最新图文识别技术综述
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转载自我爱计算机视觉,原文为发表在中文科技期刊的论文。作者参考了 77 篇较有影响力和最新的论文,详尽地综述了图像文本检测与识别的系统、算法、数据、性能比较,相信对从事相关研究开发的朋友有帮助。
图文识别技术综述
牛小明
(1. 四川长虹电器股份有限公司, 软件与服务中心, 绵阳 621000)
摘 要:本文概括性的介绍了图文识别所涉及的技术。首先介绍了图文识别的背景知识,包括应用领域、技术难点及挑战和系统实施流程等;其次介绍了图文识别技术的预处理方法及流程,包括旋转校正、线检测、特征匹配、字符轮廓提取及分割、OCR识别流程;接着介绍了图文识别过程中常用的特征提取基础网络和检测网络,以及它们的场景适配问题;然后介绍了近年来出现的各种图文检测深度学习网络、图文识别深度学习网络、端到端图文检测与识别深度学习网络,并分析了各类检测和识别网络的网络架构、算法思路及其特点;最后介绍了公开的图文识别训练、测试数据集以及不同算法的性能比较。
0 引言
OCR(Optical Character Recognition, 光学字符识别)[1]传统上指对图像进行处理及分析,识别出图像中的文字信息;场景文字识别[2](Scene Text Recognition,STR)指识别自然场景图片中的文字信息。不少人将OCR技术定义为广义的所有图像文字检测和识别技术 (简称图文识别技术), 即包括传统的OCR识别技术,又包括自然场景文字识别技术。
OCR图像可能存在旋转、弯曲、折叠、残缺、模糊[1]等式样,图像中的文字区域还可能会产生变形;另外,文档图像大多属于规则的表格类票据;因此,为了得到较好的文字检测效果和文字识别效果,需要进行大量且有效的预处理过程:包括图像降噪、图像旋转校正、线检测、特征匹配、文字轮廓提取及分割等。
传统深度学习OCR的训练过程包含两个模型[2]:文字检测模型和文本识别模型;在推理阶段,将这两个模型组合起来构建成整套的图文识别系统。近几年出现了端到端的图文检测与识别网络:在训练阶段,该模型的输入包含待训练图像、图像中的文本内容以及文本对应的坐标;在推理阶段,原始图片经过端到端模型直接预测出文本内容信息。相比较传统的深度学习方法,该方法训练简单、效率更高、线上部署资源开销更少。
图文识别技术涉及计算机视觉处理和自然语言处理两个领域的技术[2];它既需要借用图像处理方法来提取图像文字区域的位置、并将局部区域图像块识别成文字,同时又需要借助自然语言处理技术将识别出的文字进行结构化的输出。它有着广泛的应用场景:应用于单据、车牌、身份证、银行卡、名片、快递单、营业证等识别[3]。
1 图文识别预处理技术及流程
1.1 图文识别预处理技术
图文识别预处理技术包含图像分割技术、图像旋转校正技术、线检测技术、图像匹配技术、文字轮廓提取及局部分割技术等。
1.1.1 图像旋转校正
通过打印机扫描或手机拍照获取的图像可能会旋转;以表格类票据图像为例,旋转的票据图像会严重影响票据图像版面的行列定位,从而增加了票据版面分析的难度。因此,采用有效的旋转校正[4-6]方法对票据图像进行校正,可明显提升票据识别系统的性能。
1.1.2 直线检测
直线检测的准确性对表格类票据的OCR定位具有决定性的作用,常用的方法有[7-10]:投影变换、Hough变换、链码、游程等;其中实用性较好的算法 . 是Hough变换算法及其改进方法[11]。另外,矢量化算法[12, 13]在直线检测流程中也有较广的应用。
1.1.3 图像匹配
图像特征匹配方法可应用于字符定位、印章检测等;借助图像匹配算法,可检索到ROI(region of interest)区域的位置,从而间接定位到相应的字符位置。
国内外提出了很多匹配方法用于提高匹配速度和性能;比如,互相关检测图像匹配算法[14],相似性测度匹配方法[15],自适应映射匹配方法[16],尺度不变特征转换(Scale-invariant feature transform, SIFT)匹配算法[17];基于遗传算法的图像匹配方法[18]等。
1.1.4 字符轮廓提取及分割
字符识别之前,需要将字符完整分割出来;常用的字符分割方法主要有:阈值分割算法[19],形态学分割算法[20]和基于模型的分割算法等。票据印刷字体有其自身的特点[21],一般的字符分割算法首先进行垂直方向投影,然后分析字符轮廓,最后根据提前测定的字符节距或尺寸进行分割;主要分为以下两类:行列分割法[22]和孤立图像分割法[23]。
1.2 图文检测与识别流程
1.2.1 传统OCR检测及识别流程
传统的OCR识别流程主要包含以下步骤:图像预处理(噪声过滤、灰度变换、图像旋转校正、二值化等)、版面分析(表格线检测、关键区域的特征匹配、文字区域分段分行等)、字符切分、字符特征提取、字符特征匹配、版面理解、格式化数据输出等流程,见图1。
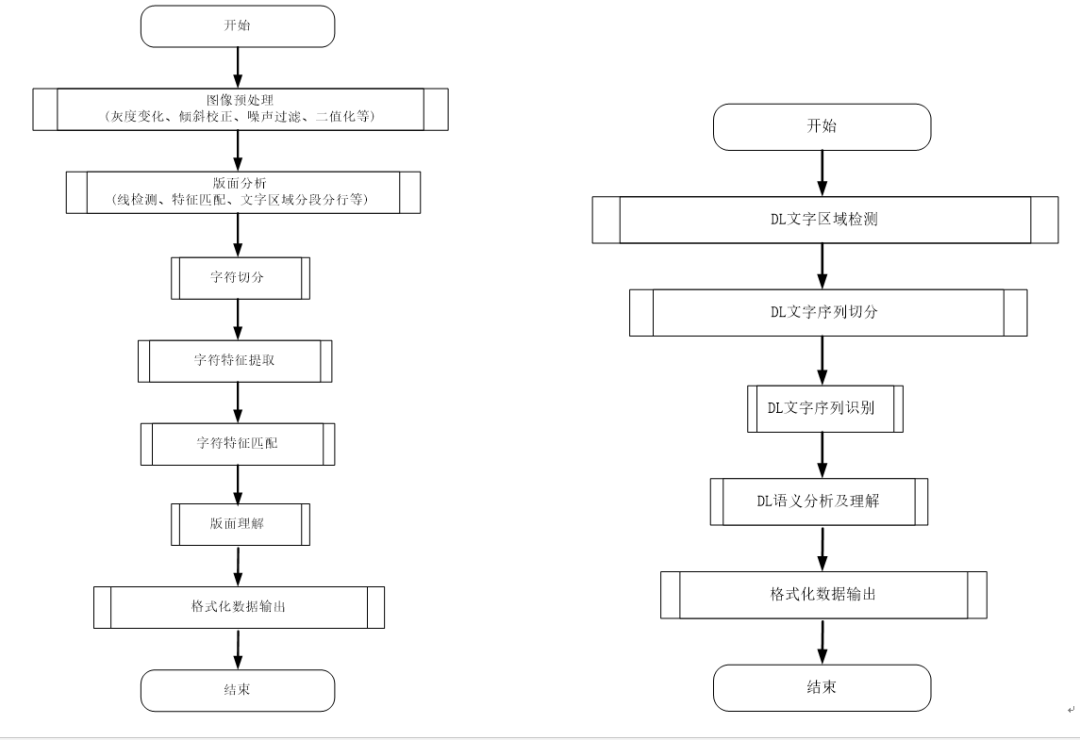
图 1 传统OCR 识别流程图 图 2 深度学习 OCR 识别流程图
1.2.2 深度学习OCR检测与识别流程
基于深度学习的OCR识别流程主要包含以下步骤:深度学习文字区域检测、深度学习文字序列切分、深度学习文字序列识别、深度学习语义分析及理解和格式化数据输出等流程;流程中的DL指Deep Learning(深度学习),见图2。
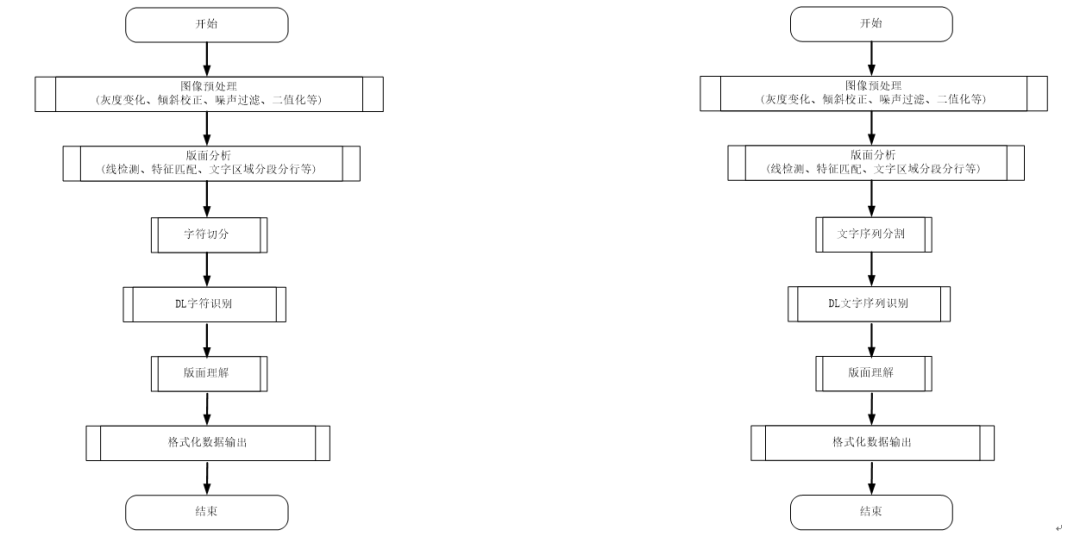
图 3 混合式 OCR 识别流程图
1.2.3 混合OCR检测与识别流程
混合式的OCR识别流程这里介绍了两种流程模式:预处理部分,以及字符或序列切分部分采用传统的算法、字符识别与序列识别分别采用深度学习方式,见图3。在图像预处理阶段,子图(a)和子图(b)均采用传统的方法;在识别方面,均采用了深度学习的方法,但是(a)是对单字符识别,而(b)是对整个文字序列进行识别。
2 基于深度学习的图文检测与识别技术
2.1 通用检测及变换网络
图文识别任务中用于特征提取模块的基础网络,可来源于通用场景的图像分类模型,也可来源于特定场景的专用网络模型。下面介绍几种基于深度学习的通用图像检测网络[24]和图像变换网络。
2.1.1 Faster RCNN网络
Faster RCNN[25]是一个常用的检测网络框架,检测结果是寻找出被检测对象的紧凑包围边框;如图4所示;Fast RCNN将特征提取、区域候选网络、目标区池化和目标分类整合到一个网络中,大大提升了目标检测的速度。它在Fast RCNN检测框架基础上引入区域候选网络,来快速产生多个候选区域参考框,通过目标区池化层,为多尺寸参考框构建归一化的固定尺寸区域特征;利用共享的卷积网络,同时向上述区域候选网络和目标区池化层输入特征映射,减少了卷积层的参数量和计算量。
2.1.2 SSD网络
SSD[26](Single Shot MultiBox Detector),是2016年提出的一种全卷积目标检测算法;相比较Faster RCNN网络,它的速度优势较为明显。如图5所示,SSD是一种one stage算法,可直接预测出被检测对象的边框和得分。检测过程中,SSD算法借助多尺度方法进行检测,在不同尺度的特征图上构建多个默认框,然后进行回归与分类;最后,利用非极大值抑制方法得到最终的检测结果。
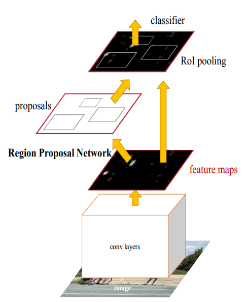
图 4 Faster R-CNN 网络

图 5 SSD 网络
2.1.3 FCN网络
全卷积网络[27](FCN, fully convolutional network),最初用于语义分割,它去除了全连接(fc)层。FC的优势在于利用上采样操作,比如反卷积、上池化等,将特征矩阵尺寸变换到接近原图大小;然后对每一个位置上的像素做类别预测,从而得到更准确的物体边界。基于全卷积的检测网络,不经过候选区域回归物体边框, 而是根据高分辨率的特征图直接预测出物体边框。
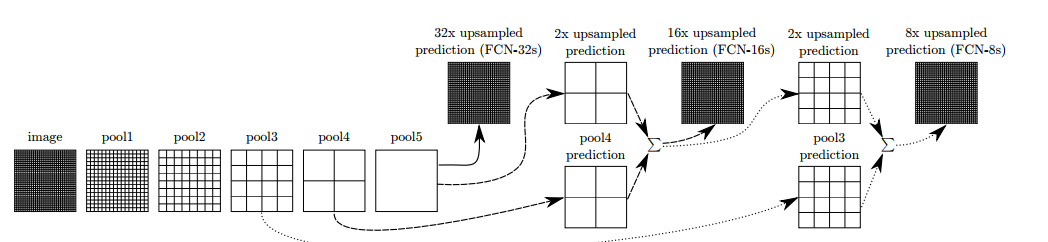
图 6 FCN网络
2.1.4 STN网络
空间变换网络[28](STN,Spatial Transformer Networks)的作用是对输入特征图进行空间位置校正,得到输出特征图;它允许在网络中对数据进行空间变换操作,比如平移、缩放、旋转和扭曲,支持端到端的模型训练。STN网络由定位网络,网格生成器,采样器共3个部分组成。
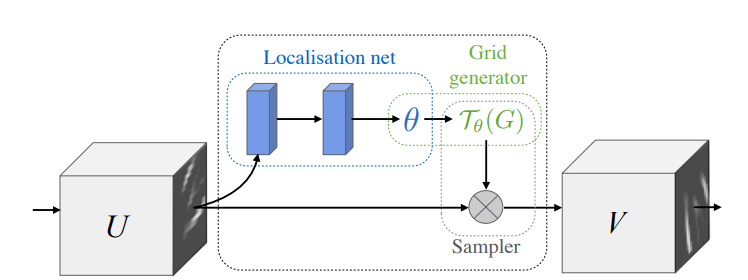
图 7 STN网络
2.2 图文检测网络
图文检测的目标是从图片中找出文字所在的区域。将常用的深度学习检测网络(比如Faster-RCNN,SSD, YOLO等)直接用于图文检测,其检测结果并不理想;主要原因如下:文本行具有方向性;物体边框Box的描述方式信息量不充足;艺术字体可能会使用弯曲的文本行;手写字体变化模式多等。
针对上述问题,近年来提出了基于深度学习的多种技术解决方法。它们从以下维度对已有的检测网络进行了改造[2]:区域候选网络、多目标协同训练、特征提取、非极大值抑制、半监督式学习等;经上述改造,图文检测的准确率有了极大的提升。
例如:CTPN[29]网络,用BLSTM模块提取图像文本块中字符间上下文关系,以提高文本块识别精度。RRPN[30]网络,将旋转因素并入经典区域候选网络,一个图像文本区域的ground truth用5元组的旋转边框来描述;训练阶段,首先生成倾斜候选框(含方向角),然后在边框回归过程阶段,学习文本方向角。DMPNet[31]网络,使用四边形(非矩形)标注文本框;SegLink[32] 网络,首先将每个单词切分为小的、带方向的、更易检测的文字块,然后用邻近连接方法将各小文字块连接成单词。TextBoxes[39]网络,调整了文字区域参考框的长宽比例,并将特征层的卷积核调整为长方形,从而更适合检测出细长型的文本行;FTSN[40]网络,采用Mask-NMS方法代替传统BBOX的非极大值抑制算法来过滤候选框;WordSup[41]网络,采用了半监督式的学习策略。
下面介绍几种近年来出现的文本检测专用网络。
2.2.1 CTPN网络
CTPN[29]是目前使用较为广泛的开源图文检测网络,可检测水平或微斜的图像文本行。文本行被看成一个字符序列,而不是单个的独立目标。字符序列中的各个字符互为上下文关系;检测网络在训练阶段学习图像中的这种上下文统计规律,从而提升了文本块的预测准确率。
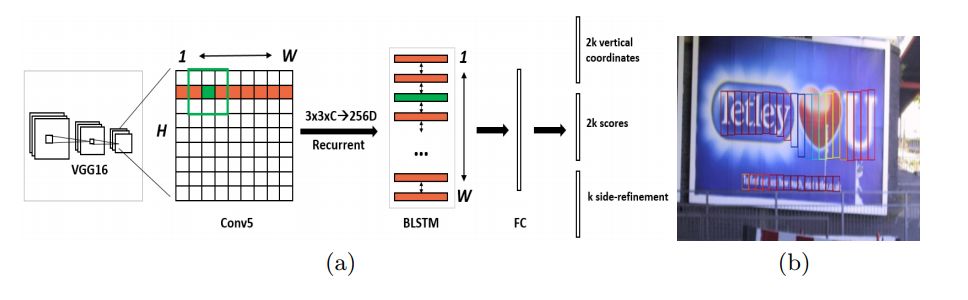
图 8 CTPN 网络
2.2.2 RRPN网络
旋转区域候选网络[30](RRPN, Rotation Region Proposal Networks),将旋转因素并入经典区域候选网络(如Faster RCNN)。在该网络中,一个图像文本区域的ground truth用5元组的旋转边框来描述:边框的几何中心坐标、边框的短边、边框的长边和方向角。训练阶段,首先生成倾斜候选框(含方向角),然后在边框回归过程阶段,学习文本方向角。
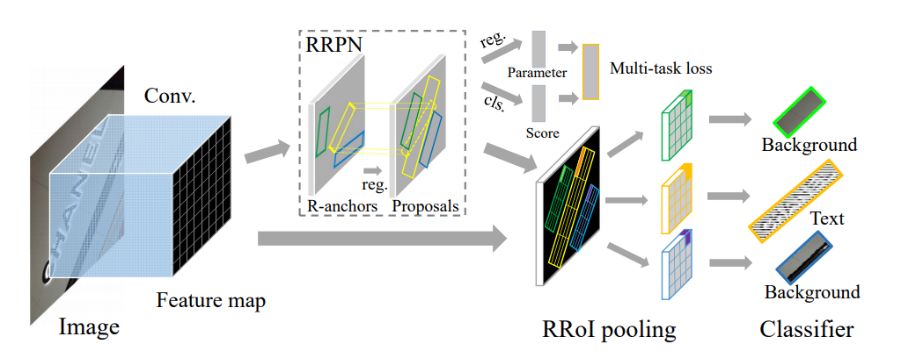
图 9 RRPN文本检测流程
2.2.3 SegLink网络
SegLink网络[32]中,首先将每个单词切分为小的、带方向的、更易检测的文字块,然后用邻近连接方法将各小文字块连接成单词。该方法适用于带有方向的文本行识别、且识别的长度变化范围较大;与CTPN图文检测网络相比,SegLink网络的推理速度较快。
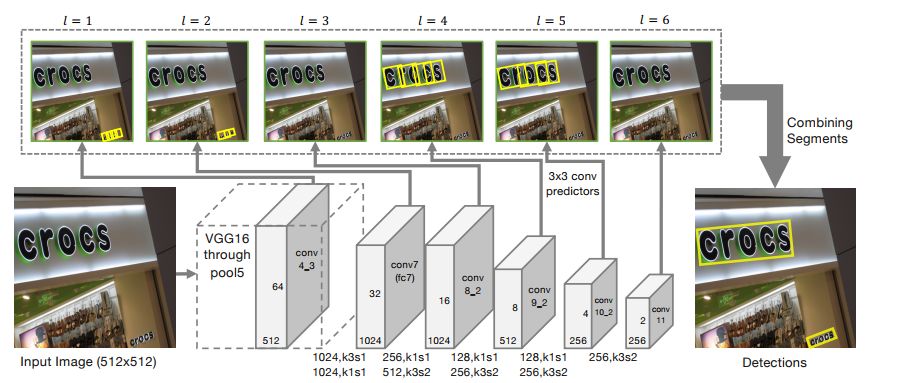
图 10 SegLink 网络
2.2.4 IncepText网络
针对复杂场景,为了更好的提高大尺度、变形图文图像的检测正确率,模型具有更好的适应性;InceptText[33]网络提出了一种基于变形的PSROI池化模块,更好的解决了上述问题。具体网络架构如下:
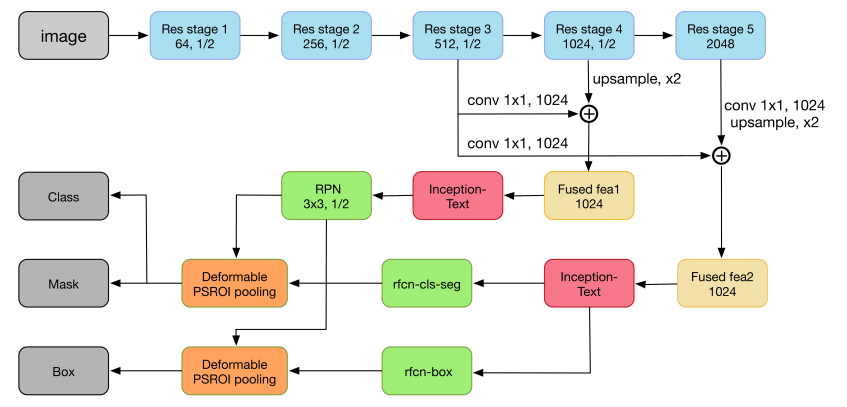
图11 IncepText 网络
随后,在端到端的图文检测中,Yuchen Dai、Yuliang Liu、Xinyu Zhou、Dan Deng等人分别提出了FTSN[34]网络、DMPNet[35]网络、EAST[36]网络、PixelLink[37]网络,支持倾斜文本的检测;另外,Han Hu等人提出了WordSup[38]网络,应用于数学公式图文识别,变形、不规则文本的识别。
2.3 图文识别网络
图文识别网络是将已分割出的文字区域图像块识别成文字内容,常用的图文识别网络有:CRNN[42]网络、RARE[43]网络、ESIR[44]网络。
2.3.1 CRNN网络
CRNN[42](Convolutional Recurrent Neural Network)是目前较为流行的图文识别网络,可识别相对较长、可变的文本序列。特征提取层包含CNN和BLSTM,可进行端到端的联合训练。它借助BLSTM和CTC网络学习字符图像间的上下文关系,从而有效提升图文识别的准确率,见图11。
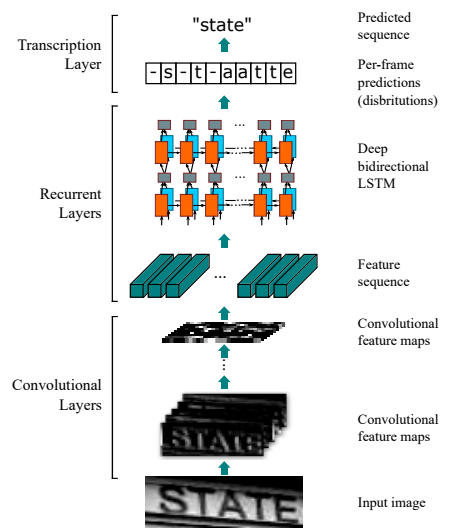
图 12 CRNN网络框架图
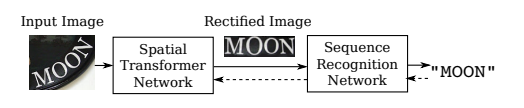
图13 RARE网络系统框图
2.3.2 RARE网络
RARE[43] (Robust text recognizer with Automatic Rectification)网络在识别变形的图像文本时,效果相对较好。如图12所示,模型推理过程中,输入图像经过空间变换网络,得到校正后的图像;随后,校正后的图像进入序列识别网络,最终得到文本的预测结果。
2.3.3 ESIR网络
ESIR端到端场景文字识别[44]包含两部分,一个是迭代的文本校正网络,另一个是序列识别网络。
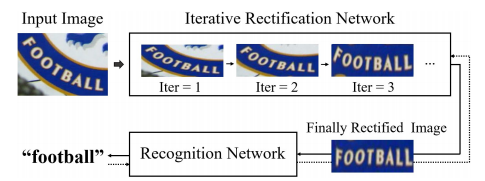
图14 ESIR网络框图
2.4 端到端图文检测与识别网络
端到端图文检测与识别的目标:一站式、直接从图片中定位和识别出所有的文本内容;近年来常用的端到端图文检测与识别网络FOTS[45]网络、STN-OCR[46]网络、Integrated Framework[47] 和MORAN[48]网络。
2.4.1 FOTS网络
FOTS(Fast Oriented Text Spotting)[45]是端到端的学习网络,图文检测和识别同步训练。检测和识别共享卷积特征层,既节省计算时间,又学习到更多的图像特征。引入了旋转感兴趣区域,支持倾斜图文的识别,见图15。

图15 FOTS 网络系统框图
2.4.2 STN-OCR网络
STN-OCR[46]是端到端的图文检测与识别网络。检测过程内嵌一个空间变换网络,对输入图像进行仿射变换。借助这个空间变换网络,对检测到的文本块分别进行旋转、缩放和倾斜,等同于进行了数据增强,从而提升了识别阶段的准确率。STN-OCR属于半监督学习,只需标注文本的内容,不需要标注文本的位置信息。
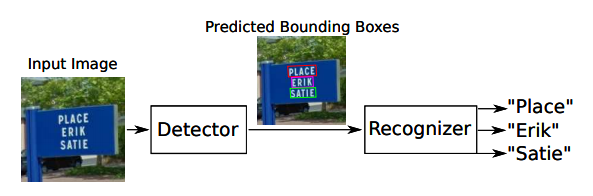
图16 STN-OCR 网络系统框图
2.4.3 Integrated网络
基于集成式的端到端文本检测与识别网络[47],通过模型参数共享的方式,将检测模型与识别模型融合成一个流水的端到端训练的模型;通过参数共享的方式不仅可以提高检测识别的效率,同时可以提高端到端文本与检测的识别正确率。整体流程框架如下图:
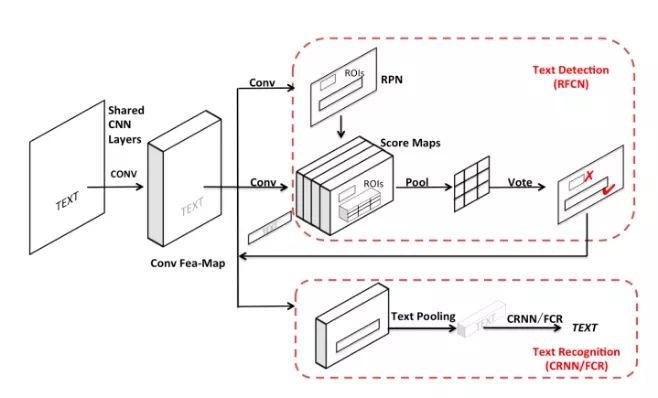
图17 Integrated网络系统框图
2.4.4 MORAN网络
MORAN文本识别端到端网络[48]由校正子网络MORN和识别子网络ASRN组成;MORN中,设计了一种新颖的像素级弱监督学习机制,用于不规则文本的形状纠正,大大降低了不规则文本的识别难度。MORN与ASRN可进行端到端联合学习,训练过程不需要标记字符位置或像素级分割的监督信息,大大简化了网络的训练过程。
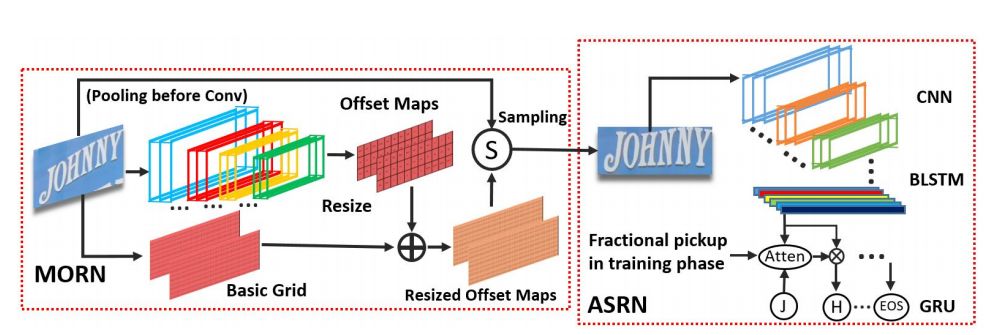
图18 MORAN网络系统框图
2.4.5 AON网络
AON(Arbitrary Orientation Network) [49]可有效识别规则和不规则的自然场景下的图像文本。AON网络可以提取四个方向的场景文本特征和字符定位的信息,设计了一个滤波门(FG)用于融合四方位的文本特征,在字符识别框架中集成了AON网络、滤波门和Attention-Based 解码,整个网络是端到端的模型。具体模型框架如下:
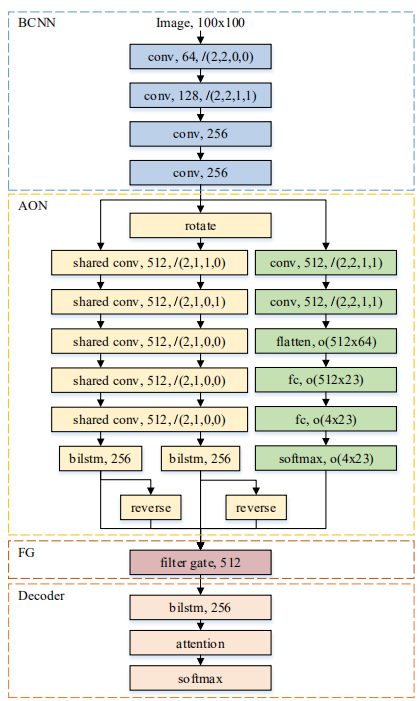
图19 AON网络系统框图
2.4.6 Unconstrained 端到端网络
Unconstrained[50]端到端网络可有效识别任意形状的文本图像。Unconstrained端到端网络包含Mask R-CNN检测网络和Seq2Seq(sequence-to-sequence) Attention-Based解码网络;它将任意形状的文本检测归结为实例分割问题,然后借助Attention-Based模型解码任意形状的文本区域,不用提前做文本区域的校正。具体网络结构如下:
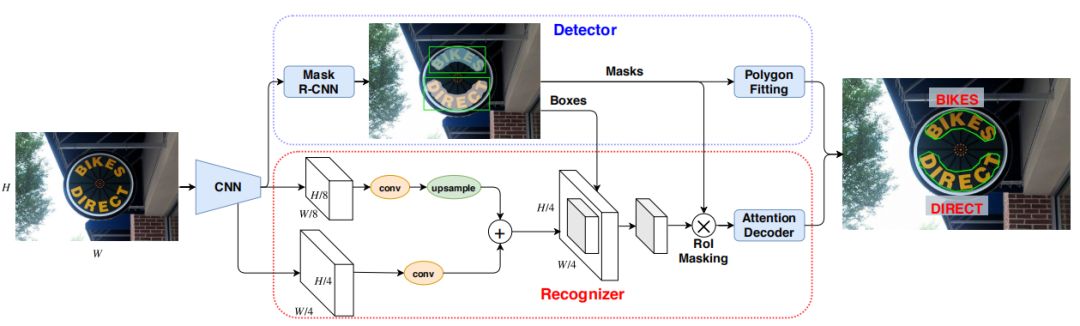
图20 Unconstrained端到端网络系统框图
随后,Anh Duc Le[51]等人也提出了端到端的文本识别方法,其中检测过程采用CTPN网络,识别过程采用AED网络,对票据OCR识别具有较好的效果。Mohammad Reza Sarshogh等人提出了多任务的端到端识别[52]网络,该网络可同时进行文本检测、文本识别和文本分类。
3 数据集及性能比较
本节列举了公开的、大型图文识别训练和测试数据集以及不同检测网络和端到端识别网络的性能比较。
3.1 数据集
大型图文识别训练和测试数据集如下:CTW(Chinese Text in the Wild) 数据集[53]、RCTW-17(Reading Chinese Text in the Wild)数据集[54]、ICPR MWI 2018 挑战赛数据集、Total-Text数据集[55]、Google FSNS(谷歌街景文本数据集) 数据集[56]、COCO-TEXT数据集[57]、Synthetic Data for Text Localization自然场景文本数据[58]、Synthetic Word Dataset、Caffe-ocr中文合成数据、ICDAR15数据集[59]、SVT-Perspective[60]数据集和CUTE80[61]数据集等。
3.2 性能比较
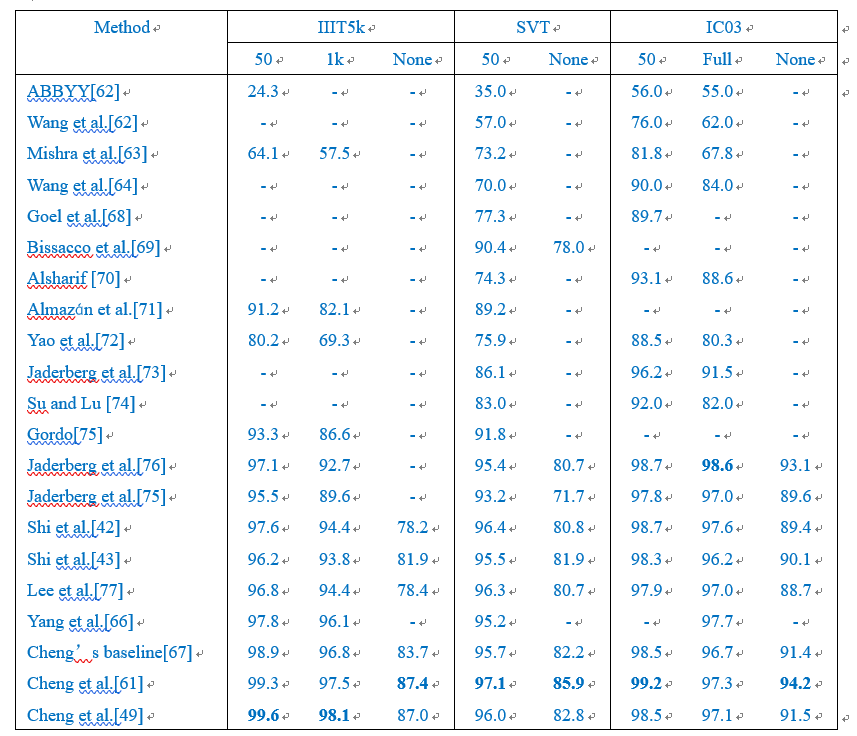
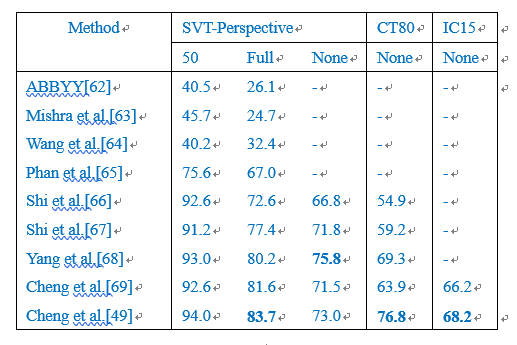
表格1和表格2分别列出了不同识别方法在ICDAR15数据集、SVT-Perspective数据集和CUTE80数据集的效果比较[49];其中,表格1列出了规则数据集的识别效果比较,表格2列出了不规则数据集的识别效果比较。实验条件:硬件采用Intel Xeon(R)E5-2650 CPU, NVIIDA Tesla P40 GPU;软件配置CUDA8和CUDNN V7。
表格1和表格2中的"50"和"1k"表示利用包含"50"和"1k"个字符序列的图文进行比较;"Full"表示利用数据集里包含所有字符序列的图文进行比较;"None"表示未加约束。
表格1 规则数据集图文识别性能比较
表格2 不规则数据集图文识别性能比较
通过表格1和表格2不同图文识别算法的性能比较可以看出:近些年随着深度学习算法的发展,图文识别性能在明显的提升。在不规则数据集上,Shi et al.[66]、Shi et al.[67]、Yang et al.[68]、Cheng et al.[69]、Cheng et al.[49]等算法在SVT-Perspective数据集上取得了比较好的结果;另外,Cheng et al.[49]在CT80和IC15数据集上识别性能相对较好,Yang et al.[68]在SVT-Perspective数据集上“None”的测试模式下识别性能相对较好。在规则数据集上,Gordo[75]、Jaderberg et al.[76]、Shi et al.[42]、Shi et al.[43]、Lee et al.[77]、Yang et al.[66]、Cheng [67]、Cheng et al.[61]、Cheng et al.[49]等识别算法在不同数据集上均取得了比较好的结果。
4 结论
图文检测与识别技术可应用于银行、财务、金融、工业等领域。传统的图文数据通过人工记录,耗时较多;借助图文识别技术将图像转为文字并输出结构化数据,自动记录至后台可大大节约劳力,提升效率。本文从系统层面概括的介绍了图文识别的常用技术:首先介绍了图文识别的应用背景;其次介绍了图文识别过程中常用到的特征提取网络、检测网络,以及它们在图文识别应用领域中的局限性;再次介绍了近几年的各种图文检测网络、图文识别网络、端到端图文检测与识别网络,最后介绍了图文识别领域的大型公开数据集及图文检测和识别的不同算法性能比较。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、检测分割识别、三维视觉、医学影像、GAN、自动驾驶、计算摄影、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
推荐阅读
计算机视觉方向简介 | 立体匹配技术简介
计算机视觉方向简介 | 基于自然语言的跨模态行人re-id的SOTA方法(上)
最新AI干货,我在看



