_result_type_yolov5函数值,将score分值调高,尽量得到高分值的分类目标,这在一定程度上可以减少工作量。文末附工具链接:(https://github.com/ppogg/AutoLabelImg)
5、总结
这是一篇关于复盘毕设的博客,仅涉及数据库构建和处理部分,数据确实是一个很头疼的问题,但开展工作请勿在数据上消耗过多时间和精力,另外标注工作应该是比较重要的一项task,又快又准的自动标注工具不存在,但半自动标注必然成为每家AI公司必备的高效工具。
公众号后台回复“项目实践”获取50+CV项目实践机会~

“
点击阅读原文进入CV社区
收获更多技术干货