从传统银行到互联网,异地多活究竟有多难?


本文转自技术琐话订阅号,该号由蚂蚁金服高级技术专家右军维护,热爱分布式技术、研发管理、内建质量、互联网金融业务等主题。
一、背景
业务连续性管理 BCM,对于金融行业来说有着重要意义,特别是银行和证券行业,ATM或者柜面系统取不出钱就意味着挤兑,如果证券交易瞬间无法执行着意味着巨大投资损失。2011年银监会就出台了BCM监管指引,对商业银行的RTO和RPO提出了明确的量化指标。以前银行都采用同城与异地灾备的模式来解决,现在云技术、高容错的分布式技术为BC带来了新思路。越来越多的金融科技公司选择分布式技术实现无停机服务。
二、业务连续性管理
1、ISO 22301
ISO22301是已开发的一套国际框架和基准,用来引导企业识别对公司关键业务功能的潜在威胁,并建立有效的备用体系和流程,以保障利益相关者的利益。它指定了计划、实施、监督、审查和改进企业的业务连续性管理体系的具体要求,从而最大限度地减少突发事件造成的影响。ISO22301提供正规的业务连续性指南,将在突发事件发生期间和之后,保持业务运营。它的目的是尽量降低对产品和服务的影响,确保仍然能够交付产品,或及时恢复运营。该标准适用于在任何行业的各种规模的企业,尤其是在高风险或复杂的环境中运营的全球性企业,立即恢复运营对这类公司是最为重要的。
总体上人们对于小概率大影响的事件偏向于过分乐观。尤其是华人的社会文化特点是比较忌讳谈论“天灾人祸”这些我们不太认为可能发生在自己身上的事件。这种意识反映在认识方面就是要么认为风险绝对不可能发生,要么设定业务绝对不可以中断(MTPD=0和 RPO=0)的不合理或不现实持续目标。
从技术上看,衡量容灾系统有两个主要指标:RPO(Recovery Point Object)和RTO(Recovery Time Object),其中RPO代表了当灾难发生时允许丢失的数据量;而RTO则代表了系统恢复的时间。最好的情况是RPO=0,RTO=0,但显然这种情况是个理想状态。
2、国内银行业BCM要求
