【新智元导读】DeepMind又对Atari游戏下手了,这回秒的是自己,把两年前的大杀四方的Atari 57模型提速了200倍!
构建在各种任务中表现良好的「通用智能体」,一开始就是强化学习的重要目标。这个问题一直是大量工作的研究对象,其性能评估经常通过观察Atari 57基准中包含的各种环境的分数来衡量。
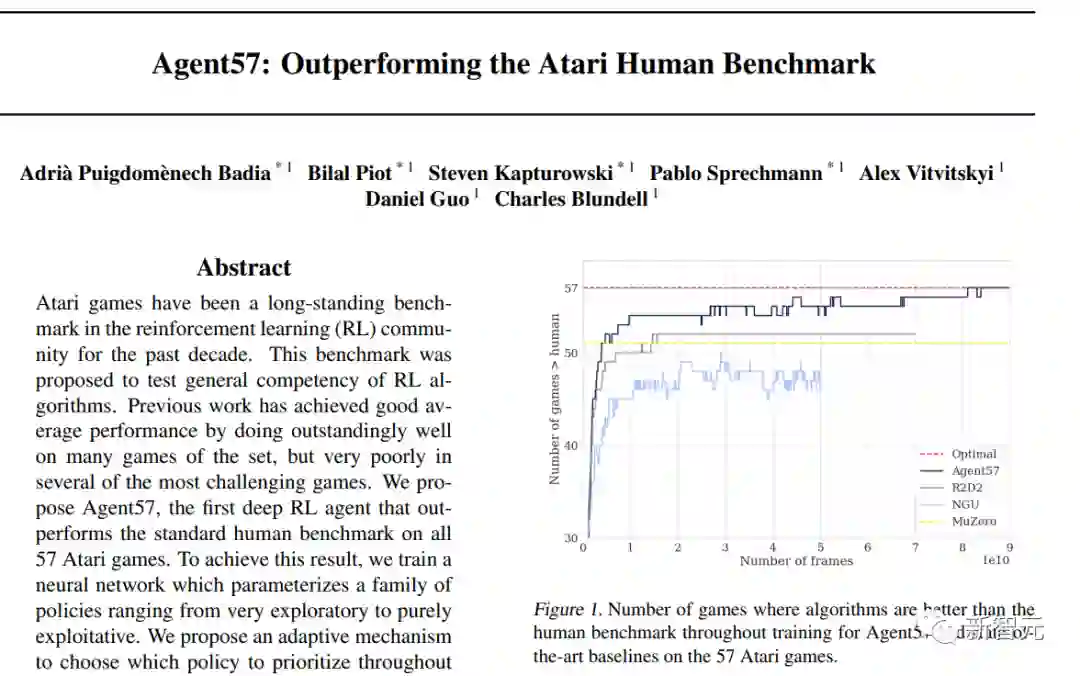
Agent57是DeepMind在2020年搞的一个Atari游戏智能体,史上首次在所有57个游戏中超过了人类基准表现,但这是以数据效率为代价的,需要近800亿帧的经验训练才能实现。
两年过去,DeepMind觉得这个智能体有「亿点点」慢了,不如以它为基础,提提速,降一降训练量,效果还不下降?
于是DeepMind的一篇新论文,带来了一个新的智能体:MEME,所需的训练经验更少,从而实现为原来的Agent57「提速200倍」的小目标。
以Agent57为起点,DeepMind采用了一系列不同的策略,以实现超越人类基准所需经验的200倍减少。我们调查了在减少数据制度时遇到的一系列不稳定因素和瓶颈,并提出了有效的解决方案,以建立一个更加强大和高效的智能体。
(1)一种近似的信任区域方法,它能够从在线网络中稳定地引导。
(2) 实行损失和优先权的归一化方案,在学习一组具有广泛规模的价值函数时提高了鲁棒性。
(3) 提出一个改进结构,采用NFNets的技术利用更深的网络,不需要规范化层
(4) 一种政策提炼方法,用于平滑瞬时贪婪政策的超时。
Atari游戏「克星」Agent57:首次全面超越人类
Agent57是第一个在所有57个Atari游戏中获得高于人类平均水平分数的算法,通用性顶满,这是DeepMind在2020年搞出来的。
不过这种通用性是以降低数据效率为代价的;在一些游戏中,需要数百亿次的环境互动才能获得高于人类平均水平的表现,在所有游戏中一共尝试了超过780亿帧,才战胜了人类的基准水平。
厉害是厉害,但是两年前搞出的东西,放到今天看不是太慢了点呢。
这回DeepMind的目标是开发一个与Agent57一样通用的智能体,但只需要少得多的环境互动,就能达到同样的效果。
智能体在每个游戏中超越人类基线所需的环境框架数量(取对数),数值越低越好。
一种方法是在与环境进行有限的互动后再测量性能,另一种方法是以尽可能少的互动来,实现训练目标的最终性能。
DeepMind的目标是打造一个Agent57的通用性一样高的新智能体,同时具有更高的数据效率,因此主要使用于后一种方法。
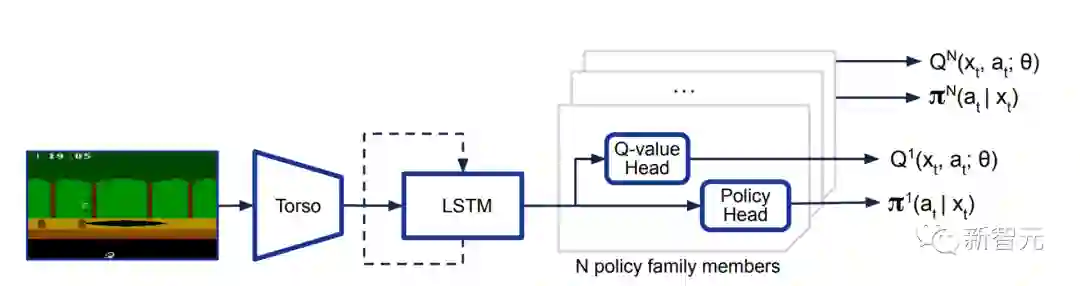
研究人员提出了一种新的智能体MEME,这是一种基于内存的高效探索智能体,MEME建立在Agent57的基础上,结合了三个主要想法。
(i) 一个基于循环重放分布式DQN(R2D2)的分布式深度强化学习框架
(ii) 用一系列的策略和永不放弃(NGU)的内在奖励机制进行探索。
(iii) 一个元控制器,通过从一系列政策中选择,在整个训练过程中动态地调整贴现因子并平衡探索和开发。
新的MEME智能体旨在提高Agent57的数据效率,主要针对Agent57的4个方面进行改善,分别是:
实现与罕见事件相关的学习信号的快速传播(A),在不同的价值尺度下稳定学习(B),改进神经网络结构(C),在快速变化的政策下使更新更加稳健(D)。
为了达到这四个目标,DeepMind采取了以下方法,与上述四点目的对应。
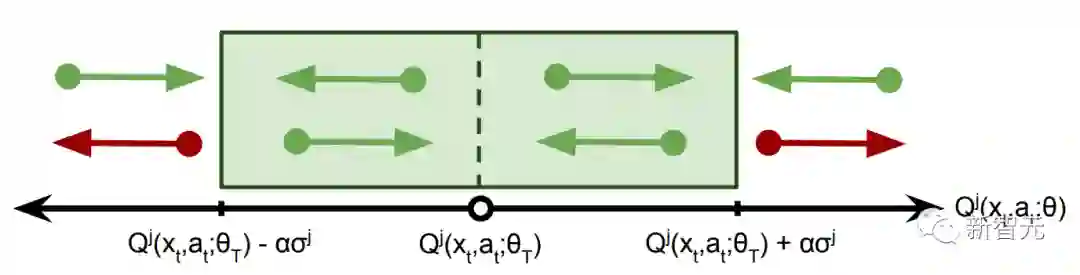
为了在保持稳定性的同时加速信号传播,我们使用了在线网络引导,并通过为价值更新引入一个近似的信任区域来稳定学习,使我们能够过滤哪些样本对损失的贡献。
这些方法旨在提高Agent57的数据效率,但这种效率的提高不能以终端性能为代价。出于这个原因,仅用10亿环境帧的预算来训练智能体。
使用这个预算可以渐进式验证智能体性能的保持效果,也就是说,在提高数据效率时,智能体会收敛并保持稳定。
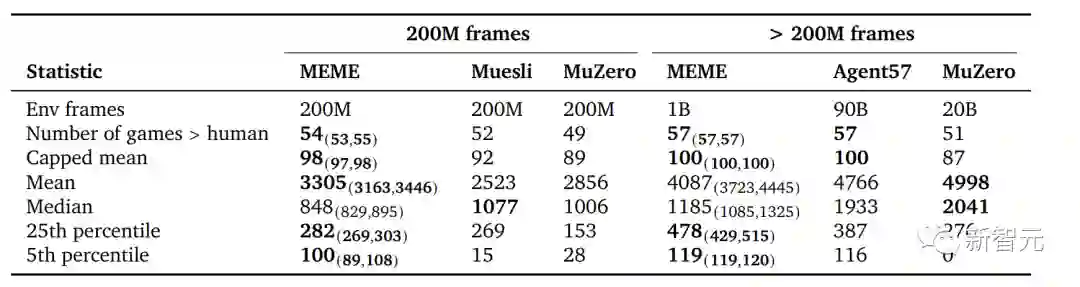
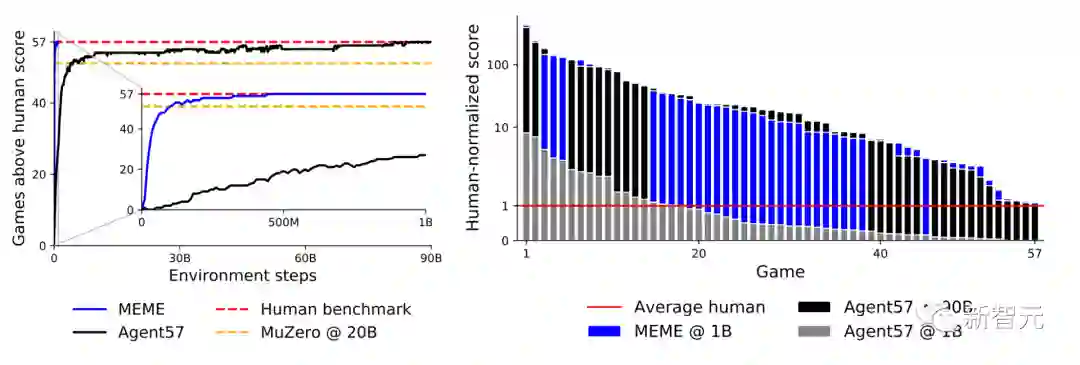
上面是在2亿帧环境训练下,以及10亿、200亿、900亿帧环境训练下,不同智能体在257个Atari游戏中表现。
其中左图为游戏得分表现高于人类基准的游戏数量。右图为不同的交互预算下,每场比赛的人类归一化分数,从高到低排序。
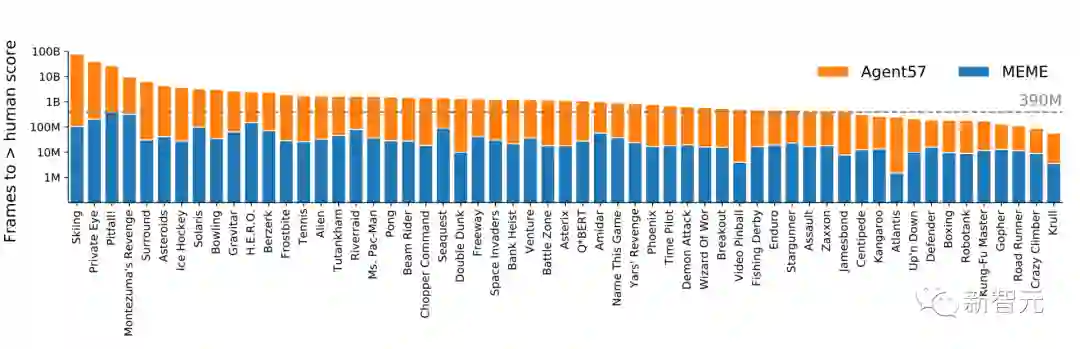
新智能体MEME在3.9亿帧尝试就超过了人类基准,比Agent57快了两个数量级,并且在将训练预算从90B减少到1B的情况下,取得了类似的最终表现。
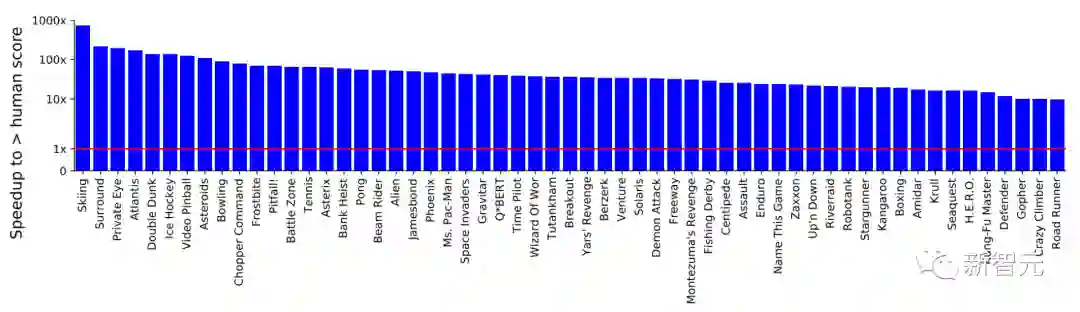
下面的蓝色柱子是MEME的表现,红线是人类玩家表现,纵轴仍然是对数。
可以看到,最高的一个游戏已经接近人类表现的1000倍,但平均表现比人类强出100倍是妥妥的了。
参考资料:
https://arxiv.org/pdf/2003.13350.pdf
https://www.deepmind.com/blog/agent57-outperforming-the-human-atari-benchmark