别再问如何用 Python 提取 PDF 内容了!




模块安装
pip install pdfplumber
pip install pymupdf

文字信息提取
-
利用 pdfplumber 打开一个 PDF 文件 -
获取指定的页,或者遍历每一页 -
利用 .extract_text() 方法提取当前页的文字
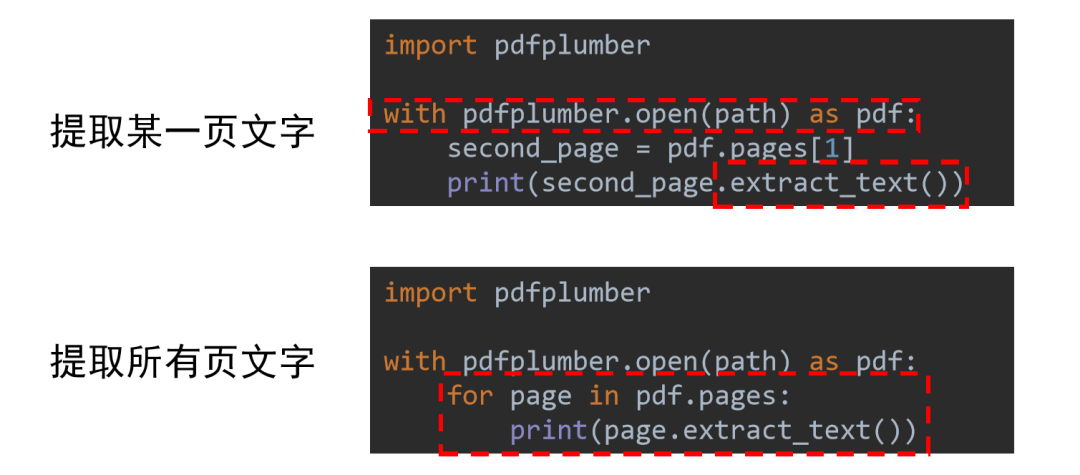

import pdfplumberfile_path = r'C:\xxxx\practice.PDF'
with pdfplumber.open(file_path) as pdf: page = pdf.pages[11] print(page.extract_text())