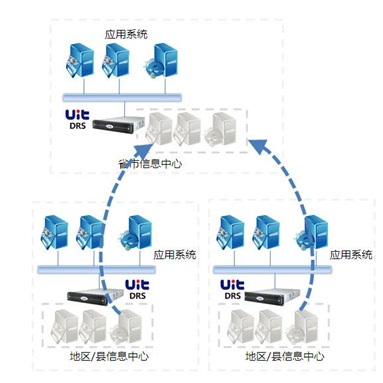
2011年银监会就出台了BCM监管指引,对商业银行的RTO和RPO提出了明确的量化指标。根据业务重要程度实现差异化管理,确定各业务恢复优先顺序和恢复指标。商业银行应当至少每三年开展一次全面业务影响分析。商业银行应当识别重要业务,明确重要业务归口管理部门、所需关键资源及对应的信息系统,识别重要业务的相互依赖关系,分析、评估各项重要业务在运营中断事件发生时可能造成的经济损失和非经济损失。原则上,重要业务恢复时间目标不得大于4小时,重要业务恢复点目标不得大于半小时。通过分析业务与信息系统的对应关系、信息系统之间的依赖关系,根据业务恢复时间目标、业务恢复点目标、业务应急响应时间、业务恢复的验证时间,确定信息系统恢复时间目标(信息系统RTO)、信息系统恢复点目标(信息系统RPO),明确信息系统重要程度和恢复优先级别,并识别信息系统恢复所需的必要资源。
3、国外银行业BCM要求
英国BSI(British StandardInstitution)出台了世界上第一个关于业务连续性管理 (BCM) 的英国标准—BS 25999,该标准的目的是在最棘手和意外的情况下保证企业的业务持续运行,从而保护企业的员工、维护企业的声誉并提供持续运营的能力。
► 该标准为在组织内了解、开发和实施业务持续性提供了基础,它包含一套基于 BCM 最佳做法的全面控制措施,涵盖整个 BCM 生命周期。
► BS 25999 分两部分制定:
第 1 部分《BCM实践指南》于2006年底公布
第 2 部分《BCM规范》于 2007 年底公布
► BS 25999 适合于各种规模及各行各业的任何组织,尤其适合在高风险环境中运营的组织,例如金融、电信、运输和公共行业。 BSI(British StandardInstitution)成立于1901年,它是世界领先的业务标准服务提供者。
4、BCM最佳实践与演练要求
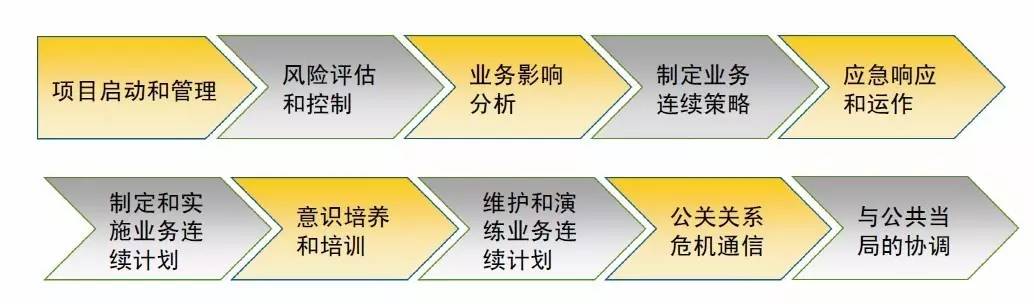
灾难恢复国际行业协会 DRII(Disaster RecoveryInstitute International)制定了业务连续管理最佳实践的十个领域。保障重要业务持续运营的一整套管理过程,包括策略、组织架构、方法、标准和程序。将业务连续性管理纳入全面风险管理体系。重要业务是指面向客户、涉及账务处理、时效性要求较高的银行业务,其运营服务中断会对商业银行产生较大经济损失或声誉影响,或对公民、法人和其他组织的权益、社会秩序和公共利益、国家安全造成严重影响的业务。将业务连续性管理融入到企业文化中,使其成为银行机构日常运营管理的有机组成部分。主要干系人要求如下图:
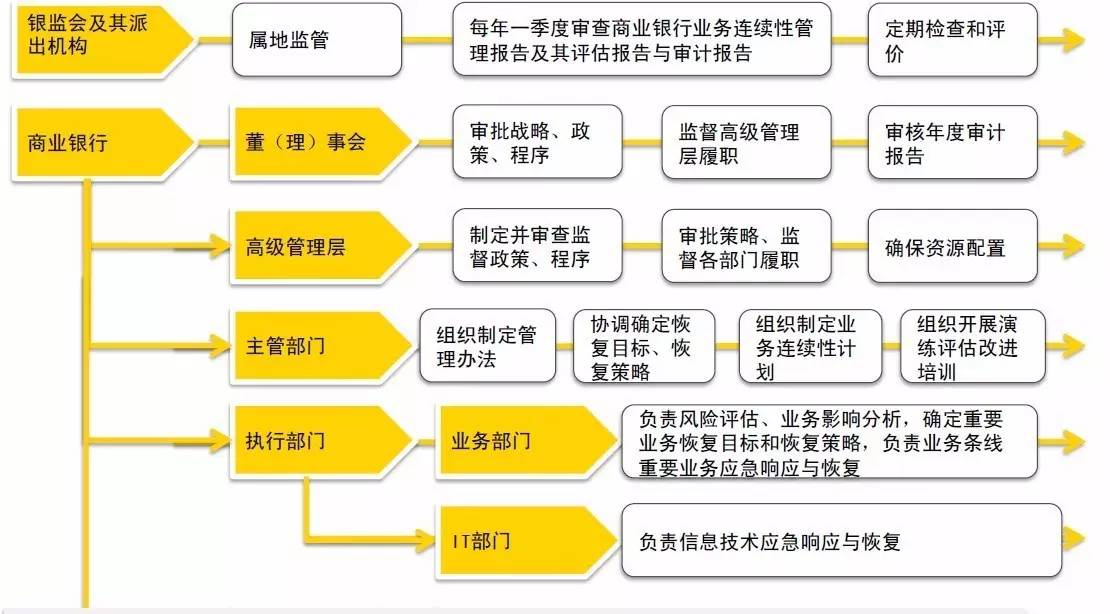
应当至少每三年对全部重要业务开展一次业务连续性计划演练,国内审计要求一般是每年至少一次。商业银行应当至少每年对业务连续性管理体系的完整性、合理性、有效性组织一次自评估,或者委托第三方机构进行评估,并向高级管理层提交评估报告。对于交易所和登记结算公司还可能每季度要求全网参与机构进行一次切换演练。商业银行在完成业务连续性计划的全行性演练后,应当在45个工作日内向监管机构提交演练总结报告。运营中断事件发生后2小时内上报,对于特别重大(I级)的运营中断事件,上报国务院。特别重大(I级)和重大(Ⅱ级)运营中断事件,银监会处置工作小组可以赴事发银行现场进行督导。必要时,可以协调国家专业技术队伍或外部专家提供技术支援。
三、建立多活保证高可用
1、目标
满足监管要求
满足全行业务连续性要求
实现一键切换
缩短计划内停机时间
我们可以看一下业界比较主流的灾备是怎么做的?最主流的灾备技术是两地三中心,数据中心A和数据中心B在同城作为生产级的机房,当用户访问的时候随机访问到数据中心A或B。之所以随便访问,因为A和B会同步做数据复制,所以两边的数据是完全一样的。但是因为是同步复制的,所以只能在同城去做两个数据中心,否则太远的话同步复制的延时会太长。
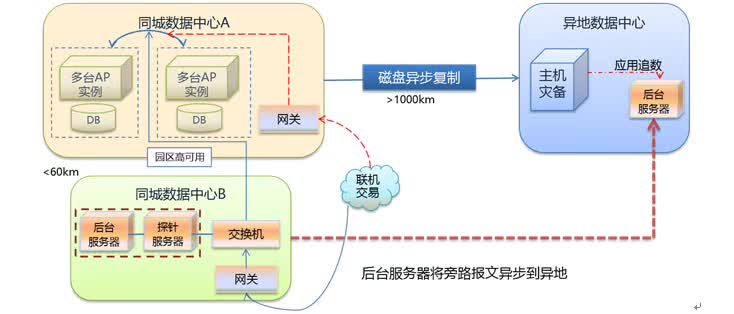
在两地三中心的概念里,一定会要求这两个生产级的数据中心是必须在同一个城市,或者在距离很近的另外一个城市也可以,但是距离是有要求的,一般要求在60公里之内,比如雄安和北京城区。异地备份数据中心通过异步数据复制来实现,银行两地三中心的特点是异地备份数据中心一般不作为关键应用宿主地,某些情况下是完全冷备,有些机构的做法是将统计分析和非关键的内部管理系统放到灾备机房。对于关键业务应用异地灾备中心不对外服务,所以用户不会访问到异地的点。原因是因为数据从生产级数据中心到异地的节点是异步去复制,所以整个有延时。这个模式在灾难到来的情况下可能会出现冷切换的问题,不能很顺畅的切换,虽然在平时的演练中,已经模拟了生产切换,但往往是众多情况中比较乐观的设定。
另外一种模式为异地多活模式,也是目前正在兴起的一种模式,对于某些大型银行的核心关键应用已经在此模式下进行了成功验证。异地多活首先是要做到同城双活或者同城多活,就是数据在同城网络环境下进行高速备份,也可以在做楼宇级同步,一般在10ms类的数据差异。异地多活需要多个跨地域的数据中心。异地多活是跨地域的,而且距离一定要做到1000公里以上的范围,其实在中国范围内全国城市都可以去部署了。降低数据同步量,同步服务根据一定业务键通过ZooKeeper路由到对应的主数据中心,备数据中心可以通过旁路报文或者异步数据同步方式补全。
2、互联网行业多活架构
最近十年,互联网发生了翻天覆地的变化,现在的互联网服务相比于银行系统有以下几个特点:访问量大、并发量大、非强一致要求、RTO和RCO要求都非常高、低成本。在这些要求的前提下,产生了一套适用于互联网行业的多活架构。
互联网的多活架构通常是双活双中心+混合云的方式,基于各种自研组件,开源组件和MySQL数据库来实现多活。
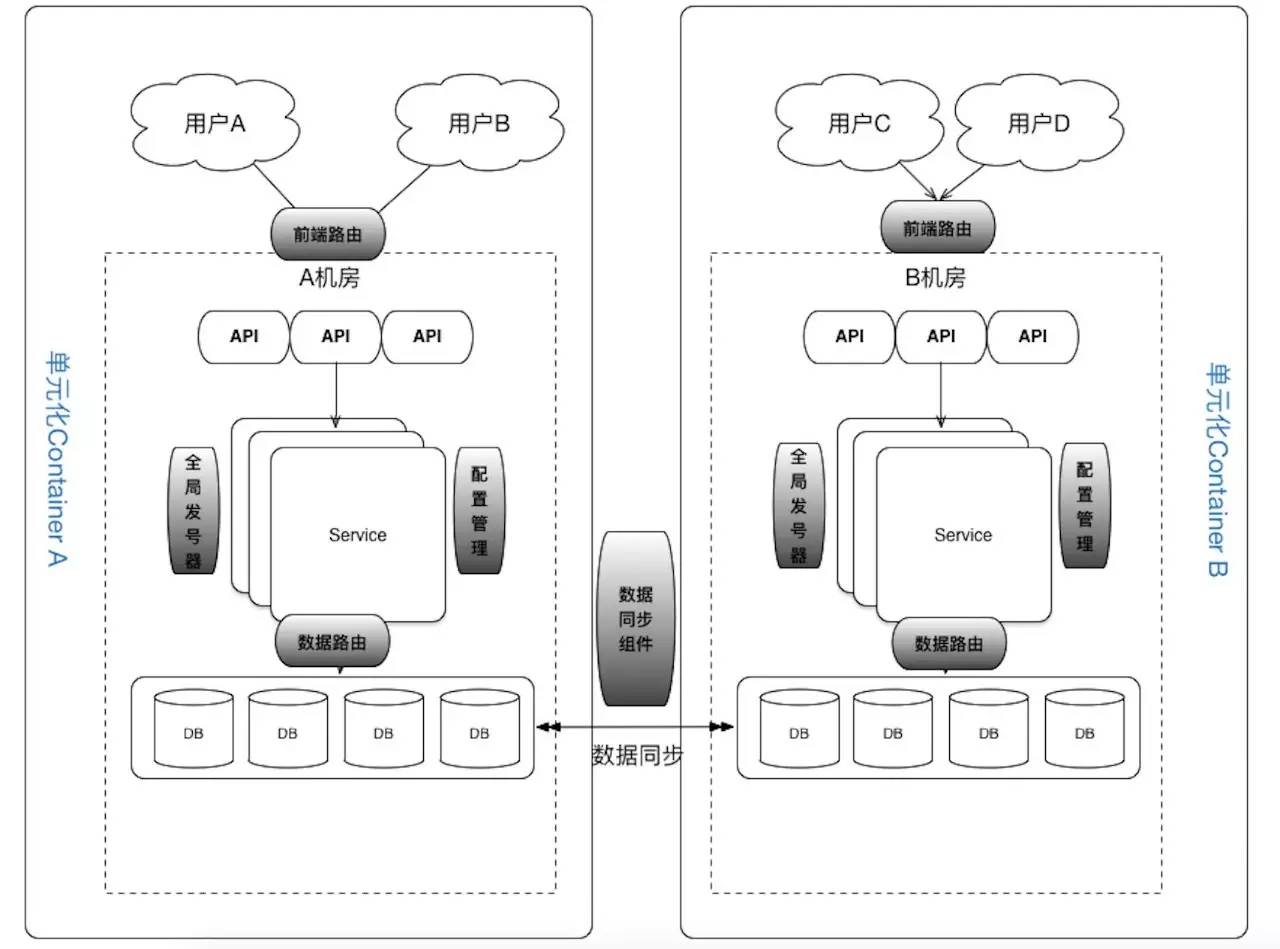
下图是多活双中心示意图。
下图是多活双中心与公有云示意图。
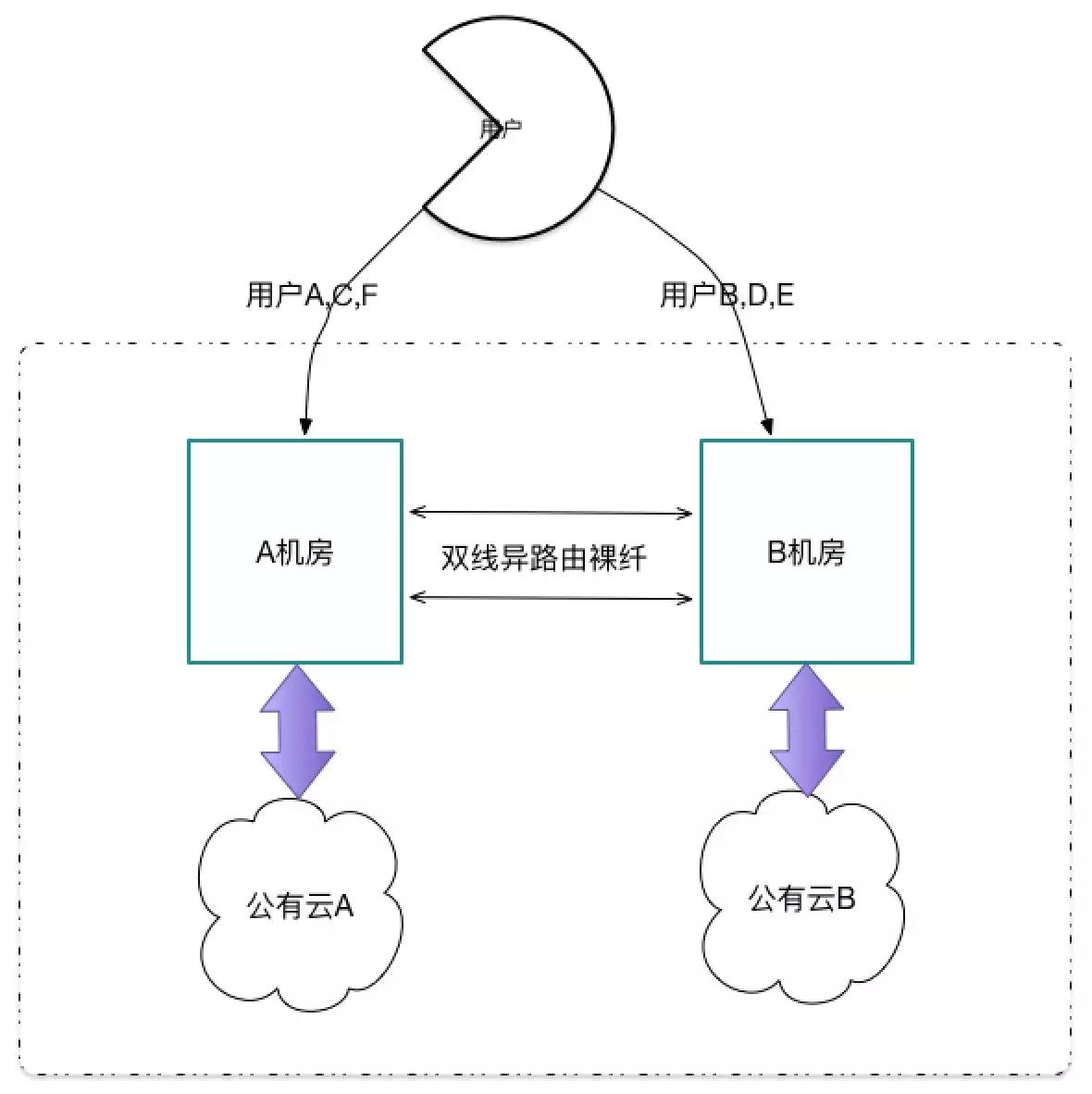
双中心主要实现业务架构的双活,任意一个机房挂掉,可以快速地切换到另外一个机房。混合云的架构主要为机房提供快速扩容的弹性能力。
在实践这个架构时,有几个关键点:
单元化
前端路由
数据路由
数据同步

单元化是多活架构的基石。单元化通常有几个维度:用户维护,功能维度,用户与功能的混合模式,作为电商,核心业务只有一个,就是购物流程。我们一定要确保购物流程的高可用。因此购物流程功能肯定不能拆分成更细的单元,如果拆分后,那么购物流程的一个单元不能用,整个购物流程就不通了。咱的双活也就失败了。所以我们会选择用户维度的单元化。
前端路由的主要目的是解决如何快速地将用户切换到正常服务的机房,传统是通过DNS来切换,但是这个切换受限于DNS缓存的生效周期,并且最多只能做到地区,很难做到细粒度的路由控制。现在常用的有两种方案:
一、通过中间件的方式,所有用户进入同一的用户端路由中间件,有中间件去决定用户走什么路由。优点是控制力非常好,缺点是如果用户量和请求量太大,中间件存在性能瓶颈。
二、通过APP端路由的方式,下发路由策略到APP端,由APP端完成用户路由,选择正确的机房。
虽然我们有一层前端路由,但是由于现在入口非常多,H5、APP、PC、小程序等等。 我们很难将所有的入口都能做到100%走路由,甚至还有一部分路程是在后台或者service层自己发起的。那么问题来了,这部分没有经过前端路由的用户数据是否会出现异常?答案是:肯定会的。
因为我们的数据是异地多份存储的,考虑到数据库的性能,我们在写入数据的时候是不能去给所有机房的这条数据上锁,也就是我们的ACID是在本地机房级别的。为了避免不同机房出现数据最终不一致的问题,我们需要限制数据的写入点,一条数据只能在一个机房写入,避免两个机房同时写一条数据导致的数据最终不一致问题。为了实现这个目的,我们需要一层数据路由。所谓数据路由,就是在程序链接数据库之前,在DAL层,或者驱动层,或者框架,ORM层等上面的一层路由。确保落地的数据是能落到正确的机房,以保证数据的最终一致性。
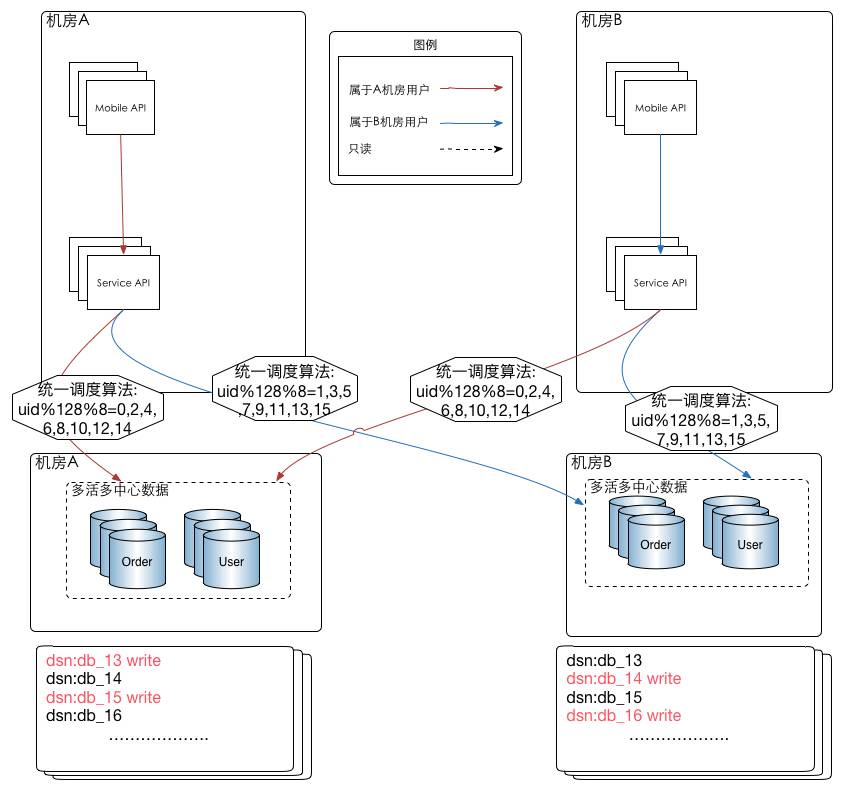
根据我们的需求,做了基础调研以后,发现有以下几种方法可以实现我们需要的数据同步功能。
基于MySQL的原生复制,做主主架构,两边都开启写入
基于PXC类似的数据库集群方案
基于OTTER的数据同步方案
自己开发一套数据库同步系统
在有现有软件满足我们需求的前提下,我们是不优先考虑自己开发的。毕竟重复自造轮子的开销不小,而且需要比较长的一个时间来验证轮子的稳定性。所以优先在前面三个方案里面做了深度调研。
OTTER:
优点:
两个机房的MySQL独立,本地机房做维护切换架构清晰,简单
如果数据同步异常的时候,推移位点可以保证数据的一致性
与MySQL版本无关,可实现低版本往高版本复制,方便升级
在公司的汇总库中使用,已经有比较深的使用经验
缺点:
引进了新的技术,存在风险,需要评估风险是否可控。
MySQL原生复制:
优点:
原生的复制协议,大家都熟悉,可控度比较好
缺点(未使用GTID):
会增加架构的复杂度,级联复制
如果数据同步异常的时候,寻找同步位点比较麻烦
如果其中一个master的机器坏掉,会导致同步的位点丢失
三机房以后架构不支持
PXC:
优点:
通过Galera实现的无共享的分布式数据库
使用同步复制,可以完全保证数据的一致性
节点自动配置
缺点:
PXC我们团队还没有使用案例,在核心的双活架构中使用,存在很大的不可控风险
Galera对网络延时比较敏感,在跨机房应用中,这是一个很大的性能瓶颈。
综合上面的分析,我们最终选择了使用OTTER来作为双活机房的数据同步组件,当然基于我们的业务场景和功能,也对OTTER做了一些小的调整。
3、分区情况下的数据合并
在单元化与数据同步方案都确定的前提下,我们来讨论一下数据合并。比如我们有A<—>B两个机房,做了双活架构,中间使用OTTER做数据同步,每张表同时只有一个机房允许写入。当一个机房的网络断掉以后,那么就出现了分区问题。这个时候,我们有两个选择。
将属于这个机房的用户切换到其他机房。
什么也不做,不能给这部分用户提供服务。
在可能的情况下,大家肯定会选择1,将用户切换到其他机房,这个本来也是我们架构的目的。但是如果切了会出现什么问题呢?最大的问题就是,挂掉机房写入的数据还没有来得及同步到其他机房。网络就断掉了,如果把用户切换到其他机房,那么他看见的数据就存在一致性问题,这个问题是我们架构选择了最终一致性和异步同步数据导致的。
如果站在业务角度来看,就是User A在订单支付以后,他所在的机房刚好处理完,还没有把处理结果,也就是订单的支付状态及信息同步到其他机房就断网了。这个时候用户切换到其他机房,那么就会看见订单未付款,如果他联系客服还好。如果他又再支付了一次,那么问题就严重了。等故障的机房好了以后,那么数据一同步,不同机房这个用户的支付信息就不一样。出现了数据的不一致性,对于用户来说,同一个商品,他却付款了两次。这种情况就只有走人工的异常处理流程了。
对于一个大型电商网站,每秒的交易量成千上万。显然全部走人工的异常处理流程是下下之策。
这个时候大家又说,那就什么都不做吧。但这样是不是和我们的初衷有点违背呢?其实还有解决方案,怎么解决?
现在又到了0和1之间的选择,0是不给那部分机房提供服务,1是要给那部分机房提供服务。可是大家想过没有,我可以给那个机房提供有损服务,也就是0和1之间。如何做?
对于已有的数据,并且是已经故障的机房产生的数据是不能更新,但是对于新写入的数据是可以更新的。这个地方可以通过全局的ID生成器来判断数据的来源,根据业务时间作为时间线的参考,从而保证只对一部分数据产生影响。
如果在没有这个机制的前提下,我建议还是什么也不做吧,至少我们有N-1/N的用户是可以正常服务的,N为机房数量。这已经达到了0月1之间,而不是0。
异地多活的case方案,虽说实现各异,但万变不离其宗。
银行之前出现过DB2复制导致数据库崩溃事件,xxx银行数十小时不可用事件其根本还是保障了数据一致性,未敢提供业务连续性部分,甚至是部分可用。因为出现风险的应对审批和管控流程很复杂;而大部分情况下在同城节点等待一定时间后实行了业务恢复。而对于互联网架构,可以采取部分有损的方案,比如90%的用户可用,是不是也是可以接受的呢?某些数据不能修改,只能做大部分业务是不是也可以接受呢?互联网提供了更多开放的可能性。
近期热文: