图灵测试还重要吗?

撰文丨Harry Collins(卡迪夫大学社会学教授)
来源丨原理(ID:principia1687)
1
我们正在步入人工智能时代。随着人工智能程序越来越擅长像人类般行事,我们也越来越多地面临这样一个问题:人类的智能是否真有什么特别之处?还是说我们只是另一种类型的机器?有一天,我们所知道和所做的每件事,是否有可能被一个安装在足够复杂的机器人上的复杂计算机程序所复制?
1950年,计算机先驱和战时密码破译者图灵(Alan Turing)做出了最有影响力的尝试来解决这个问题。在一篇具有里程碑意义的论文中,他提出,通过一个简单的测试,就可以消除人类和机器智能之间的模糊性。这个“图灵测试”评估计算机模仿人类的能力,由另一个看不见机器但可以问它书面问题的人来判断。
在过去几年里,有几款人工智能软件宣称已经通过了图灵测试。这使得有些人认为,这个测试太过于容易,以至于无法用作为人工智能的有用判断。但我认为那些软件根本没有通过图灵测试,甚至在可预见的将来都不会通过。但是如果有一天,人工智能真的通过了一个设计恰当的图灵测试,那么我们就有理由开始担心我们的独特地位。
图灵测试实际上一项是针对语言流利性的测试。如果理解得当,它可以揭示的是人类最独特的方面——我们不同的文化。文化的不同导致我们在信仰和行为上表现出巨大的差异,这种差异在动物或大多数机器身上是看不到的。事实上,我们可以在计算机程序中编写这种差异,这正是赋予了计算机模仿人类能力的潜力的程序。在判断模仿的流畅性时,图灵测试让我们可以通过了解计算机在社会环境中对语言的掌握,来判断它们在人类文化中的分享的能力。
2.
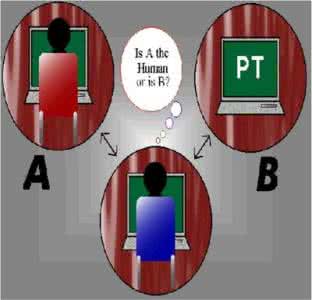
图灵测试的基础是“模仿游戏”。假定在游戏中有三个人(如下图):男A、女B,以及询问者C。C独自呆在一个房间中,C与A、B的交流只能通过两个连接A、B所在房间的传真机来完成。C需要通过和A 、B进行对话,判断他们哪个是男人、哪个是女人。A的目的是模仿女人,尽量扰乱C的判断;B的目的是尽量让C相信自己是个女人。

现在,如果我们将A换成一台机器,再按照如上规则重新进行游戏,那么C在进行判断时的准确率是否与当A是一个男人时一样?
在1950年那个时期,图灵没能制定出可以让我们来评判今天人工智能软件的必要协议。首先,他建议测试可以在五分钟内完成。但他没有发现,判定者和人类玩家必须共享同一种文化,而计算机必须能试图模仿这种文化。这才导致了有的人声称已经通过了测试,而还有一些人则称测试过于简单,或者应该将物理能力的模拟包含在内。
3
在随着计算机科学家Joseph Weizenbaum在近50年前创建了名为ELIZA的程序后,这一点变得很明显。ELIZA被用来模拟一种被称为罗杰斯式(或以人为中心)的心理治疗师。几个与这个程序接触过的病人都以为它是真实的,从而形成了最早的关于图灵测试已被通过的说法。
但Weizenbaum很清楚,ELIZA实际上就是个笑话。这个设置甚至没有遵循图灵提供的协议,因为病人并不知道它们可能不是真的,也没有一个真正的心理治疗师同时做出反应。此外,在那项测试中并不涉及文化,因为罗杰斯治疗师需要说得尽可能少。而任何有价值的图灵测试都必须让判定者和玩家尽可能像人类一样行事。
基于这是一个关于理解文本的测试,计算机需要根据前百分之几的文字编辑的能力来进行判断。如果提的问题正确,它们可以表明计算机是否理解了其他参与者的物质文化。
4
正确的问题类型可以基于1975年的“Winograd模式”,即两个句子之间的差别仅为一两个单词,但需要具备关于这个世界的知识才能理解。这样的人工智能测试被称为Winograd模式挑战,它于2012年首次提出,是对图灵测试的一种改进。
举个简单的例子,想想下面这句有两个可能结尾的话:“这个奖杯放不进这个手提箱,因为它太小/大了。”如果最后的形容词是“小”,那么“它”指的就是手提箱;如果最后的形容词是“大”,那么“它”指的就是奖杯。
若要能理解这一点,你必须了解奖杯和手提箱的文化和现实世界。你还必须了解奖杯和手提箱的物理世界,以及你是否真的触碰过这些事物。因此,采用了这种方法的图灵测试将会使那些包含了对人工智能模仿人类身体能力的评估的测试变得多余。
这意味着一个基于Winograd模式的图灵测试比简单的五分钟对话更能评估计算机的语言和文化流利性。与此同时,它也设立了一个更高的标准。在2016年的一场相关比赛中,所有的计算机都惨败给了这个测试,没有任何来自大型人工智能公司的竞争者参与这场比赛,因为他们知道自己注定会失败。
如果把图灵测试设置为一系列对人类创造和理解文化的独特能力的严峻考验的话,那么那些所谓的已经通过了图灵测试的说法都变得毫无意义。有了恰当的协议,测试才能达到要求。再一次,图灵又是对的。而且就我们目前的情况来看,并没有明显的途径可以创造出能够充分深入参与人类文化,并通过正确的语言测试的机器。
原文标题为“Turing Test: why it still matters”
原文链接:https://theconversation.com/turing-test-why-it-still-matters-123468,中文内容有增删,仅供参考,一切内容以原文为准。

未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”