表格信息提取
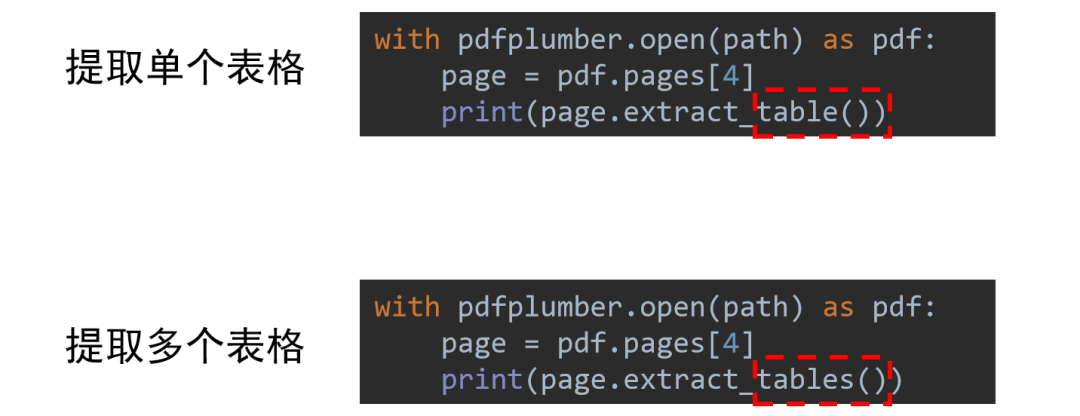
import pdfplumberfile_path = r'C:\xxxx\practice.PDF'
with pdfplumber.open(file_path) as pdf: page = pdf.pages[12] print(page.extract_table())
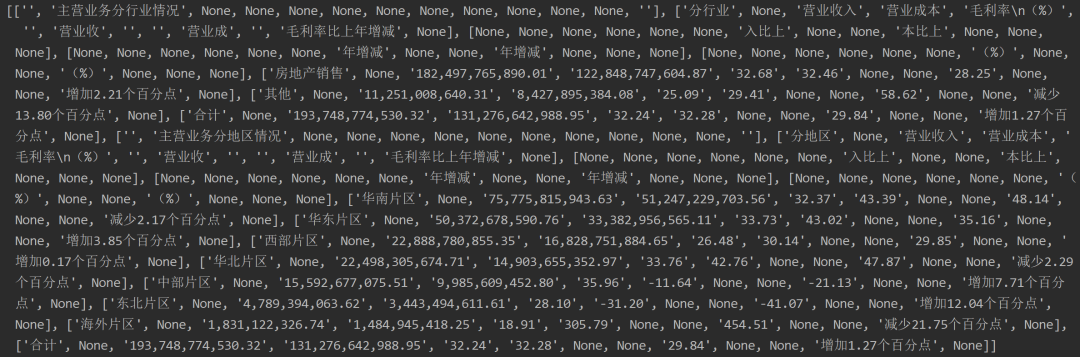
import pdfplumberfile_path = r'C:\xxxx\practice.PDF'
with pdfplumber.open(file_path) as pdf: page = pdf.pages[12] print(page.extract_tables())
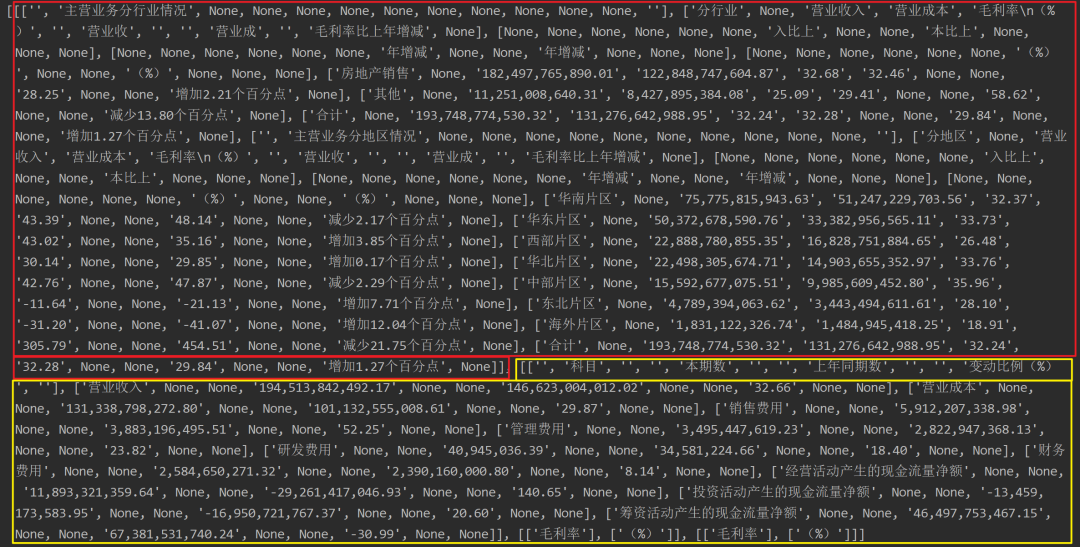

图片提取
import fitzimport reimport os
file_path = r'C:\xxx\practice.PDF'dir_path = r'C:\xxx' # 存放图片的文件夹
def pdf2pic(path, pic_path): checkXO = r"/Type(?= */XObject)" checkIM = r"/Subtype(?= */Image)" pdf = fitz.open(path) lenXREF = pdf._getXrefLength() imgcount = 0 for i in range(1, lenXREF): text = pdf._getXrefString(i) isXObject = re.search(checkXO, text) isImage = re.search(checkIM, text) if not isXObject or not isImage: continue imgcount += 1 pix = fitz.Pixmap(pdf, i) new_name = f"img_{imgcount}.png" if pix.n < 5: pix.writePNG(os.path.join(pic_path, new_name)) else: pix0 = fitz.Pixmap(fitz.csRGB, pix) pix0.writePNG(os.path.join(pic_path, new_name)) pix0 = None pix = None
pdf2pic(file_path, dir_path)

写在最后


更多精彩推荐
☞2020 最烂密码 TOP 200 大曝光,霸榜的竟然是它?
☞腾讯 AI 医学进展破解“秃头”难题,登 Nature 子刊!
☞小鹏汽车CEO疑似隔空回应偷窃技术传闻;苹果明年新款iPhone将使用增强版5nm芯片;Windows诞生35周年|极客头条
![]()
点分享
![]()
点点赞
![]()
点在看



登录查看更多
相关内容




相关VIP内容
相关资讯