代码也能预训练,微软&哈工大最新提出 CodeBERT 模型,支持自然-编程双语处理

一、背景

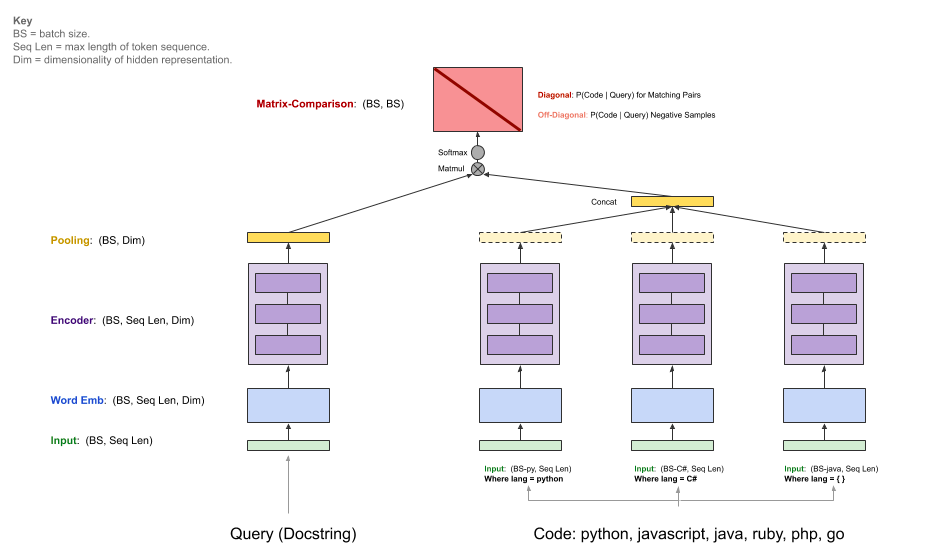
二、框架
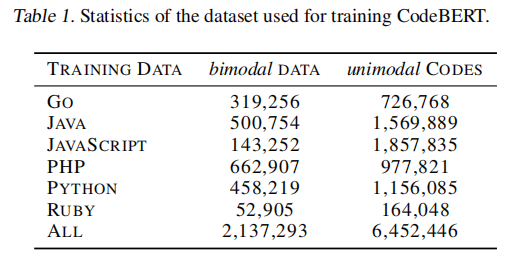
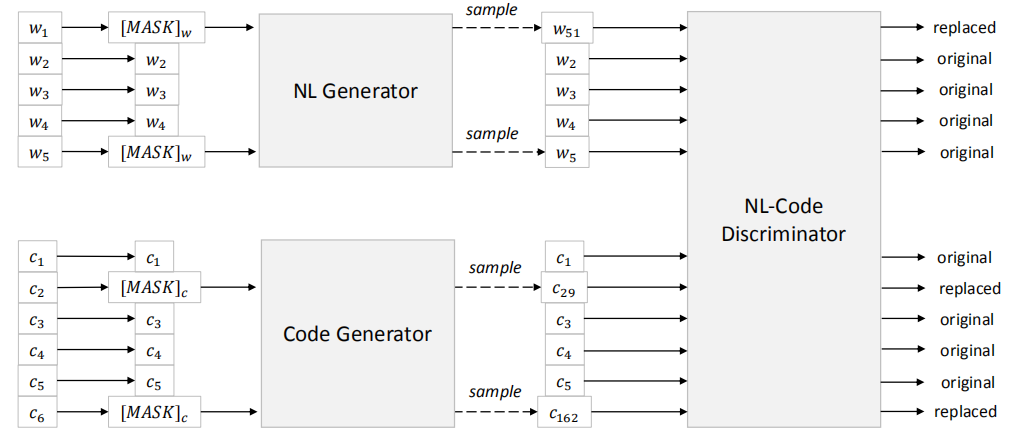
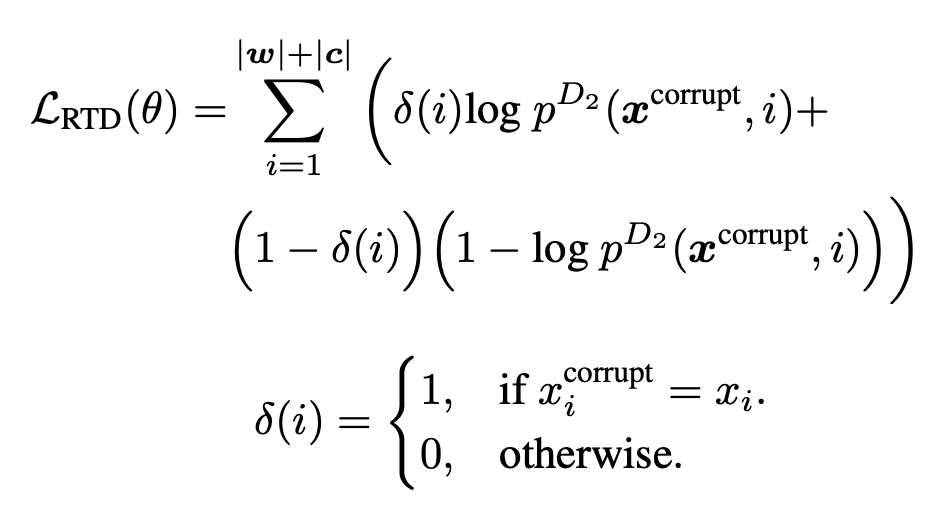
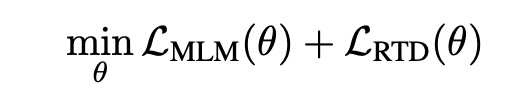
三、实验
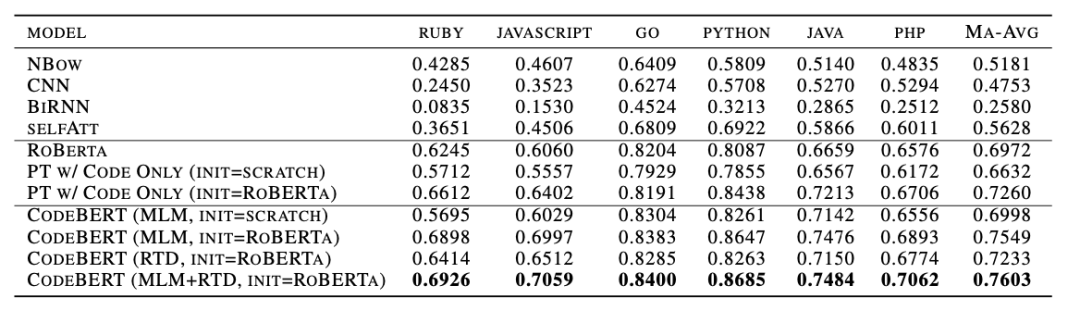
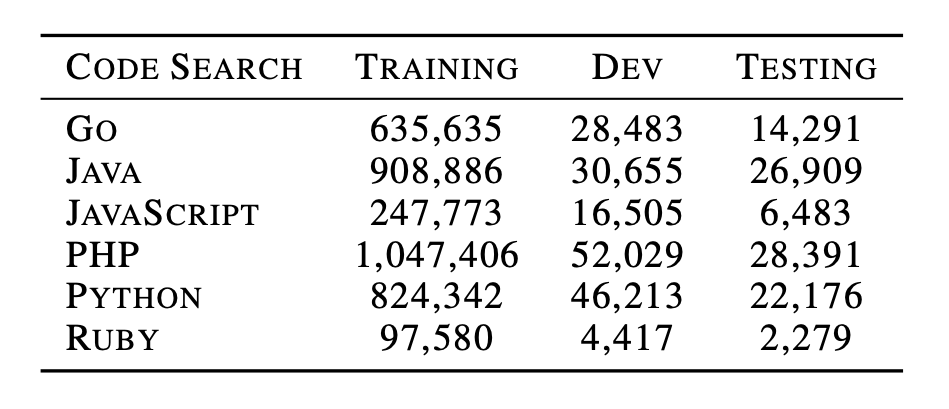
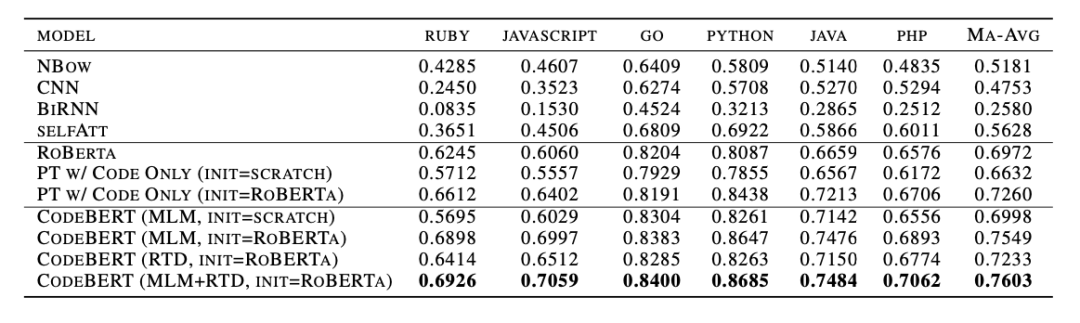
1、自然语言代码搜索
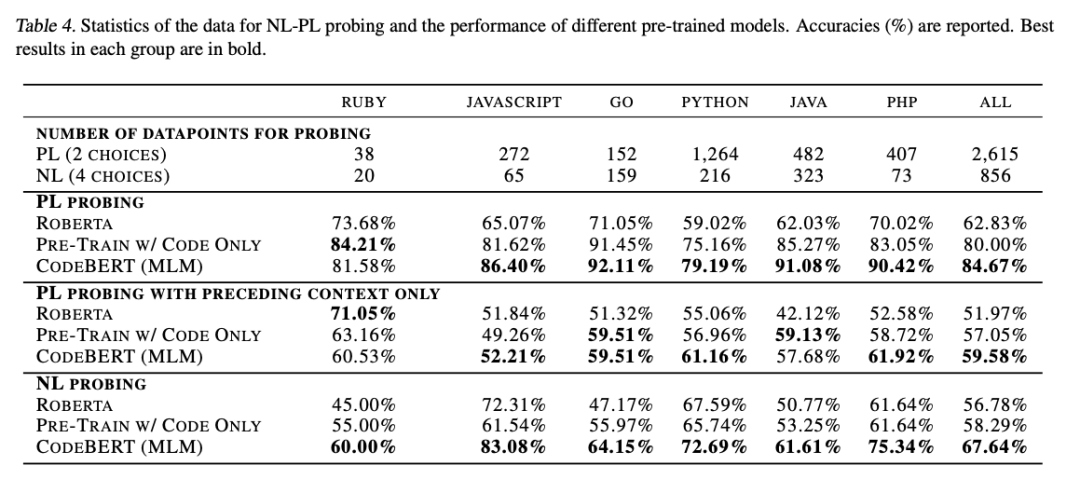
2、NL-PL Probing
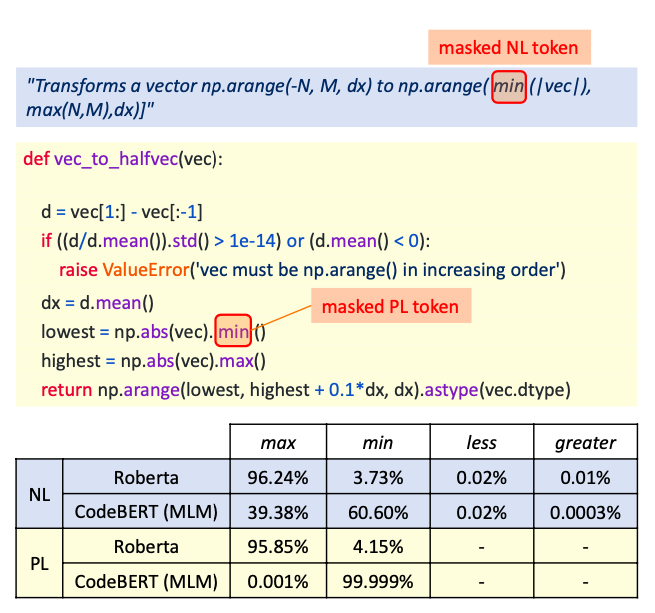
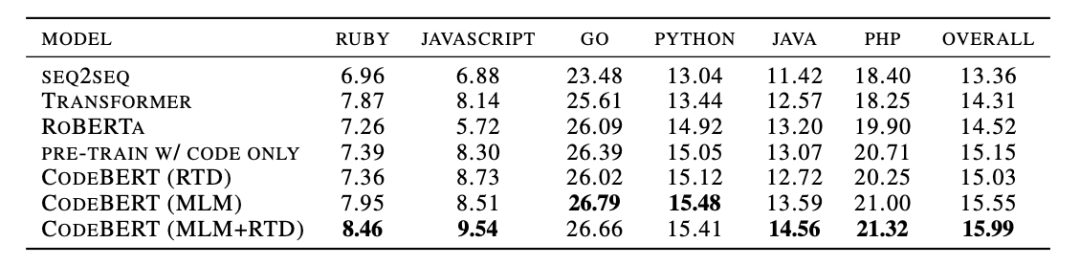
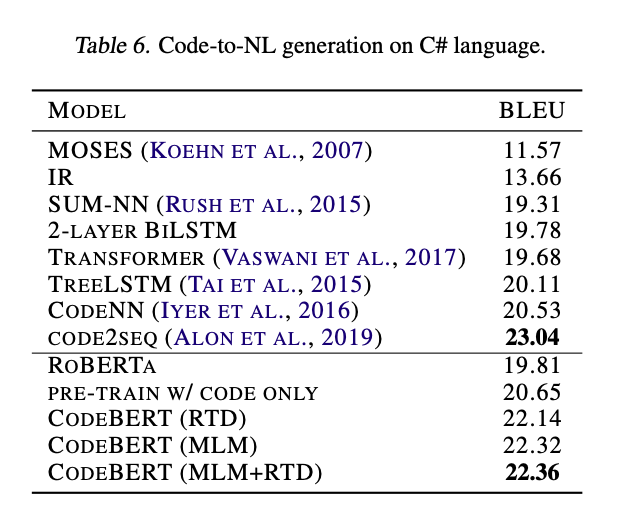
3、代码文档生成
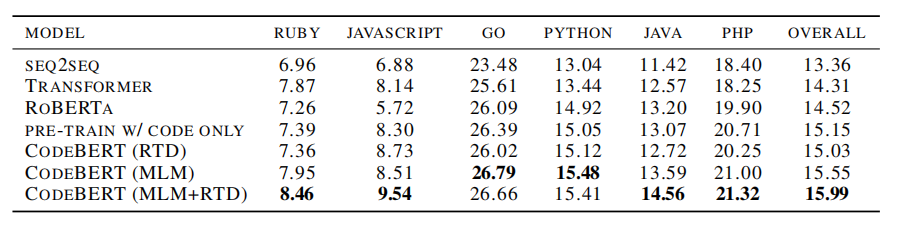
4、泛化能力
四、总结


登录查看更多
相关内容
专知会员服务
32+阅读 · 2020年2月21日
Arxiv
16+阅读 · 2019年5月24日




相关VIP内容
专知会员服务
32+阅读 · 2020年2月21日
相关资讯
相关论文
Arxiv
16+阅读 · 2019年5月24日