清华芯片研究再获顶会MICRO加持:软件定义芯片团队出品,最佳论文提名后又一突破
杨净 发自 凹非寺
量子位 报道 | 公众号 QbitAI
最近,第53届国际微架构大会(MICRO)在线上顺利召开。
作为计算机体系结构四大顶级会议,清华大学魏少军、刘雷波团队有两篇入选该会议论文。

这是该团队既去年斩获MICRO 2019最佳论文提名后,在体系结构顶级会议上的又一重要突破。
在会议上,他们做了两篇学术报告。
分别为:
Constant-time Alteration Ternary CAM with Scalable In-Memory Architecture
一种基于可扩展存内架构并支持常数时间更新的三态内容寻址存储器。
TFE: Energy-efficient Transferred Filter-based Engine to Compress and Accelerate Convolutional Neural Networks
一种基于转换卷积核的卷积网络压缩与加速架构。
报告人分别是两篇论文一作清华大学微电子所博士生陈迪贝和莫汇宇,论文通讯作者均是刘雷波教授。
什么样的研究?
基于可扩展存内架构并支持常数时间更新的三态内容寻址存储器

△清华微电子所博士生陈迪贝同学报告论文的主要工作
三态内容寻址存储器(TCAM)凭借其不错的匹配性能,广泛应用于现代交换机和路由器的高速包分类。
然而,传统TCAM依赖于物理地址的规则优先级编码面向高速匹配设计,无法满足规则快速更新的需求。主流硬件交换机每秒仅支持大约四十至五十条规则更新,高达数百毫秒的更新延迟成为了网络性能瓶颈。
于是,基于这个问题,陈迪贝介绍了一种支持常数时间更新的三态内容寻址存储器CATCAM。

△CATCAM芯片原型
具体来说,就是提出了基于矩阵的优先级编码方法,将规则的优先级关系与地理地址解耦。
规则的优先级关系被编码在优先级矩阵中,当输入项通过匹配矩阵完成匹配后,其结果将遍历优先级的匹配规则,对应8T SRAM的位线计算逻辑。
借助双电压列写方法,新规则可插入矩阵中任意空位,实现常数时间的规则更新。
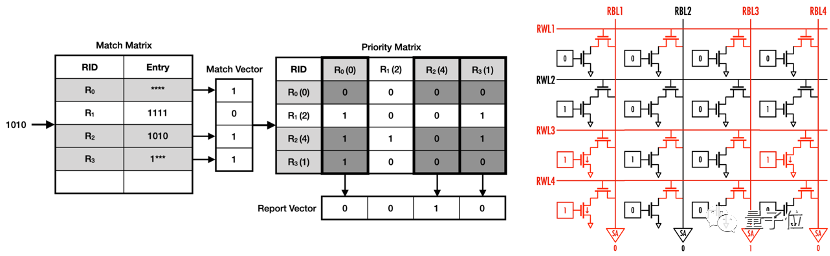
△基于矩阵的优先级编码及其存内计算实现
此外,该工作还设计了运用全局优先级编码的层次化扩展架构,采用基于区间的动态调度逻辑,在满足扩展性的同时保证了任意规模下常数时间的规则更新。
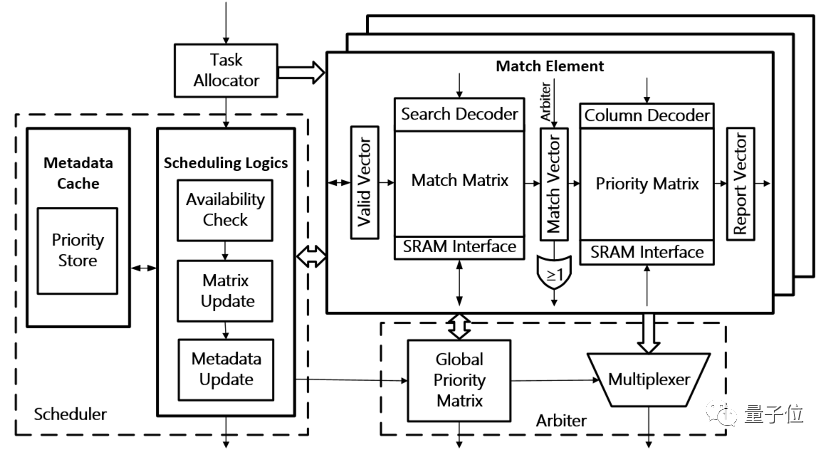
△CATCAM硬件架构
最终,通过重新设计三态内容寻址存储器的优先级机制,CATCAM消除了规则更新导致的大量现有规则迁移,在提升更新吞吐量和响应速度的同时保证了扩展性。
与现有最先进的解决方案相比,实现了至少三个数量级的加速比。
主要合作者还有李兆石、熊天柱、刘志伟、尹首一等。
基于转化卷积核的神经网络压缩和加速架构
△清华微电子所博士生莫汇宇同学报告论文的主要工作
神经网络模型的参数决定了模型大小,大网络会消耗更多的参数和计算来提高网络的拟合能力。
无论使用GPU、CPU,都需要考虑现存或内存对整个模型参数的保存能力,对面积、功耗极为敏感的边缘端设备,无法接受过多的参数和计算。
此前,就有研究人员提出转换卷积核的方法,利用结构化压缩,来使硬件运行更高效。但该方法由于存在着大量的重复计算,限制了卷积运算速度的进一步提升。
基于此,莫汇宇同学介绍了一种基于结构化压缩的神经网络加速方法,并提出了一种高效的神经网络加速架构。
在同样工艺和频率下,该架构的面积为Eyeriss结构的57.96%,功耗为其24.12%。
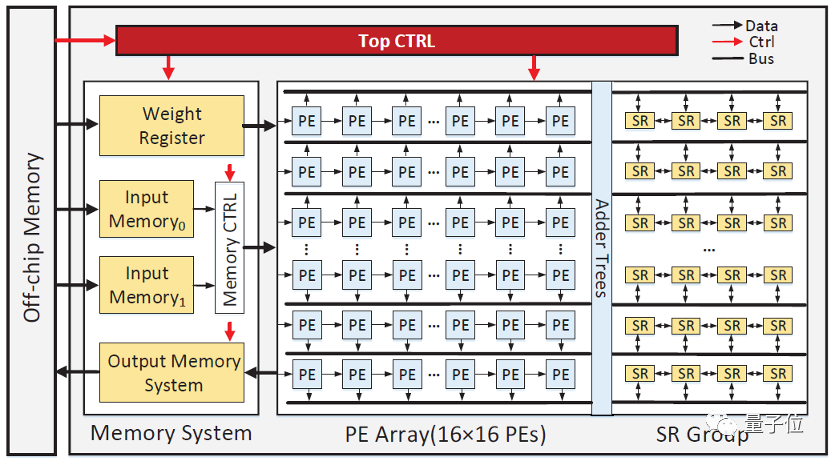
△整体硬件架构
这一方法减少了卷积核转化过程中大量冗余计算。在模型压缩率不变的情况下,有效提高了网络模型的运算速度和能效。
该工作设计了堆叠的寄存器堆,当相同权值出现在转化卷积模型卷积核的同一行时,使用寄存器堆存储每个权值与输入激活值的乘积,以及不同权值和输入激活值的局部和结果。
当处理不同的转化卷积模型时,通过与之对应的数据和控制流,将共享乘积和局部和传输到不同的计算单元,以便重复利用生成不同输出通道的结果。
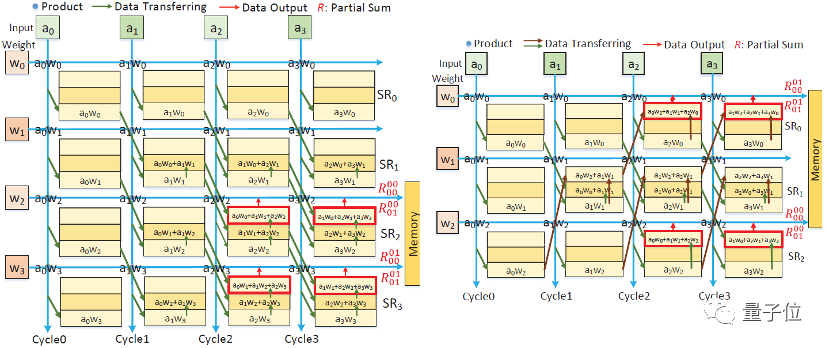
△堆叠寄存器组重复利用存转化卷积核模型运算的中间局部和
此外,研究人员还设计了一种有效的存储调度方式。
在整个卷积处理过程中,输入数值按行输入,每行都会同时和卷积核的所有行卷积运算,其卷积结果将会分别存储在单独的存储模块中。
这样,存储单元里的卷积结果将会被不同输出结果共同使用,且该结果将会随着卷积过程进行循环更新。
即能重复利用存储模块,也能提高卷积结果的复用率。
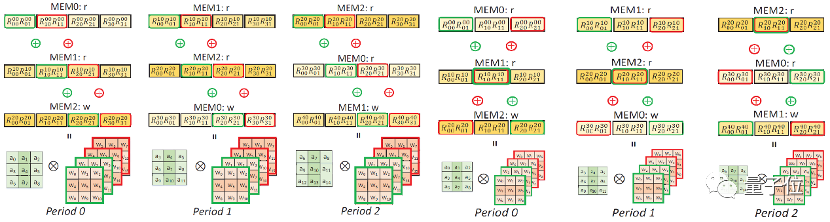
△整行卷积结果的复用
最终,实验结果表明,与最优的神经网络架构在经典VGGNet网络上相比,该架构实现了最大4×的模型压缩,2.72×的加速及10.74×的能效提升。
主要合作者还有朱文平、栗强、尹首一等。
清华魏少军、刘雷波团队
关注芯片、体系结构等领域的伙伴对这一团队并不陌生。
清华大学魏少军教授、刘雷波教授团队在软件定义芯片领域取得了多项重要技术突破。
相关技术在多项国家重大工程中得到批量应用,曾获国家技术发明二等奖、教育部技术发明一等奖、电子学会技术发明一等奖、中国发明专利金奖、世界互联网大会15项世界互联网领先科技成果等。

△魏少军教授
在JSSC/TIFS/TPDS等领域顶级期刊上发表论文200多篇,在ISCA/HOT CHIPS/DAC/VLSI等领域顶级会议发表论文20余篇。
去年8月,他们的研究成果登上高性能芯片顶级会议Hot Chips,这是31年来中国高校首篇一作论文。官方介绍称,他们这一技术有望解决中国95%以上服务器CPU面临的芯片安全难题。
一个月之后,在顶会MICRO上,他们获得了MICRO 2019最佳论文提名,这是MICRO 52年历史上第二次有亚洲高校及机构获得该奖项。
就在上个月,他们以「后量子密码硬件加速」技术登上第22届密码硬件与嵌入式系统会议(CHES)。这是国际密码芯片和物理安全方向最重要的顶会之一。
— 完 —
「百度AI开发系列课」免费报名
5分钟上手,10分钟定制高精度AI模型,硬核百度EasyDL,小白也能学!
10.21日起,3期公开课带你0门槛轻松学AI开发、实现AI模型训练与部署!扫码添加量子位小助手(qbitbot12)、加入课程直播群吧~▽
p.s.完成课堂任务还有机会赢取李彦宏新书《智能经济》哦~


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !



