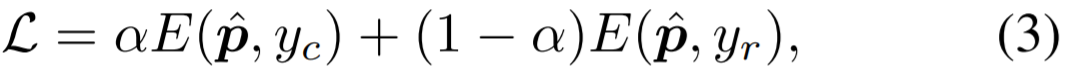加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
本文揭示了再平衡方法解决长尾问题的本质及不足:虽然增强了分类器性能,却在一定程度上损害了模型的表征能力。针对其不足,本文提出了一种针对长尾问题的新型网络框架——双边分支网络(BBN),以兼顾表征学习和分类器学习。通过该方法,旷视研究院在细粒度识别领域权威赛事 FGVC 2019 中,获得 iNaturalist Challenge 赛道的世界冠军。该网络框架的代码已开源。
论文名称:BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
论文链接:http://www.weixiushen.com/publication/cvpr20_BBN.pdf
开源代码:https://github.com/Megvii-Nanjing/BBN
导语
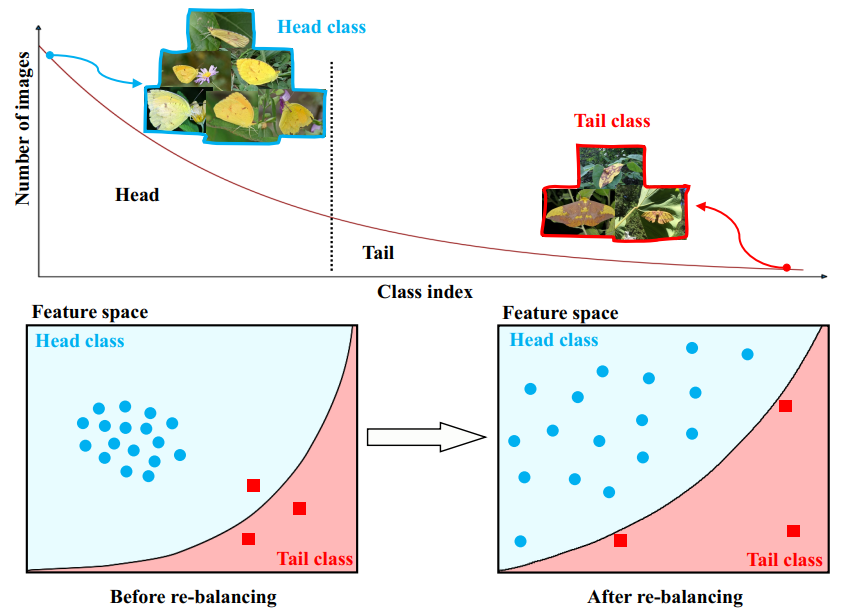
随着深度卷积神经网络(CNN)研究的推进,图像分类的性能表现已经取得了惊人的进步,这一成功与高质量的大规模可用数据集密不可分,比如 ImageNet ILSVRC 2012、MS COCO 和 Places 数据集。这些视觉识别数据集的类别标签分布是大致均匀的,相对而言,真实世界的数据集却总是存在偏重情况,呈现出长尾分布模式,即少量类别(头部类别)具有大量数据,而大部分类别(尾部类别)仅有少量样本,如图 1 所示。
另外,计算机视觉社区在近些年中构建出了越来越多反映真实难题的长尾数据集,如 iNaturalist、LVIS、RPC。当处理这样的视觉数据时,深度学习方法不足以取得优良的识别精度,原因有二:一是深度模型本身就需要大量数据,二是长尾数据分布存在极端的类别不平衡问题。
图 1:真实世界的大规模数据集往往会展现出长尾分布现象
长尾分布这种极端不平衡会导致分类训练难以得到很好的效果,尤其是对于长尾类别而言。类别再平衡策略可让模型在长尾问题上的准确度表现更好。本文揭示出,这些策略的机制是显著提升分类器学习,但同时又会在一定程度上出人意料地损害已学的深度特征的表征能力。
如图 1 所示,经过再平衡之后,决策边界(黑色实弧线)往往能更准确地分类尾部数据(红色方块)。但是,每个类别的类内分布会变得更加松散。在过去的研究中,处理长尾问题的显著且有效的方法是类别再平衡,它可以缓解训练数据的极端不平衡问题。
一般来说,类别再平衡方法有两类:1)再采样方法,2)代价敏感再加权方法。这些方法可对 mini-batch 中的样本进行再采样或对这些样本的损失进行重新加权,以期望能够和测试分布维持一致,从而实现对网络训练的调整。因此,类别再平衡可有效地直接影响深度网络的分类器权重更新,即促进分类器的学习。正是因为这个原因,再平衡方法可以在长尾数据上取得令人满意的识别准确度。
但是,尽管再平衡方法最终能得到良好的预测结果,这些方法仍会产生不良影响,即会在一定程度上出人意料地损害深度特征的表征能力。
简介
在本文中,旷视研究院首先通过验证实验,对前述论点进行了证明。具体来说,为了解析再平衡策略的工作方式,把深度网络的训练过程分为两个阶段:1)表征学习;2)分类器学习。
表征学习阶段,旷视研究院采用的传统的训练方法(交叉熵损失)、再加权和再采样这三种学习方式来习得各自对应的表征。
然后,在分类器学习阶段,采用的做法是先固定在前一阶段收敛的表征学习的参数(即主干网络层),然后再从头开始训练这些网络的分类器(即全连接层),这个过程同样使用了上述三种学习方法。
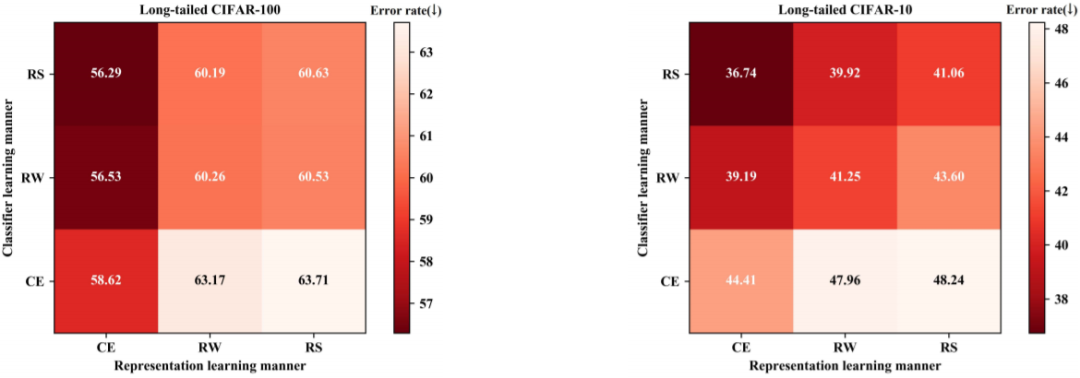
图 2:在 CIFAR-100-IR50 和 CIFAR-10-IR50 这两个大规模长尾数据集上采用不同的表征学习和分类器学习方法所得到的 top-1 错误率
图 2 给出了在 CIFAR-100-IR50 和 CIFAR-10-IR50 这两个基准长尾数据集上所得到的预测错误率。很明显,当表征学习的方式固定时,再平衡方法可以合理地实现更低的错误率,这表明它们确实可以促进分类器学习。
另一方面,通过固定分类器的学习方式,简单的交叉熵损失相比再平衡策略反而可以取得更低的错误率,这说明再平衡策略在一定程度上损害了表征学习。从该角度出发,旷视研究院提出了一种统一的双边分支网络(BBN),可以同时兼顾表征学习和分类器学习,大幅提升了长尾问题的识别性能。
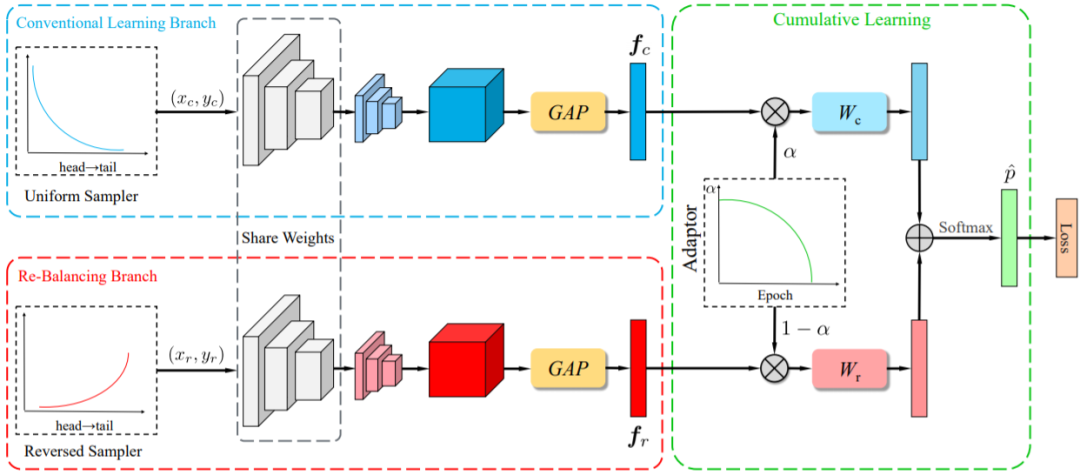
如图 3 所示,BBN 模型由两个分支构成,即常规学习分支(Conventional Learning Branch)和再平衡分支(Re-Balancing Branch)。总体而言,BBN 的每个分支各自执行其表征学习和分类器学习任务。顾名思义,常规学习分支为原始数据分布配备了典型的均匀采样器(Uniform Sampler),可用于为识别任务学习通用的表征;再平衡分支则耦合了一个逆向的采样器(Reversed Sampler),其目标是建模尾部数据。
接着,再通过累积学习(Cumulative Learning)将这些双边分支的预测输出聚合起来。累积学习使用了一个自适应权衡参数 α,它通过「适应器(Adaptor)」根据当前训练 epoch 的数量自动生成,可以调节整个 BBN首先从原始分布学习通用的特征,然后再逐渐关注尾部数据。此外,α 并没有阶跃式地从1变为0,而是逐渐降低,使得两个分支在整个训练过程可以同时维持学习状态,让模型在迭代后期关注尾部数据的同时不损害已习得的通用表征。
论点证明
为探究再平衡策略对表征学习和分类器学习的影响,旷视研究院设计了一个两阶段的验证实验,把深度学习模型解耦为了表征提取器和分类器。
具体来说,第一阶段使用普通的训练方法(即交叉熵)或再平衡方法(即再加权/再采样)作为学习方法训练一个分类网络;然后,获取对应于这些学习方法的不同类型的表征提取器。
在第二阶段,固定在前一阶段学习到的表征提取器的参数,再使用前述的三种学习方法从头开始重新训练分类器。如图 2 所示,旷视研究院在 CIFAR-100-IR50 数据集(这是不平衡比为 50 的长尾 CIFAR-100)上通过对照实验对上述论点进行了验证。可以看到,在每个数据集上,基于不同的排列组合可得到 9 组结果。基于此,可得到两个方面的观察结果:
分类器:可以发现,当应用同样的表征学习方法时(比较竖直方向上三个单元格的错误率),RW/RS 的分类错误率总是低于 CE,这是因为它们的再平衡操作会对分类器权重的更新过程进行调整,以与测试分布相匹配;
表征:当应用同样的分类器学习方法时(比较水平方向上三个单元格的错误率),可以惊讶地发现 CE 的错误率总是低于 RW/RS。这说明使用 CE 进行训练可以获得更好的表征,RW/RS 在一定程度上损害了习得的深度特征的表征能力。
此外,如图 2 左图所示,通过在表征学习上应用 CE 和在分类学习上应用 RS,在 CIFAR-100-IR50 的验证集上得到的错误率最低。
方法
如图 3 所示,BBN 模型包含 3 个主要组件:1)常规学习分支,2)再平衡分支,3)累积学习策略。
具体来说,常规学习分支和再平衡分支分别用于表征学习和分类器学习 。这两个分支使用了同样的残差网络结构,除最后一个残差模块,两个分支的网络参数是共享的。旷视研究院为这两个分支分别配备了均匀采样器和逆向采样器,得到两个样本 (x_c, y_c) 和 (x_r, y_r) 作为输入数据,其中前者用于常规学习分支,后者用于再平衡分支。将这两个样本送入各自对应的分支后,通过卷积神经网络和全局平均池化(GAP)得到特征向量
![]() 和
和
![]() 。
在这之后是旷视研究院专门设计的累积学习策略,可在训练阶段在两个分支之间逐渐切换学习的「注意力」。具体的做法是使用一个自适应权衡参数 α 来控制 f_c 和 f_r 的权重,经过加权的特征向量 αf_c 和 (1−α)f_r 将分别被发送给分类器
。
在这之后是旷视研究院专门设计的累积学习策略,可在训练阶段在两个分支之间逐渐切换学习的「注意力」。具体的做法是使用一个自适应权衡参数 α 来控制 f_c 和 f_r 的权重,经过加权的特征向量 αf_c 和 (1−α)f_r 将分别被发送给分类器
![]() 和
和
![]() ,然后再通过逐元素累加的方式将其输出整合到一起。这个输出 logit 的公式为:
其中
,然后再通过逐元素累加的方式将其输出整合到一起。这个输出 logit 的公式为:
其中
![]() 是预测得到的输出,即
是预测得到的输出,即
![]() 。对于每个类别 i ∈ {1, 2, . . . , C},softmax 函数可通过下式计算该类别的概率:
然后,用 E(·, ·) 表示交叉熵函数,并将输出概率分布记为
。对于每个类别 i ∈ {1, 2, . . . , C},softmax 函数可通过下式计算该类别的概率:
然后,用 E(·, ·) 表示交叉熵函数,并将输出概率分布记为
![]() 。则 BBN 模型的加权交叉熵分类损失为:
而且,能以端到端方式训练整个 BBN 网络模型。关于双边分支结构的设计与累积学习策略的细节信息请参阅原论文。
。则 BBN 模型的加权交叉熵分类损失为:
而且,能以端到端方式训练整个 BBN 网络模型。关于双边分支结构的设计与累积学习策略的细节信息请参阅原论文。
实验
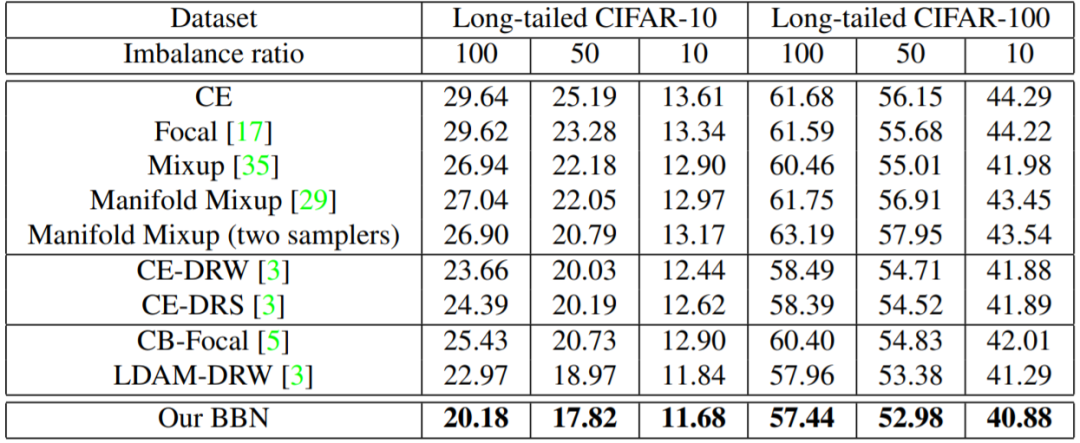
旷视研究院在不平衡比分别为 10、50、100 的三个长尾 CIFAR 数据集上进行了广泛的实验,结果如下所示:
表 1 在不同设置的 CIFAR 数据集上比较了 BBN 模型与其它多种方法。
表 1:在长尾 CIAFR-10 和 CIFAR-100 数据集上的 ResNet 的 top-1 错误率
可以看到,新提出的 BBN 模型在所有数据集上均取得了最佳结果,对比的方法包括之前最佳的方法 CB-Focal 和 LDAM-DRW。
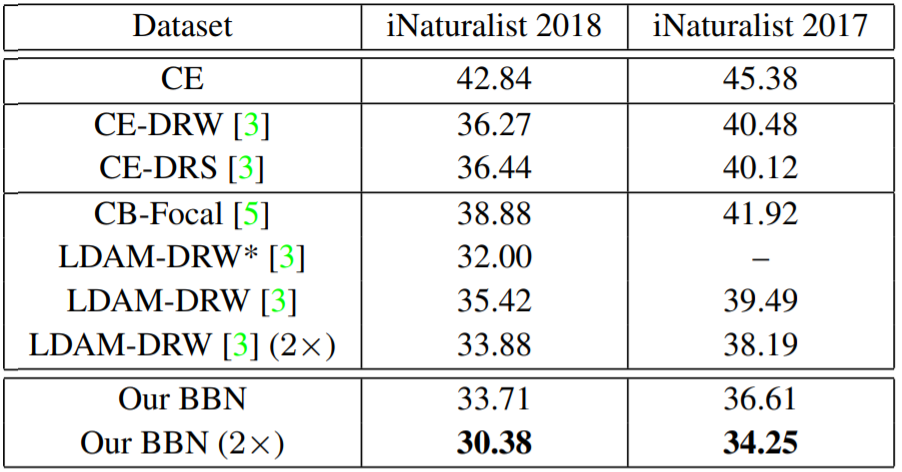
表 2 则给出了在 iNaturalist 2018 和 iNaturalist 2017 这两个大规模长尾数据集上的结果。
表 2:ResNet-50 在 iNaturalist 2018 和 iNaturalist 2017 上的 top-1 错误率
和前面的结果一样,新提出的 BBN 仍然更优。此外,由于 iNaturalist 数据集规模很大,旷视研究院还使用 2× 调度器进行了实验。同时,为了公平地比较,研究者也使用 2× 调度器训练了之前最佳的 LDAM-DRW。可以明显看到,使用 2× 调度器的 BBN 的表现显著优于未使用 2× 调度器的 BBN 的表现。此外,BBN(2×) 的表现也明显优于 LDAM-DRW (2×)。
结论
本文首先探索了类别再平衡策略对深度网络的表征学习和分类器学习产生的影响,并揭示出这些策略虽然可以显著促进分类器学习,但也会对表征学习产生一定的负面影响。基于此,本文提出了一种带有累积学习策略的双分支网络 BBN,可以同时考虑到表征学习与分类器学习,大幅提升长尾识别任务的性能。
经过广泛的实验验证,旷视研究院证明 BBN 能在长尾基准数据集上取得最佳的结果,其中包括大规模的 iNaturalist 数据集。未来,旷视研究院还将继续探索 BBN 模型在长尾检测问题上的应用,并希望通过 BBN 开源项目促进社区在长尾问题方面的探索和研究。
[1] Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. In CVPR, pages 9268–9277, 2019.
[2] Haibo He and Edwardo A Garcia. Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering, 21(9):1263–1284, 2009.
[3] Chen Huang,Yining Li,Chen ChangeLoy, and Xiaoou Tang. Learning deep representation for imbalanced classification. In CVPR, pages 5375–5384, 2016.
[4] Xiu-Shen Wei, Peng Wang, Lingqiao Liu, Chunhua Shen, and Jianxin Wu. Piecewise classifier mappings: Learning fine-grained learners for novel categories with few examples. IEEE Transactions on Image Processing, 28(12):6116–6125, 2019.
[5] Nathalie Japkowicz and Shaju Stephen. The class imbalance problem: A systematic study. Intelligent Data Analysis, 6(5):429–449, 2002.
[6] Xiu-Shen Wei, Quan Cui, Lei Yang, Peng Wang, and Lingqiao Liu. RPC: A large-scale retail product checkout dataset. arXiv preprint arXiv:1901.07249, pages 1–24, 2019.
[7] Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. Learning to reweight examples for robust deep learning. In ICML, pages 1–13, 2018.
[8] Li Shen, Zhouchen Lin, and Qingming Huang. Relay back-propagation for effective learning of deep convolutional neural networks. In ECCV, pages 467–482, 2016.
[9] Yu-Xiong Wang, Deva Ramanan, and Martial Hebert. Learning to model the tail. In NeurIPS, pages 7029–7039, 2017.
[10] Xiu-Shen Wei, Jian-Hao Luo, Jianxin Wu, and Zhi-Hua Zhou. Selective convolutional descriptor aggregation for fine-grained image retrieval. IEEE Transactions on Image Processing, 26(6):2868–2881, 2017.
40万奖金的AI移动应用大赛,参赛就有奖,入围还有额外奖励
![]()
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()

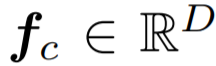 和
和
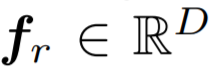 。
。
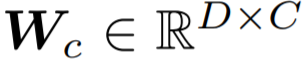 和
和
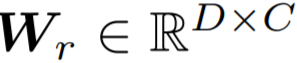 ,然后再通过逐元素累加的方式将其输出整合到一起。这个输出 logit 的公式为:
,然后再通过逐元素累加的方式将其输出整合到一起。这个输出 logit 的公式为:
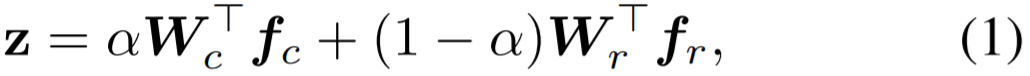
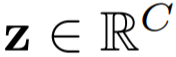 是预测得到的输出,即
是预测得到的输出,即
 。对于每个类别 i ∈ {1, 2, . . . , C},softmax 函数可通过下式计算该类别的概率:
。对于每个类别 i ∈ {1, 2, . . . , C},softmax 函数可通过下式计算该类别的概率:
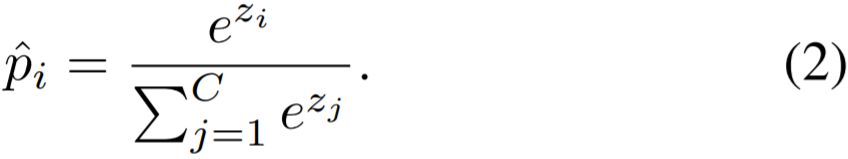
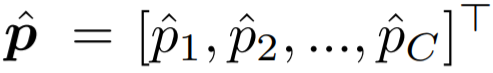 。则 BBN 模型的加权交叉熵分类损失为:
。则 BBN 模型的加权交叉熵分类损失为: