近期必读的六篇 ICML 2020【元学习(Meta Learning)】相关论文
1、Few-shot Relation Extraction via Bayesian Meta-learning on Relation Graphs
作者:Meng Qu, Tianyu Gao, Louis-Pascal A. C. Xhonneux, Jian Tang
摘要:本文研究的少样本关系抽取,其目的是通过对句子中的一对实体进行训练,并在每个关系中添加少量的标注示例来预测其关系。为了更有效地推广到新的关系,本文研究了不同关系之间的关系,并提出利用全局关系图。我们提出了一种新的贝叶斯元学习方法来有效地学习关系原型向量(prototype vectors)的后验分布,其中原型向量的初始先验是通过全局关系图上的图神经网络来参数化得到的。此外,为了有效地优化原型向量的后验分布,我们提出使用与MAML算法相关但能够处理原型向量不确定性的随机梯度Langevin 动力学。整个框架可以以端到端的方式进行高效的优化。在两个基准数据集上的实验证明了我们提出的方法在少样本和零样本设置下相对于具有竞争性的基准模型的有效性。

网址:
https://proceedings.icml.cc/paper/2020/hash/99607461cdb9c26e2bd5f31b12dcf27a
2、Learning Attentive Meta-Transfer
作者:Jaesik Y oon, Gautam Singh, Sungjin Ahn
摘要:当任务随时间变化时,元迁移学习(meta-transfer learning)试图通过元学习和迁移学习来提高学习新任务的效率。虽然标准的注意力(attention)在各种环境中都是有效的,但由于正在学习的任务是动态的,上下文的数量可以大大减少,因此但我们质疑它在改善元迁移学习方面的有效性。在本文中,利用最近提出的元迁移学习模型--Sequential Neural Processes(SNP),我们首先从经验上证明,在神经过程( Neural Processes)的推断函数中观察到了类似的欠拟合问题。然而,我们进一步证明,与元学习环境不同,标准注意机制在元迁移环境中并不有效。为了解决这一问题,我们提出了一种新的注意机制--递归记忆重建(Recurrent Memory Reconstructionm, RMR),并证明了提供一个不断更新和重建且具有交互作用的虚构情境对于实现有效的元迁移学习注意力至关重要。此外,将RMR引入到SNP中,我们提出了注意序列神经过程RMR(ASNP-RMR),并在各种任务中证明了ASNP-RMR的性能明显优于基线模型。

网址:
https://proceedings.icml.cc/paper/2020/hash/e4a86b0d7bf4c46d7d550a92b0b2fcae
3、Meta-learning with Stochastic Linear Bandits
作者:Leonardo Cella, Alessandro Lazaric, Massimiliano Pontil
摘要:我们研究了随机线性bandits任务背景下的元学习过程。我们的目标是选择一种学习算法,该算法在从任务分布中抽样的一类bandits任务中平均表现良好。受最近关于学习到学习线性回归的工作的启发,我们考虑了一类bandits算法,它实现了著名的OFUL算法的正则化版本,其中正则化是到偏差向量的欧几里得距离的平方。我们首先从遗憾最小化(regret minimization)的角度研究了有偏差的OFUL算法的好处。然后,我们提出了两种策略来估计学习到学习环境中的偏差。理论和实验都表明,当任务数量增加,任务分配方差较小时,与孤立的学习任务相比,我们的策略具有明显的优势。

网址:
https://proceedings.icml.cc/paper/2020/hash/fbad540b2f3b5638a9be9aa6a4d8e450
4、On the Global Optimality of Model-Agnostic Meta-Learning: Reinforcement Learning and Supervised Learning
作者:Lingxiao Wang, Qi Cai, Zhuoyan Yang, Zhaoran Wang
摘要:模型无关的元学习(MAML)将元学习描述为一个双层优化问题,内层基于共享先验求解每个子任务,外层通过优化所有子任务的综合性能来搜索最优共享先验。该方法尽管在经验上取得了成功,但由于元目标(外层目标)的非凸性,对于MAML的理论上的了解仍然很少,特别是在其全局最优性方面。为了弥合这一理论与实际之间的差距,我们刻画了MAML在强化学习和监督学习中所获得的驻点( stationary points)的最优性差距,其中内层和外层问题都是通过一阶优化方法来解决的。特别地,我们的刻画将这些驻点的最优性间隙与(I)内部目标的函数几何和(Ii)函数逼近器(包括线性模型和神经网络)的表示能力联系起来。据我们所知,我们的分析首次建立了具有非凸元目标(meta-objectives)的MAML的全局最优性。

网址:
https://proceedings.icml.cc/paper/2020/hash/faacbcd5bf1d018912c116bf2783e9a1
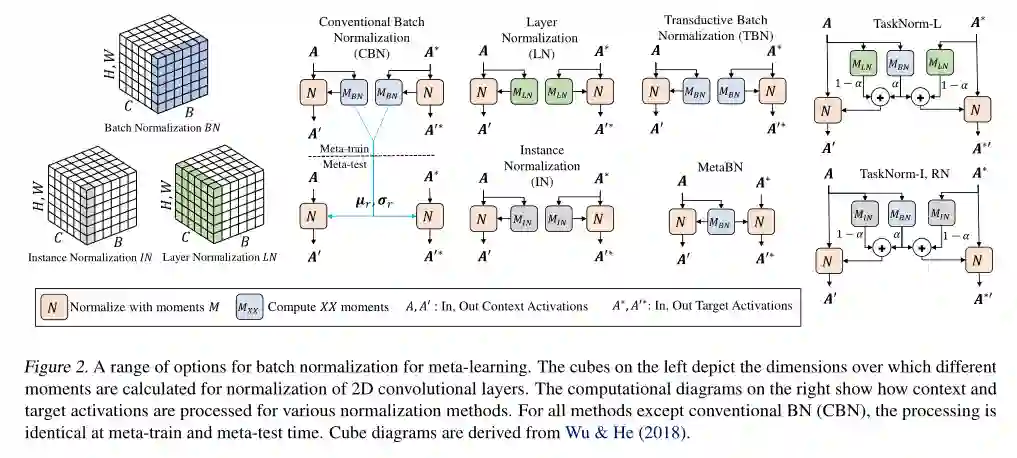
5、TASKNORM: Rethinking Batch Normalization for Meta-Learning
作者:John Bronskill, Jonathan Gordon, James Requeima, Sebastian Nowozin, Richard E. Turner
摘要:当前用于图像分类的元学习方法依赖于日益深入的网络来实现最先进的性能,使得批归一化成为元学习通道的重要组成部分。然而,元学习设置的分层性质带来了几个挑战,这些挑战可能会使传统的批归一化无效,因此需要在此设置中重新考虑归一化。我们评估了一系列用于元学习场景的批归一化方法,并开发了一种新的方法,我们称之为TASKNORM。在14个数据集上的实验表明,无论是基于梯度的元学习方法还是无梯度的元学习方法,批归一化的选择都对分类精度和训练时间都有很大的影响。重要的是,TASKNORM被发现可以持续提高性能。最后,我们提供了一组归一化的最佳实践,这些最佳实践使得可以公平比较元学习算法。
网址:
https://proceedings.icml.cc/paper/2020/hash/dc2b690516158a874dd8aabe1365c6a0
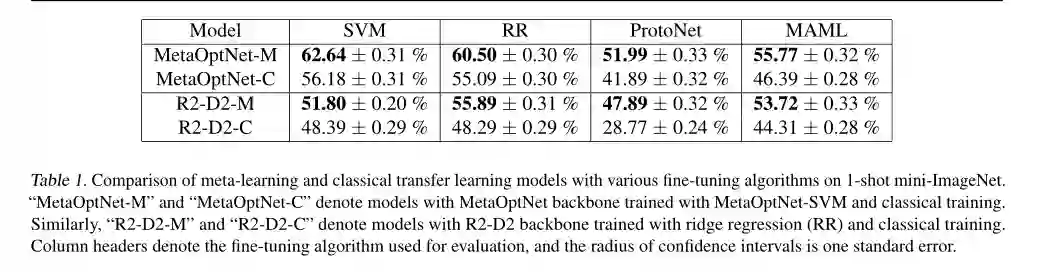
6、Unraveling Meta-Learning: Understanding Feature Representations for Few-Shot Tasks
作者:Micah Goldblum, Steven Reich, Liam Fowl, Renkun Ni, Valeriia Cherepanova, Tom Goldstein
摘要:元学习算法产生的特征提取器在少样本分类方面达到了最先进的性能。虽然文献中有丰富的元学习方法,但人们对产生的特征提取器为什么表现得如此出色却知之甚少。我们对元学习的基本机制以及使用元学习训练的模型和经典训练的模型之间的区别有了更好的理解。在这样做的过程中,我们引入并验证了几个关于为什么元学习模型表现更好的假设。此外,我们还开发了一种正则化算法,它提高了少样本分类下标准训练示例的性能。在许多情况下,我们的实验表现优于元学习,同时运行速度要快一个数量级。
网址:
https://proceedings.icml.cc/paper/2020/hash/b28d7c6b6aec04f5525b453411ff4336
请关注专知公众号(点击上方蓝色专知关注)
后台回复“ICML2020ML” 就可以获取《6篇顶会ICML 2020元学习(Meta Learning)相关论文》的pdf下载链接~