讲堂丨数据驱动的图形学:过去、现在和未来

编者按:早在深度学习之前,机器学习就已经被应用于图形学研究中。随着近年来深度学习研究的进展,计算机图形学也通过与深度学习的紧密结合而得到了新的发展。展望未来,机遇与挑战并存。本文根据微软亚洲研究院首席研究员童欣博士在中国科大本科创新班上讲课内容整理而成。
图形学的一个核心课题是如何在计算机里有效地产生和表达可视的三维内容。遵循对物理世界的观察,我们可以把研究对象进一步解构为如下研究课题:
第一方面是几何,就是三维空间中的形状;第二就是材质,它决定了当光打到这个物体上的时候,最后呈现出什么样的颜色;第三是动态,我们做出来的东西应当有一些复杂逼真的动态效果。最后,当我们想把这个场景呈现到屏幕上时,我们必须模拟光在这个虚拟场景中进行传输的整个过程,最后生成一幅具有真实感的图像,这个过程由绘制完成。

因为真实世界是三维的,很自然的我们可以按照真实世界的物理规律去在计算机中进行建模和模拟,这样产生了基于物理的方法。这个方法构建了图形学研究的基石,能对图形对象进行很好的建模和模拟,但是仍有一些缺点。第一,一个简洁的物理公式可以描述非常多的现象,但当用一个简单的物理公式去描述真实世界中所有这些细节的时候,导致过程复杂和庞大的计算量。第二,当艺术家想创造一些完全属于想象中的虚拟世界时候,如何放宽这些物理限制,同时还能生成看起来合理的非常漂亮的图像,就变成了一个很大的挑战。

上个世纪末,随着捕捉设备的发展,大家开始直接从真实世界中捕捉到高质量的图形学内容,比如用于记录几何数据的三维扫描仪,和在影视行业中广泛应用的运动捕捉技术。我把这一类方法叫做基于数据的方法(data-based approach)。它基本策略是对目标对象做一个非常直接、致密的采样,在使用时只需要做插值,就可以生成想要的结果。其好处是结果质量高,重构很快,计算很简单。缺点就是设备昂贵,使用起来也很复杂,对于用户的专业性有很高的要求。更麻烦是,即便只是捕捉一个对象,生成的数据量也非常大,并且数据之间缺乏联系,很难把用户的编辑传递到所有数据中去。因此这种方法只能满足一些特定应用,在大多数情况下还是很不方便的。

2000年左右,大家开始尝试一种新的方法,还是从真实世界中捕捉一些样本,然后运用这些样本结合机器学习的方法学习到欲求解空间中的一个模型,再用这个模型来推出新结果。我们把这个方法叫做数据驱动的方法(data-driven approach),它并不是简单地直接用数据进行插值,而是从数据首先利用机器学习得到解空间的一个模型出来,由此生成新的结果。这个方法有两个好处。第一,由于数据是从真实世界中捕捉来的,所以结果质量高。第二,可以通过模型对数据进行有效的编辑维护。这个方法过去多年被广泛应用,但它仍有一个一直解决不了的问题就是:到底应该用什么方法去学习模型,这个模型又应该具有什么特性?

在过去几年,我们组在 data-driven approach 方面做了一系列研究工作,结合自己和同行们的探索渐渐总结出了一些思路。下面我们先做个考古,看看在深度学习出现之前数据驱动的图形学研究,然后再讲深度学习和图形学结合面临的挑战和我们的探索;最后展望未来这一领域中还存在哪些问题和挑战。

深度学习出现以前,基于数据驱动图形学主要聚焦于如何从稀疏和少量数据中有效构建模型。这方面有三个常用的解决技巧:第一:利用稀疏性先验,找到一个空间,数据在空间的投影是稀疏的,第二,对问题分解,通过构建一些局部模型;三,如果一个问题的维度比较高,就把它 decompose 成一系列比较低维度的问题。
利用稀疏性求解表面材质
在这个工作[1]中,我们假设物体的几何,光照已知,希望从尽可能少的图片中恢复物体表面的反射属性。同时,我们想回答一个理论问题,给定一个物体的材质,最少需要多少张图像才能恢复出结果。

通过观察真实世界物体表面材质,我们发现:第一,大量的物体表面材质都可以由若干种基础材质组成,基础材质非常稀疏;第二。当我们建模每一个点的 BRDF 属性的时候,这些基也并不需要全部用到,每个点可以表达为其中几个基础材质的线性组合。利用这个表达,我们可以通过最小化重构的材质渲染的图片与拍摄图片的差来重建材质。为此,我们开发了专门的优化算法,来求解这个具有稀疏性约束的非线性优化问题。同时,基于这个求解框架,我们进行了一些分析。结论是所需要的图像数由每个点的所需要的基础材质数目决定。所以如果有一个物体,它表面的材质分成很多块,每一块都是一样的,比如足球,那理论上只要一张图像就够了。
利用局部模型和空间解构构建手部动画
在这个工作[2]中,给定少量的不同手部姿势的三维扫描结果,我们希望能够推导出这只手在所有可能姿势下的动画效果,同时生成手部表面所有的细节。这非常有挑战性,原因有二:第一,手有21个关节,变形的自由度非常高;第二,随着手的变化,褶皱细节的变化也很丰富。但是我们有的数据只包含十几个或二十几个手的姿势。
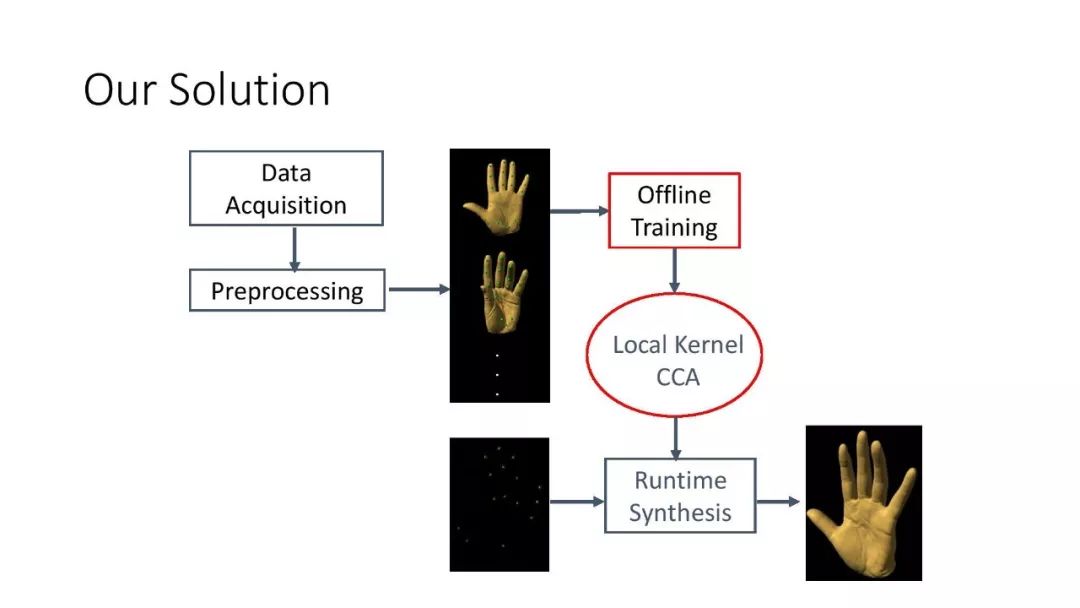
为解决这个问题,我们注意到两点:第一,所有变形都是由内部骨骼驱动的,一些控制点的变形可以决定其他所有点的变形,存在一个函数关系;第二,函数关系虽然可知,但比较复杂。于是我们把它分成几个部分,每一个局部区域都由一个独立的函数来控制。同时,对不同的姿态,我们用单独的局部函数控制它附近的变形。通过这样的分解,我们得到一些非线性的局部函数,再把一些细节运动、大尺度运动分解,最后得到一系列小模型,它们都可以从稀疏的数据中经过训练得到。在实验中,我们的模型可以有效地学习并生成合理手的动画,表面的细节也恢复得非常好。
小结
传统的基于数据驱动的方法优点是所需要的数据量小,获得的模型比较简洁,同时对输入噪声比较鲁棒。但是,这些方法缺乏通用性,需要针对每个特定的问题进行专门的设计。同时,每个模型以来于特定的假设。如果假设本身和数据有偏差,那么得到的模型无法获得很好的建模效果。
随着深度学习技术的发展,在过去几年中,深度学习也被应用于数据驱动的图形学研究中。但深度学习在图形学上的应用并不简单。根本的问题在于数据的高维度。不同于图像和视频,几何形体是三维的,它的形变动画就是4维的,而表面材质更是6维或8维的函数,光线的传输也是一个8维函数。数据的高维特性造成了一系列的问题,第一,因为数据维度比较高,无法用现有的捕捉设备捕捉到所有数据,因此三维数据没有统一的基于规则采样的表达。第二,数据捕捉难导致已有的三维数据的规模很小。第三,标注高维数据比标注二维数据难得多。我们认为,只有一步步把这些问题都解决了,深度学习在图形学中才可能发挥它的威力,推动图形学的发展。在过去几年中,我们也对这三个方面的挑战做了一些工作。
面向深度学习的有效几何表达
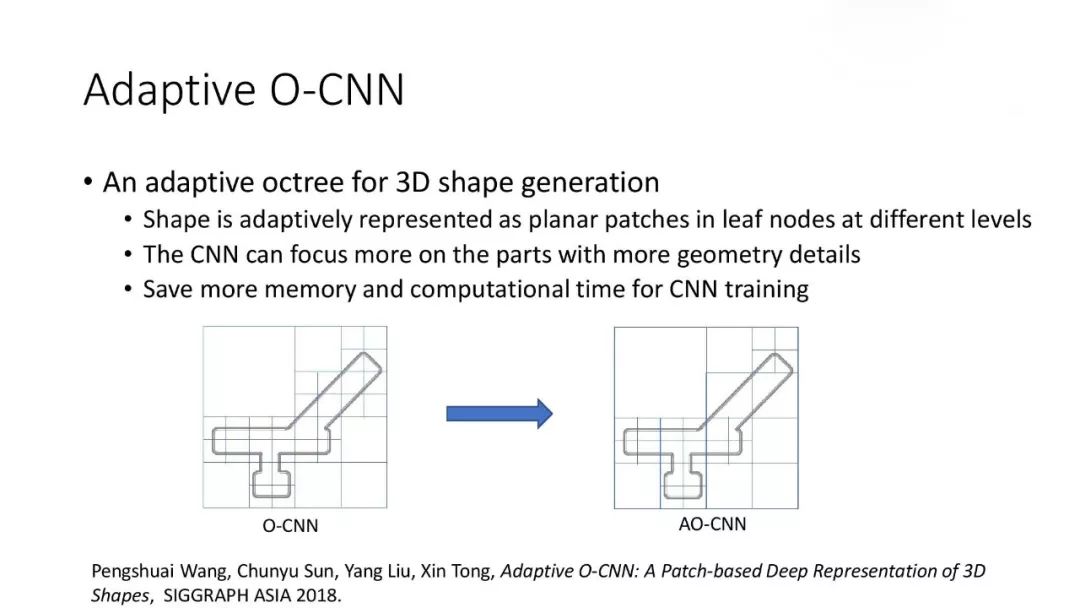
对于几何形状的表达,我们提出了基于八叉树[3],自适应八叉树[4],以及基于表面坐标架的卷积神经网络框架。这些框架可以直接继承已有的面向图像的卷积神经网络的架构,同时可以利用 GPU 进行有效的训练和推理。这些框架也被用于三维形状分析和重建中,验证了这些表达的有效性。

在今年的 CVPR 2019 的工作[5]中,我有幸参加了韩晓光博士、贾奎教授的团队的一个工作。这个工作提出了一种层次混合的表达来表达三维形状,并将这一表达应用于基于单张图像的三维重构中,取得了非常好的效果。通过这个工作,我们感到在 3D 形状上学习时,只用单个的底层表达可能不太充分,多层的表达可能可以更好的揭示形状空间的属性,因而更加有效。

通过跨越图像和三维的鸿沟解决数据问题
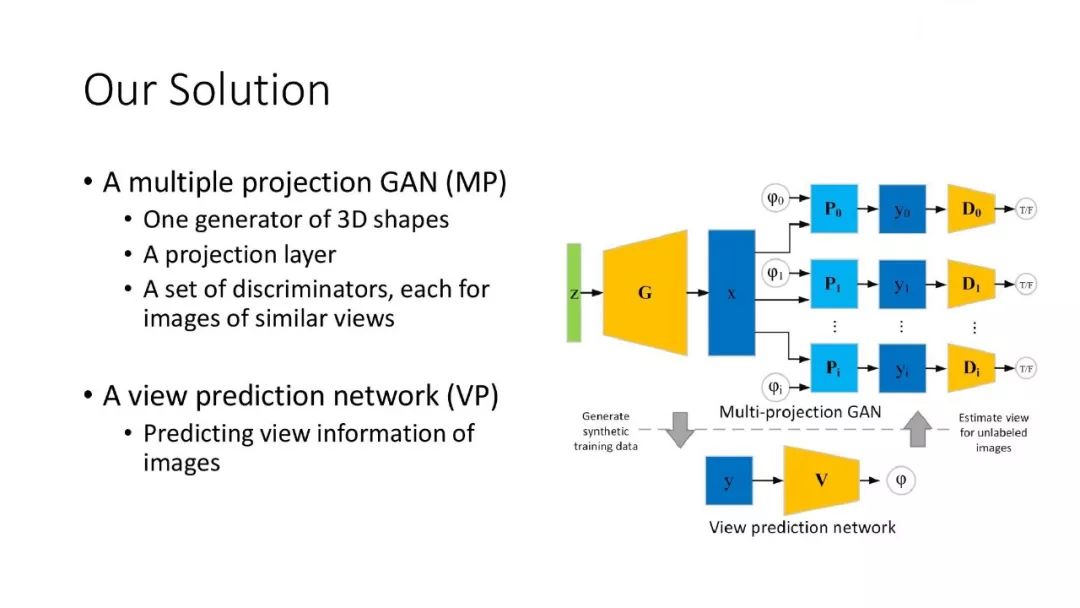
为了解决数据集和数据量的问题,我们希望能够利用大量图片来完成一些三维的学习任务,从而提供解决数据问题的一个新的思路。在今年的 CVPR 2019 工作[6]中,我们提出了一个多投影方法,可以从一类物体的图片集中学习一个三维生成网络,生成此类物体的三维形状。这个问题主要有3个挑战:第一,输入只有 2D 图像,而输出需要是 3D 形状;第二,我们没有输入图像中直接的一致性,或者说没有同一只鸟不同视角的图片,这导致很多传统的多视角重建方法不适用。第三,每张图像的视角信息也是未知的。

为了解决这些挑战,我们设计了两个模块。第一个是 Multiple Projection GAN。我们先假设每张图像的视角已知,把所有输入图像根据视角分类,然后对每个视角类训练一个鉴别器。我们训练一个生成器来生成 3D 形状,然后把它投影到不同视角上,再通过这个视角下的鉴别器比较和这个视角的图像是否一致。但图像视角是未知的,所以第二个模块就是视角预测网络。这样我们先从生成器得到 3D 形状作为视角预测网络的训练数据,训练好的视角预测网络可以用来预测 2D 图像的视角,从而把 3D 形状生成器训练得更好。这个过程不断迭代进行,就能互相优化提高,得到最终的结果。目前我们的算法利用物体的轮廓线来进行训练。
充分利用无标注数据参与训练
针对标注数据少,我们也进行了一些研究。在 SIGGRAPH 2017, 我们提出了 Self-Augment CNN 用于从单张图片中自动构建高维的表面材质贴图[7]。为解决没有足够多的标注数据(图片和对应的材质贴图)问题,我们利用了少量的标注数据和大量的材质图片,利用训练中的神经网络和绘制算法,生成大量的训练数据,来优化训练过程,有效地提高了结果质量。在今年的 SIGGRAPH ASIA 2019 上,我们也提出了一个基于无监督的三维形状的结构抽取算法[8],通过将形状抽象近似为若干个长方体盒子的表达,来抽取和构建数据集中同一类物体共有的形体结构。

小结
深度学习方法具有很好的通用性,可以自动地从大量数据中提取模型。但是,这一方法需要大量的数据,模型本身是个黑箱,难以理解。当测试数据和训练数据有偏差时,模型的效果会变差。如何利用图形学里有效的合成和模拟技术帮助深度学习,跨越图片视频和图形内容的鸿沟是值得探索的问题。
深度学习给数据驱动的图形学研究注入了新的活力,并推动着图形学应用的升级和变革。同时,也带来了挑战。展望未来,我们在如下几个方面还需要更加努力:
第一是数据。数据是推动领域发展的一大障碍。如何进一步减少数据捕捉和建模的难度,让我们可以更加有效地获取大量数据仍然是个难题。另一方面,如何突破图片、视频和三维数据之间的鸿沟也是一个值得研究的方向。只有解决了数据的问题,才能形成一个闭环,更多的数据能帮助学习更好的模型,而更好的模型又能使数据获取更加高效。
第二就是表达。已有的图形学研究已经建立了对单个图形学对象的有效表达。但是,对于所有对象构成的空间的表达还远远不够。如何有效表达与构建所有合理的三维形体的形体空间,所有表面材质的材质空间,所有衣物,人体等变形的动画空间都是非常值得探索的问题。另外,如何构建这些空间的有效的基于深度网络的表达,也是一个好的问题。
第三是深度学习的算法本身。如何结合深度网络和人的交互输入,如何结合深度学习与已有的物理先验,以及如何将不同的跨媒体输入集合在一起,如语言、图片、三维模型等,来完成真正的创作任务,仍然是没有解决的问题,也是未来的发展方向。
参考文献
1. Zhiming Zhou, Guojun Chen, Yue Dong, David Wipf, Yong Yu, John Snyder, Xin Tong, Sparse as Possible SVBRDF Acquisition, ACM SIGGRAPH ASIA 2016
2. Haoda Huang, Ling Zhao, KangKang Yin, Yue Qi, Yizhou Yu, Xin Tong, Controllable Hand Deformation from Sparse Examples with Rich Details, ACM Symposium on Computer Animation, 2011
3. Peng-Shuai Wang, Yang Liu, Yu-Xiao Guo, Chun-Yu Sun, Xin Tong: O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis, ACM Transactions on Graphics (SIGGRAPH), 36(4), 2017
4. Pengshuai Wang, Chunyu Sun, Yang Liu, Xin Tong, Adaptive O-CNN: A Patch-based Deep Representation of 3D Shapes, SIGGRAPH ASIA 2018
5. Jiapeng Tang, Xiaoguang Han, Junyi Pan, Kui Jia, Xin Tong: A Skeleton-bridged Deep Learning Approach for Generating Meshes of Complex Topologies from Single RGB Images, CVPR 2019
6. Xiao Li, Yue Dong, Pieter Peers, Xin Tong, Synthesizing 3D Shapes from Unannotated Image Collections using Multi-projection Generative Adversarial Networks , CVPR 2019
7. Xiao Li, Yue Dong, Pieter Peers, Xin Tong, Modeling Surface Appearance from a Single Photograph using Self-Augmented Convolutional Neural Networks, ACM Transactions on Graphics(SIGGRAPH), 36(4), 2017
8. Chunyu Sun, Qian-Fang Zou, Xin Tong, Yang Liu, Learning Adaptive Hierarchical Cuboid Abstractions of 3D Shape Collections, ACM SIGGRAPH ASIA 2019
你也许还想看:







