动态滤波器卷积新高度!DDF:同时解决内容不可知与计算量两大缺陷|CVPR2021
极市导读
本文针对标准卷积存在的两个问题:内容不可知与计算量大问题,提出了一种具有内容自适应且更轻量的解耦动态滤波器,它将常规动态滤波器拆分为空域动态滤波器与通道动态滤波器。

paper: https://arxiv.org/abs/2104.14107
本文是加州大学默塞德分校Ming-Hsuan Yang团队在动态滤波器卷积方面的工作,已被CVPR2021接收。本文针对标准卷积存在的两个问题:内容不可知与计算量大问题,提出了一种具有内容自适应且更轻量的解耦动态滤波器,它将常规动态滤波器拆分为空域动态滤波器与通道动态滤波器,这种拆分可以极大的降低参数量,并将计算量限定在深度卷积同等水平。在图像分类、目标检测、联合深度估计等任务上的实验表明:DDF可以带来显著的性能提升。比如,在ResNet50/101网络的即插即用分别带来了1.9%/1.3%的性能提升。
Abstract
卷积作为CNN的基础部件之一,尽管常用,但存在两个主要缺陷:(1) 内容不可知;(2) 重度计算量。动态滤波器具有内容自适应特性,但同时进一步提升了计算量。深度(depth-wise)卷积是一种轻量型版本,但它往往会造成CNN性能下降,或者需要更大的通道数。
本文提出一种解耦动态滤波器(Decoupled Dynamic Filter),它可以同时解决上述缺陷。受启发于近期注意力的进展,DDF将深度动态滤波器解耦为空域与通道动态滤波器。该分解可以大大减少参数量,并将计算量限制在与深度卷积同等水平。同时,采用DDF替换分类网络中的标准卷积可以带来显著的性能提升。比如,ResNet50/101分别可以带来1.9%与1.3%的top1精度提升,且计算量近乎减半。在检测与联合上采样方面的实验同样证实了DDF上采样变种相比标准卷积的优异性。
本文所提DDF及其上采样变种DDF-Up具有以下几点优异属性:
-
Content-adaptive DDF提供了空间可变滤波器,这使得其具有内容自适应特性; -
Fast runtime DDF具有与深度卷积相近的计算量,因此它的推理速度要比标准卷积、动态滤波器更快; -
Smaller memory footprint DDF可以显著降低动态滤波器的内存占用,这使得我们可以采用DDF直接替换所有的标准卷积; -
Consistent performance improvements 采用DDF/DDF-Up替换标准卷积可以带来一致性的性能提升,同时在不同网络、不同任务上均取得了SOTA性能。
Preliminaries
Standard Convolution 给定输入特征 ,标准卷积对第i像素的操作可以描述如下:
在标准卷积中,所有像素的滤波器W均相同,即滤波器与输入内容无关。
Dynamic Filter 不同于标准卷积,动态滤波器利用额外的自网络对每个像素生成滤波器,即上述公式中的空域不变滤波器将变为空域可变滤波器 。动态滤波器可以促进内容自适应学习,但与此同时也带来了大量的计算量与显存占用。因此,动态滤波器通常用于微型网络或者替换CNN中的个别标准卷积。
Decoupled Dynamic Filter
本文的目标在于设计一种具有“内容自适应”且“比标准卷积更轻量”的动态滤波器。考虑到单个滤波器要同时具有上述两个属性的挑战性,我们通过解耦动态滤波器达成上述目的,它的关键在于将动态滤波器解耦为空域与通道动态滤波器。正式来讲,DDF空域描述如下:
其中, 分别表示空域动态滤波器与通道动态滤波器。从下图中可以看到:我们从输入分别预测通道与空域动态滤波器并按照上述公式计算得到输出特征。相比常规动态滤波器,DDF空域将原始的 尺寸动态滤波器减少到 个空域+ 通道动态滤波器。此外,我们采用CUDA进行DDF的实现,无需在训练或推理时保存中间多个滤波器。
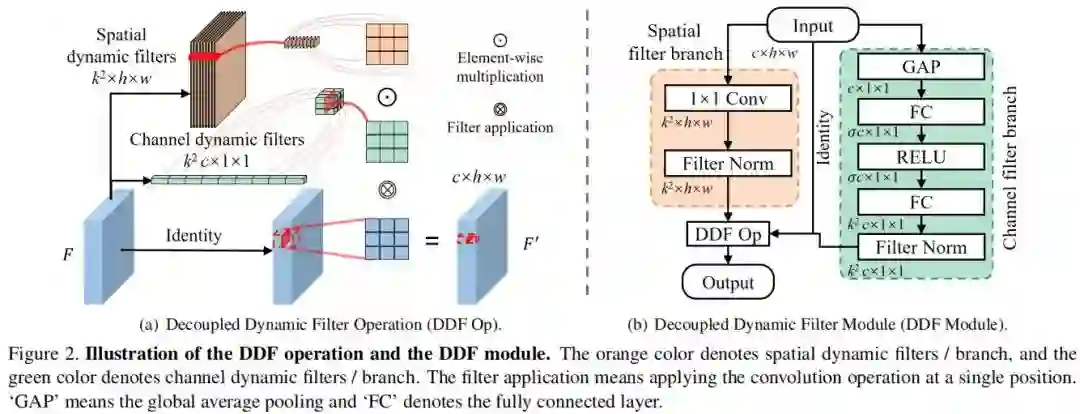
DDF module 基于DDF操作,我们精心设计了空域作为CNN基础部件的DDF模块(见上图),为此我们期望滤波器预测分支尽可能地轻量。我们注意到动态滤波器与注意力之间地相关性,我们设计了注意力类型地分类预测空域与通道滤波器。

对于空域滤波器预测分支,我们仅仅采用一个 卷积;对于通道滤波器预测分支,我们采用了类似SE注意力地结构,即GAP+FC+ReLU+FC。由于直接预测生成的滤波器可能非常大,也可能非常小,直接使用可能导致训练不稳定。我们进行了如下滤波器规范化(FN的设计参考了BN):
其中,
表示均值与标准差,
表示滑动标准差与滑动均值。FN有助于将生成的滤波器值限制在合理范围内,因此避免训练过程中的梯度消失/爆炸问题。
Computational Complexity

上表对比了标准卷积、深度卷积、动态滤波器卷积以及本文所提DDF在参数量、计算量、显存占用方面的对比。从中空域看到:
-
DDF的参数量要远小于动态滤波器的参数量;当 时,DDF的参数量甚至比标准卷积还要少。 -
DDF的计算复杂度与深度卷积在同一水平,要远小于动态滤波器卷积的计算量。 -
相比动态滤波器,DDF具有更少的显存占用; -
在推理速度方面,DDF快于标准卷积与PAC动态滤波器卷积。
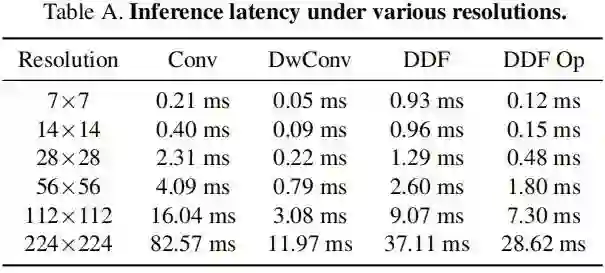
上表对比了不同卷积在不同分辨率下的实际耗时对比,可以看到:DDF算子的耗时明显更低。总而言之,DDF具有与深度卷积相近的推理耗时,且推理速度快于标准卷积、动态滤波器。值得注意的是,尽管生成了内容自适应滤波器,DDF的参数量仍然小于标准卷积的参数量。DDF的显存占用要远小于常规动态滤波器卷积。
DDF Network for Image Classification
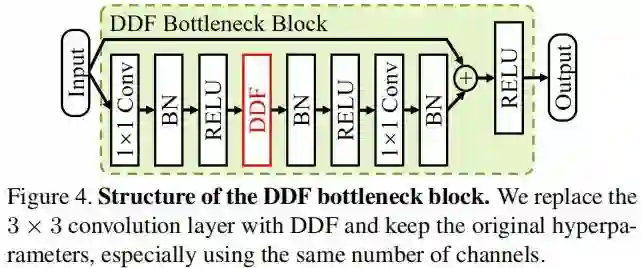
图像分类是一个基本的计算机视觉任务,为验证DDF的有效性,我们基于ResNet架构进行了对比,ResNet由Basic/bottleneck构成,我们设计的模块如下图所示,即替换了bottleneck中的 卷积,我们将所得ResNet称之为DDF-ResNet。

上表给出了DDF的消融实验对比,从中空域看到:
-
当仅仅采用空域动态滤波器替换标准卷积时,模型出现了显著的性能下降; -
当仅仅采用通道动态滤波器替换标准卷积时,模型性能提升1.6%,这与Involution一文的结论基本一致。Involution可以作为该文的一个特例? -
同时采用空域与通道动态滤波器时,模型性能提升最多,高达1.9%; -
相比Sigmoid规范化,FN可以带来更佳的性能。这是因为Sigmoid独立的处理每个滤波器,忽略了滤波器之间的相关性;而BN则会弱化不同样本之间的滤波器动态性。 -
更高的压缩比例可以显著减少参数量,而性能几乎变,仅下降0.1%。因此,默认 。 dynamic
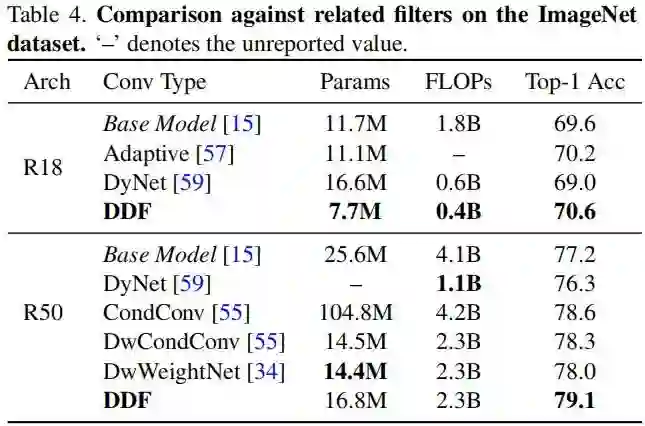
上表对比了不同动态滤波器的参数量、计算量以及性能方面的差异。从中可以看到:
-
相比基线模型,DDF方案均可取得性能上的提升,且显著的降低参数量与计算量; -
其他诸如CondConv、DyNet、WeightNet等方案的性能均不如DDF方案。 sota

最后,再来对比以下不同ResNet变种的性能差异。可以看到:DDF版本的ResNet具有最少的参数量、最少的计算量、最佳的精度。
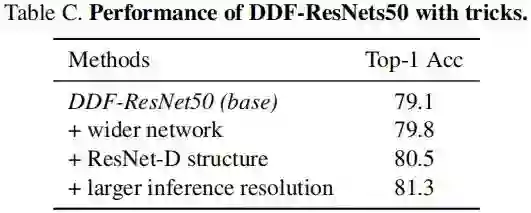
从上表可以看到:添加更多的技巧,DDF-ResNet的性能还可以进一步提升达到81.3%。
DDF as Upsampling Module
相比标准卷积,动态滤波器的一个优势在于:它可以从引导特征(而非输入特征)处预测动态滤波器。因此,我们提出了DDF模块的扩展版DDF-Up,见下图。DDF-Up包含
个DDF操作,比如上采样为2时,DDF-Up包含4个DDF操作。DDF-Up可以轻易的嵌入到需要上采样操作的网络结构中,本文从目标检测、联合深度估计任务方面进行对比分析。
Object Detection with DDF-Up
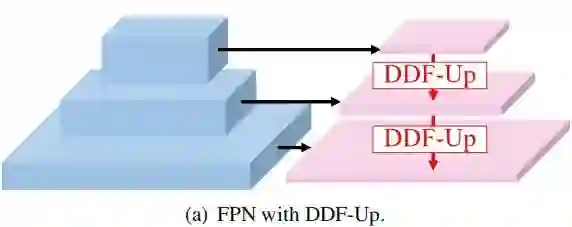
我们采用带FPN的FasterRCNN作为基线检测架构,并将DDF-Up嵌入到FPN中,见下图。
我们采用MMDetection进行模型训练,相关超参配置略过,直接看结果,见下表。
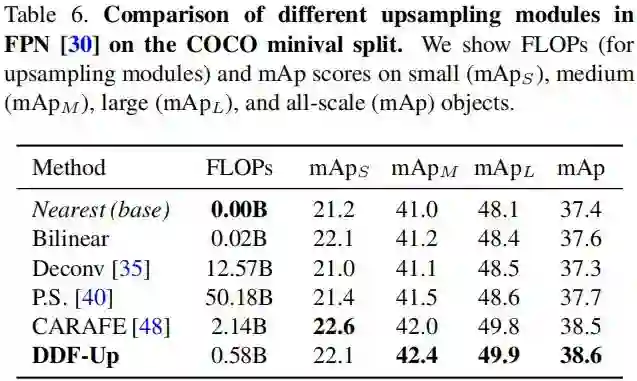
从上表可以看到:相比其他上采样方案,所提DDF-Up具有更佳的性能且计算量更低。
Joint depth upsampling with DDF-Up
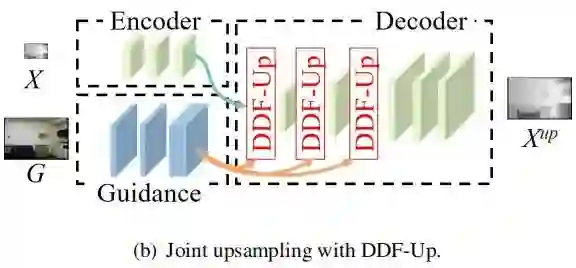
上图给出了DDF-Up在联合深度估计任务中所设计的模块,我们采用了类似PAC-Net的架构。
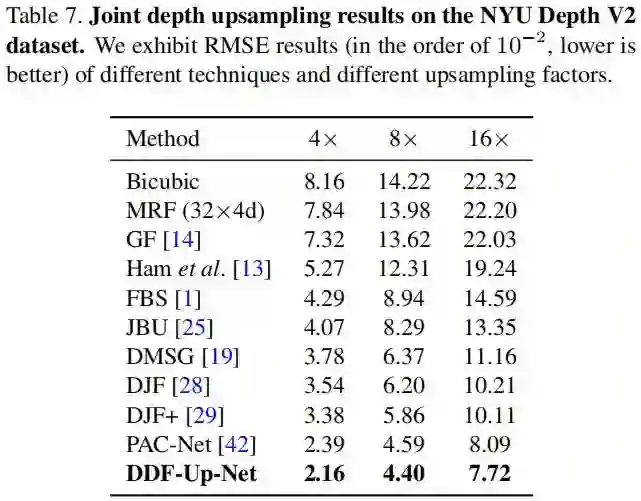
上表给出了NYUv2数据集上的性能对比,可以看到:DDF-Up-Net取得了最佳性能。 下图给出了可视化效果图,可以看到:DDF-Up-Net可以重建更多的细节。

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DDF” 就可以获取《动态滤波器卷积新高度!DDF:同时解决内容不可知与计算量两大缺陷|CVPR2021》专知下载链接




