R-MeN: 个性化搜索的关系记忆网络Embedding


R-MeN: 个性化搜索的关系记忆网络Embedding

导语
本文是ACL20的一篇表示学习work。
文末附 Github Repo.
知识图谱Embedding对于知识图谱补全以及下游任务扮演着重要的角色,然而现有的研究方法没有充分利用三元组之间潜在的依赖关系。
本文以此为出发点,提出基于关系记忆网络的Embedding模型:R-MeN, 其中包含多头注意力机制编码,并在三元组分类以及个性化搜索任务中验证模型效果。
R-MeN: Relational Memory Network
一、背景和出发点
1.1 背景
知识图谱Embedding(知识表示学习)在早期的研究中有很多的研究工作,比如以TransE为研究起点的翻译模型,因为其简单高效,得到了学术界和工业界的青睐。但是由于其内身存在的缺点,又衍生出来一系列模型,包括TransH、TransR、TransD等,这些模型大多以简单的线性操作建模。近两年来,也慢慢的开始采用深度神经网络进行研究工作,包括ConvE、CapsE等。
1.2 出发点
上述的研究方法在知识图谱补全方面(目标是:根据已有的关系和实体推断出另外的实体)有良好的表现,然而在其他的两个实际应用中却没有捕捉三元组之间潜在的依赖关系,即三元组分类和个性化搜索。
三元组分类(Triple Classification): 判断给定的三元组是否有效。
个性化搜索(Search Personalization):对于用户给定的query,对搜索系统返回的相关文档重新排序(re-rank)。
本文以学习三元组之间潜在的依赖关系为出发点,借鉴已有的工作[2]提出R-MeN。其中采用Transformer中的多头注意力机制编码潜在依赖关系,并采用CNN对三元组解码打分。
二、R-MeN
我们先来看一下R-MeN模型结构图Fig1(这个图示很简单哈)。
M 代表一个记忆存储
g 代表一个记忆门控单元

具体包含三部分
-
输入向量 -
多头注意力编码 -
CNN解码
2.1 输入向量
我们将三元组的形式采用以下形式存储:
(subject, relation, object)
简写:(s, r, o)
众所周知,Transformer中考虑了位置向量信息,所以在此假设s, r和o之间的相对位置对推理关系是有用的,具体的输入向量如下,其中 , , 分别为 s, r, o 的向量, 为位置向量,并未提及具体怎么计算的位置向量,W 和 b分别为权重和偏置。

2.2 多头注意力编码
我们假设记忆矩阵 M 由 N 行组成,每一行是一个记忆槽位,其中 表示时间 t 上的记忆存储, 代表在时间 t 上的第 i 个记忆槽位。
具体的计算公式如下:
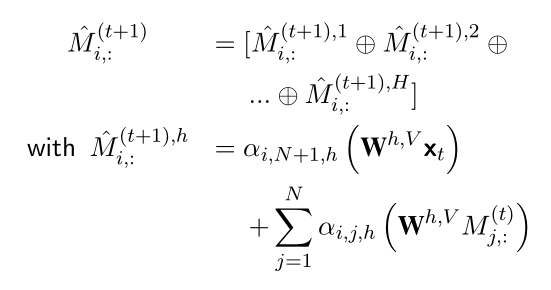

H 是多头注意力机制中 head 数量
⊕ 为向量拼接操作
α 是softmax计算得到的attention权重值
根据上述计算得到的 M 通过结构图中的MLP以及门控单元g,得到编码输出向量 。
2.3 CNN解码
根据上述的计算,我们对三元组(s, r, o)得到其编码向量( , , ),然后通过卷积运算计算这个三元组的分数。

∗ 表示局卷积运算
Ω 表示设置的过滤器集合,属于
m 是卷积窗口大小
w 是权重向量
三、实验
3.1 任务相关介绍
-
三元组分类任务
三元组分类任务是判断给定的三元组是否有效,实验的数据集采用的是 WN11和FB13,评价指标是准确率,其中有一个阈值,得分超过这个阈值为有效,否则无效,下面是数据统计: -
个性化搜索任务
1.个性化搜索(Search Personalization):对于用户给定的query,对搜索系统返回的相关文档重新排序(re-rank),返回的文档相关度越高,排名越高。
2.根据用户提交的query,用户,以及返回的文档,可以将三元组看成(query, user, document)。
3.评测数据集是SEARCH17,采用评价指标是MRR(mean reciprocal rank)和Hit@1.

3.2 实验结果
1、下面是三元组分类在两个数据集上面的实验效果,在WN11上面取得了最好的效果,在FB13上面取得了第二的效果。

2、在个性化搜索数据上面取得了最好的效果。

3、消融实验,去掉位置编码和不使用关系记忆模块。

论文代码:
https://github.com/daiquocnguyen/R-MeN
结束语
本文考虑到三元组间潜在的依赖关系,借鉴已有的工作提出R-MeN,在三元组分类任务和个性化搜素任务上验证其有效,可以作为这两个任务一个新的尝试点。
参考资料
[1] A Relational Memory-based Embedding Model for Triple Classification and Search Personalization
[2] Santoro A, Faulkner R, Raposo D, et al. Relational recurrent neural networks[C]//Advances in neural information processing systems. 2018: 7299-7310.
相关注明
以上模型图、公式、数据统计、实验结果等图片均来自上述参考资料。
推荐阅读
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



