反向 Dropout!韩松团队最新工作NetAug:提高Tiny神经网络性能的新训练方法

极市导读
韩松团队提出针对TinyNN推理无损涨点的新型训练方案NetAug。本文从正则技术的作用以及TinyNN与大网络的容量角度出发,分析了为何正则技术会影响TinyNN的性能,进而提出了适用于TinyNN的新型训练方案NetAug。在ImageNet分类任务上,NetAug可以提升MobileNetV2-tiny性能达2.1% 。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2110.08890
Abstract
本文提出一种新的改善TinyNN(Tiny Neural Network)性能的训练方法NetAug(Network Augmentation )。现有的正则技术(比如数据增强、dropout)在大网络方面(比如ResNet50)方面通过添加噪声使其避免过拟合取得了极大成功。然而,我们发现:这些正则技术会损害TinyNN的性能(见下图)。 我们认为:不同于大网络通过增广数据提升性能,TinyNN应当通过增广模型提升性能 。这是因为:受限于模型大小,TinyNN往往存在欠拟合现象而非过拟合 。
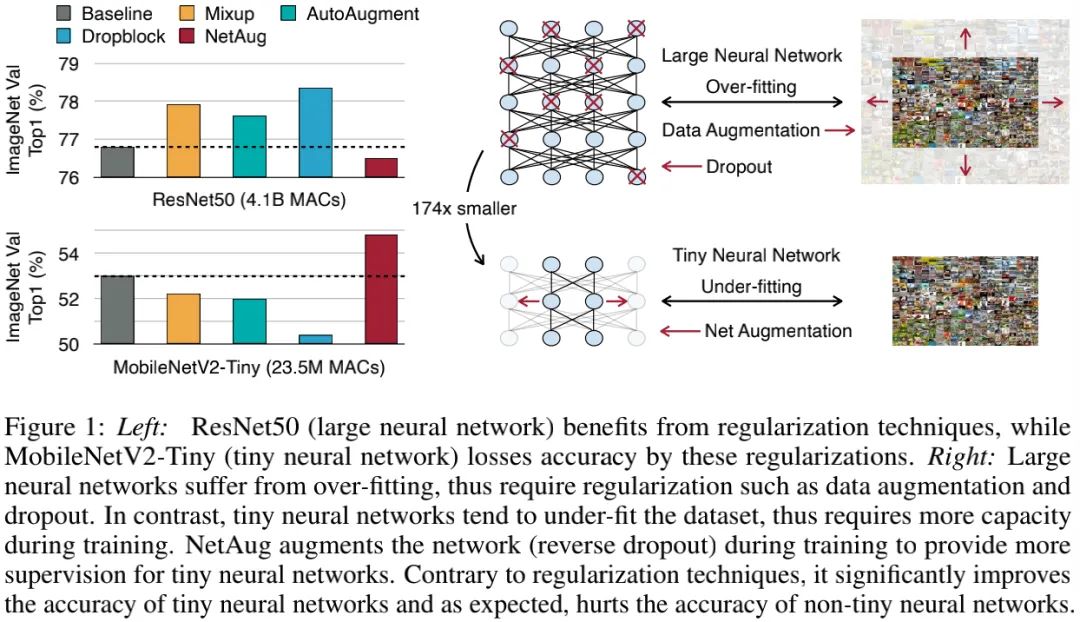
为缓解该问题,NetAug对网络进行了增广,而非数据添加噪声或者网络中插入dropout。它将TinyNN嵌入到更大的模型中并使其作为大网络的子模型工作以得到额外监督 ,而作为非独立模型(见上图)。在测试阶段,仅TinyNN用于推理,不会导致额外的推理负载。
我们在图像分类与目标检测任务上验证了NetAug的有效性。在ImageNet分类任务上,NetAug可以提升TinyNN性能达2.1% ;在Pascal VOC检测任务上,NetAug可以提升TinyNN2.96%mAP指标。值得一提的是,NetAug配合MCUNet可以取得比YOLOV3+MobileNet更高的mAP指标,同时计算量从60G下降到600M MACs 。
Method
接下来,我们首先对NetAug进行描述;然而引出实际实现;最后对NetAug在训练与测试过程中的额外负载(仅在训练过程带来16.7%额外负载,0推理负载)进行了讨论。
Formulation
假设TinyNN的权值与损失分别为 。在训练过程中,权值通过SGD进行更新。由于TinyNN的容量有限,它很容易陷入局部最优,导致较差的性能。
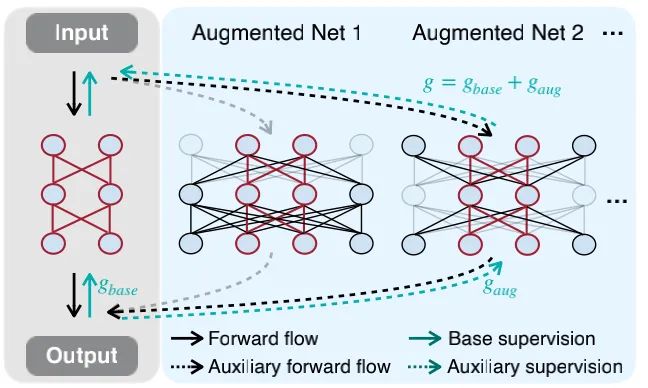
本文旨在通过引入额外的监督辅助TinyNN训练解决上述问题。相比dropout迫使大网络的子网络进行预测,NetAug则通过增广TinyNN的宽度使其作为更大网络的子网络(见上图)。增广后的损失函数定义如下:
其中, 表示基础损失,其他部分则是辅助监督损失。
Implementation
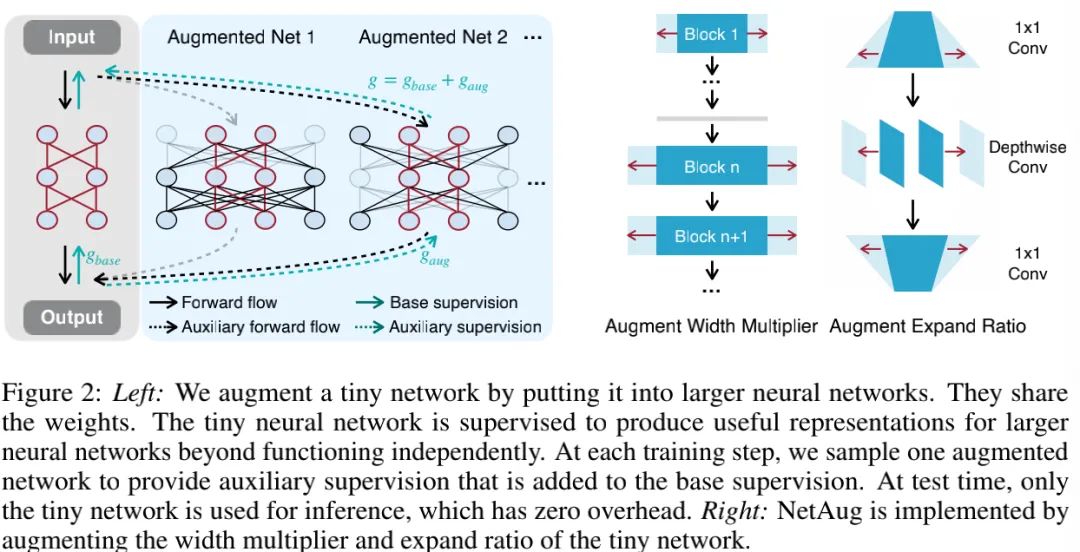
Constructing Augmented Models 由于模型大小会随增广模型数量线性增加,同时独立的保存每个增广模型是资源不可接受的。因此,我们对不同增广模型的权值进行共享,仅保留最大的增广模型,从中选择子网络作为增广模型,见下图左示意图。
权值共享策略已被广泛应用于one-shot NAS与多任务学习。本文的目标与训练过程与前述两者完全不同:
-
one-shot NAS训练一个权值共享的super-net以支持所有可能的子网络,其目标在于提供高效性能估计;相反,NetAug仅聚焦于改善TinyNN的性能。此外,NetAug同样可以用于NAS方案中以提升模型性能。
-
多任务学习旨在通过权值共享跨任务迁移知识;相反,NetAug在单任务上从增广模型向TinyNN迁移辅助监督信息。
具体来说,我们通过增广模型宽度构建最大的增广模型(见上面Figure2右图)。相比增广深度,宽度增广的额外训练耗时更少。比如,假设卷积的宽度为 ,增广因子 。因此,最大增广卷积宽度为 。为简单起见,我们采用单个超参控制网络中所有操作的增广因子 。
在完成最大增广模型构建后,我们通过选择通道子集构建其他增广模型。我们采用超参 (灵活度因子)控制增广模型配置。我们设置增广宽度为 的线性空间。比如,当 时,可能的宽度为 。不同的层可以使用不同的增广比例。通过这种方式,我们可以得到更灵活的增广模型,同时每个模型均包含目标TinyNN。
Training Process 前面公式给出了训练损失,但实际训练过程中,每次迭代仅采用一个增广模型用于提供辅助监督信息 。当然,采样更多也可以进行训练,但是,作者发现:采样更多增广模型不仅提升训练耗时,同时还会影响性能 。
Training and Inference Overhead
NetAug仅作用于训练阶段,在推理阶段,我们仅保留TinyNN。因此,NetAug的额外推理负载为零。此外,NetAug并不会改变网络结构,因此它不需要特殊的软硬件系统支持,这就使其易于部署实用。
考虑到训练负载,NetAug会添加额外的前向与反向过程,看起来会导致两倍的训练消耗。实际上,训练耗时仅增加了16.7% 。这是因为TinyNN的训练耗时主要由数据加载与通讯消耗住在,而非前向与反向计算。因此,NetAug导致的额外训练耗时负载仅为16.7% 。除了训练耗时外,NetAug还会增加训练峰值显存占用。由于我们聚焦于TinyNN训练,其峰值显存占用非常小,因此NetAug仅带来轻微的额外显存占用。
Experiments
在方案验证方面,作者主要从图像分类与目标检测上进行了验证。图像分类用到了ImageNet、Food1l1、Flowers102、Cars、Cub200、Pets等;目标检测则只在Pascal VOC数据集上进行了验证。
Results on ImageNet
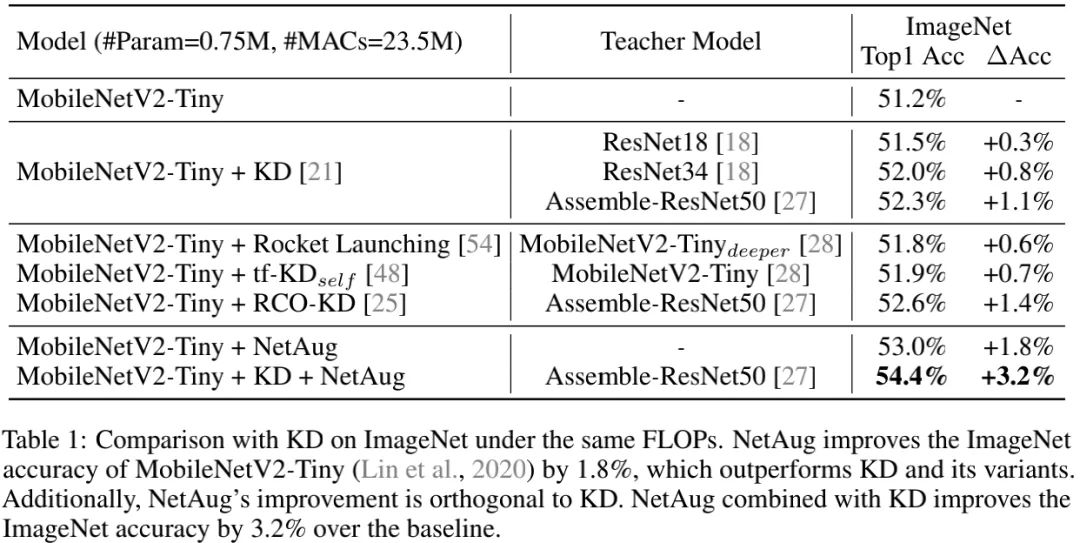
上表对比了NetAug与知识蒸馏在MobileNetV2-Tiny上的性能,可以看到:
-
NetAug可以提升1.8%精度,高于KD的0.3-0.8%;
-
NetAug与KD具有互补性,两者组合使用可以进一步去提升1.4%性能;
-
KD可视作一种可学习标签平滑,而NetAug则旨在解决TinyNN的欠拟合问题。两者组合可以提升模型性能高达3.2%。此外,作者还对比了其他KD方案。
-
总而言之,NetAug具有比KD类方案更优的性能提升,两者组合可以达成强强结合的作用。
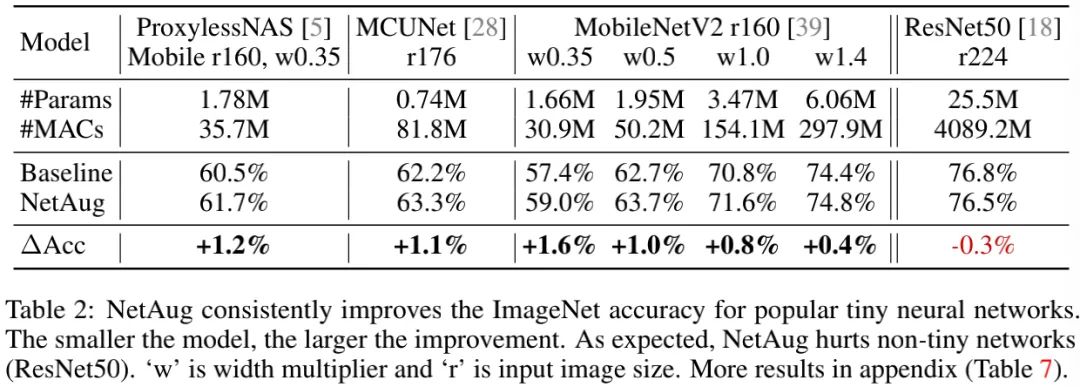
上表给出了NetAug在其他TinyNN以及大网络(如ResNet50)上的性能对比,可以看到:
-
在不同TinyNN架构上,所提NetAug均可取得性能提升;越小网络性能提升越多;
-
在大网络上,NetAug则会损失模型性能,这与前面的分析相一致:大网络具有足够大的容量,需要的是更多的正则避免过拟合。
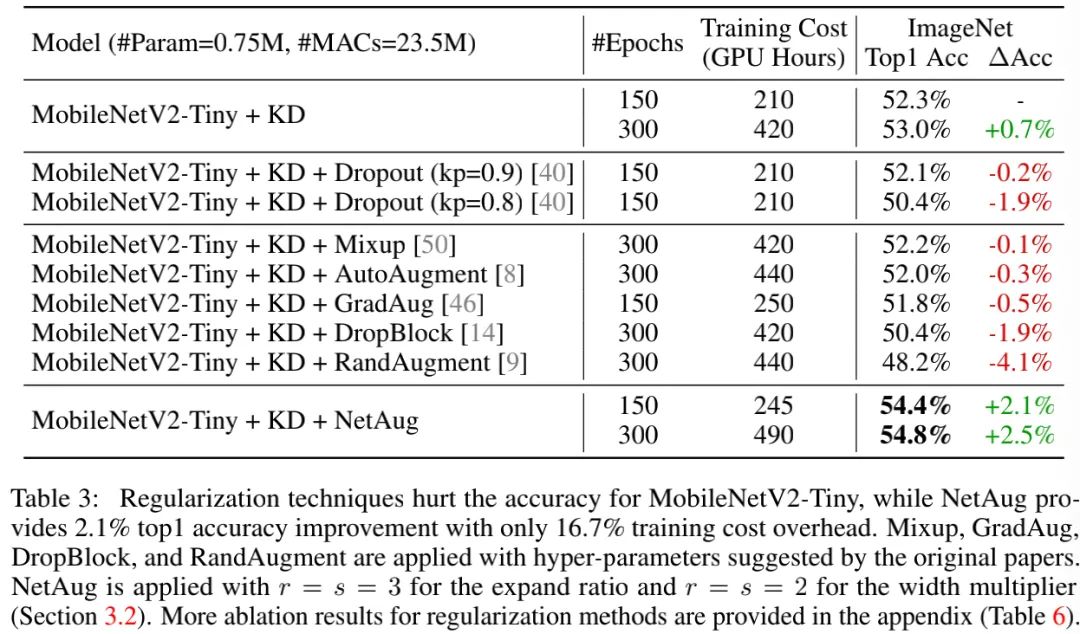
上表给出了所提方案与其他正则技术的性能对比,从中可以看到:
-
无论正则技术强度多大,它们都会损害模型性能 。这是因为:TinyNN的模型容量有限,存在欠拟合,而正则技术则是用于缓解过拟合问题。
-
在TinyNN架构上,NetAug通过提升训练时的模型容量达到提升性能的目的。故NetAug是一种比正则技术更适合于TinyNN的技术。
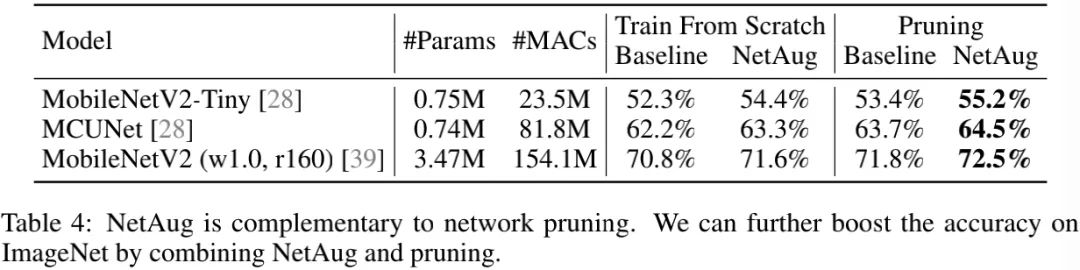
上表给出了所提方案与网络剪枝的作用对比,可以看到:
-
剪枝能提供比从头训练更高的精度;
-
剪枝与NetAug的组合可以进一步提升TinyNN的性能。
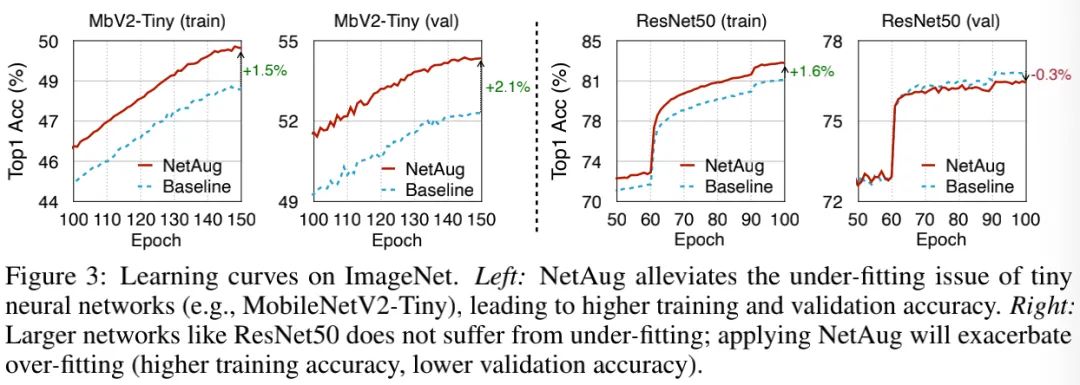
总而言之,NetAug通过缓解欠拟合提升TinyNN的性能。大网络并不存在欠拟合,使用NetAug则可能影响其性能(见上图);TinyNN的模型容量有限,存在过拟合问题,NetAug则可以有效提升其训练与验证精度。
Results on Object Detection
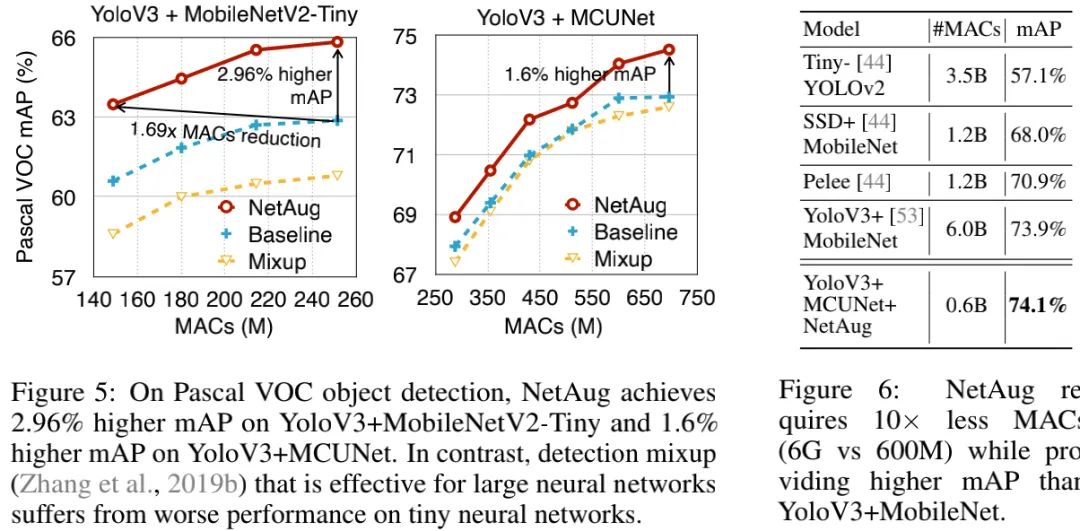
上表与图给出了目标检测任务上的性能对比,从中可以看到:
-
相比基线模型(YOLOV3+MobileNetV2-Tiny),NetAug可以带来2.96%性能提升;当性能相当时,NetAug方案可以降低模型MACs达1.69倍;
-
相比基线模型(YOLOV3+MCUNet),NetAug可以带来1.6%性能提升;
-
Mixup会降低YOLOV3+MCUNet/MobileNetV2-Tiny的性能,这说明:TinyNN的欠拟合问题同样存在于检测任务中 。
-
具有更少MACs的YOLOV3+MCUNet+NetAug取得了比YOLOV3+MobileNet稍高的精度(0.2%),这说明:NetAug能够学习更好的表达能力并泛化到检测任务中。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV技术深度Follower、爱造各种轮子
研究领域:专注low-level,对CNN、Transformer、MLP等前沿网络架构
保持学习心态,倾心于AI技术产品化。
公众号:AIWalker
作品精选





