![]()
作者 | 蒋宝尚
2020年7月9日,在世界人工智能大会上,陶大程教授(澳大利亚科学院院士)在科学前沿全体会议上和观众连线,并做了《预见·可信 AI》的报告。
在报告中,陶教授回顾了深度学习理论的发展,并介绍了最近在深度学习理论研究方面的进展,具体包括,为什么深层结构优于浅层结构?为什么随即梯度下降算法对于理解深度学习的泛化能力非常重要?以及深度学习模型的损失曲面有什么样的几何性质?
注:陶大程,人工智能和信息科学领域国际知名学者,澳大利亚科学院院士、欧洲科学院(Academia Europaea)外籍院士、ACM Fellow(Association for Computing Machinery,美国计算机学会)、IEEE Fellow,悉尼大学工程学院教授、优必选悉尼大学人工智能中心主任、优必选 AI首席科学家。此外,他还是 IEEE SMC 认知计算技术委员会前主席。
以下是演讲全文,AI科技评论做了不改变原意的整理。
深度学习让很多领域进入了“自动化革命”的时代,例如机器视觉、自然语言处理、语音识别等。
如上动图,展示了目前深度学习在机器视觉领域的一些进展,例如物体检测、实例分割、场景分割、道路检测、文字检测和识别等等。以上进展给我们的启示是:深度学习的存在确实让之前非常困难的机器视觉任务变得容易。
而现在存在的问题是:许多应用领域对AI算法的安全性有很高的要求,例如自动驾驶系统,一个微小的错误都有可能会导致致命的灾难。
由于现有算法缺乏适当的理论基础,我们对这些算法“为什么能成功”并没有准确的把握;另外,AI应用领域也持续遇到一些挑战,这都使得大众对AI的信任不断减少。
那么如何解决这个问题呢?根本性的解决方法是建立完整的人工智能的理论基础。
人工智能理论基础的进展,在深度学习方面,主要有两点
:首先传统机器学习的基础理论相对比较成熟和完善;其次,深度学习主导了第三次的人工智能热潮,驱动了很多的实际应用落地。
目前深度学习的基础理论研究还处在初级阶段。
深度学习的成功主要建立在实验之上,缺乏坚实的理论基础。
那么理论分析深度学习算法为什么如此困难?
这里引用一句MIT 托马斯教授的一句话,“从前,我们需要比模型参数更多的训练数据才能得到有意义的拟合”。
那么深度学习的情况是什么样的呢?如上图对比,左边是2017年效果最好的神经网络,大概有几千万个参数;右边是现在常用的数据集,CORD-19数据库只有6000个数据点。ImageNet作为机器视觉领域最大的数据库之一仅有1000多万个数据点。其他大多机器视觉领域的数据集只有几万个数据点。即使是ImageNet这样的大规模数据库,与深度学习的参数相对比,数量仍然不足。
为何深度学习模型如此过度参数化,但表现却如此优异?当前有研究工作从模型容量和复杂度的角度出发对神经网络进行了分析。过去统计学习也有结论:
如果模型的容量或者复杂度较小,那么模型的泛化能力就能够得到保证。
如果可以证明深度学习模型的容量(或者复杂度)与参数的数量不直接相关,就能在一定程度上解释“为什么深度学习如此成功”。
先看传统机器学习中复杂度度量的常用工具:VC维。2017年Harvey等人从VC维的角度出发,分析了神经网络的泛化性能,得到了两个上界。这两个上界直接和模型的参数数量相关,这就使得泛化误差的上界很大,甚至比损失函数的最大值还要大,因此这样的上限是非常松的。这样的结论在一定程度上告诉我们:从VC维角度出发,论证过程会非常难。但是,作为开拓性的研究,这个工作的意义很大。
2018年,Golowich等人用Rademacher复杂度得到了一个泛化误差的上界。结论表示:上界不直接与模型的规模相关,但是和模型参数的模以及网络的深度相关。
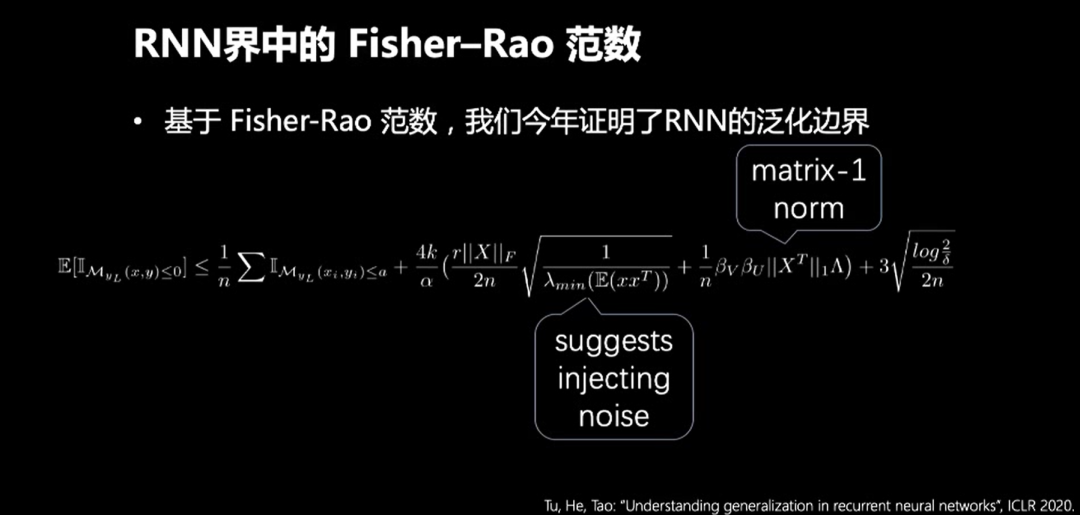
2019年,Liang等人探索了Fisher-Rao范数,得出的结论是Fisher-Rao有许多良好的性质,例如Fisher-Rao范数的不变性。
今年,我们团队在ICLR 2020中发表了一篇使用Fisher-Rao范数证明RNN的泛化边界。Fisher-Rao和matrix-1 norm可以有效的帮助我们控制上限的尺度。这给我们带来的启发是:
在训练样本中增加一些噪音,可以提升模型的泛化能力,但是不能加入太多的噪音,因为会使训练误差变大。
我们的Fisher-Rao Norm依赖一个关于梯度的结构化引理。该引理表示:参数的模可以被梯度的大小控制住,该引理帮助我们有效刻画了梯度对深度学习模型泛化能力的影响,也帮助我们更好的理解泛化能力和训练能力之间的关系。
基于模型容量,模型复杂度的泛化误差的上界,通常表明小模型的泛化能力比较好。但是这和深度学习的实验和表现不非常一致。例如,Neyshabur在2015年的工作和Novak在2018年的实验证明了:“
大型网络不仅表现出良好的测试性能,并且随着网络规模的增加,泛化能力也在提升
。”另外。在2016年Canziani统计了一些竞赛中的模型和实验也得到了相同的结论。
从信息论的角度出发,我们团队得到了一个泛化误差的上界。其中的理论分析主要基于三个方面,首先和传统的浅层学习模型,例如支撑向量机不同,深度神经网络具有层级特征映射结构,这样的层级结构能有效帮助网络避免过拟合。
其次,传统的泛化误差上界是通过模型的函数空间复杂度进行估计,忽略了数据的分布,仅考虑模型函数空间中最坏的情况。
最后,实际中模型的泛化能力和数据分布是相关的。受到最近信息论和自适应数据分析的研究的启发,我们用神经网络学到的特征和最后一层神经网络参数的互信息,来bound泛化误差。
最终,我们得出的结论是:
网络的输出对于输入的依赖性越小,其泛化能力就越强。
在信息论中强数据处理不等式的保证下:只要网络的每一层的映射是不可逆的(也就是信息衰减),那么神经网络所学习到的特征和最后一层参数的互信息,就会随着层数的增加而逐渐减少。因此网络越深,模型的泛化能力也就变得越强。
随着网络层数的增加,在映射过程中模型会丢失对于数据拟合有用的信息。在这种情况下,训练数据集拟合误差就会变大。因此,深度网络的泛化能力虽然逐渐增强,但是要想整个神经网络的性能好,还需要保证训练误差足够小。
尽管如此,信息衰减的要求是非常强的,毕竟现在的深度学习中,我们经常需要引入skip connections,因此这方面的研究还要进一步深入。
另外,也需要明确一下:神经网络的容量非常庞大,甚至具有通用的近似能力。1989年的三个独立工作,同时证明了神经网络的“通用近似定理”。
Hornik在1993年也证明了,如果网络无限宽,即使浅层网络也可以近似任何连续函数。2017年,Lu等人也证明了有限宽的神经网络也具有通用近似能力,而在今年他的团队又证明了神经网络可以近似任何分布。
这些例子都说明了一个问题:
如果参数可以任意取的话,神经网络网络的容量会非常庞大。
这里又出现一个问题,参数是不是可以任意取?
目前神经网络的参数都是通过随机梯度下降算法(SGD)学到的,所以参数的取值并不是“任意的”。因此虽然神经网络本身的假设空间非常大,但是随机梯度下降只能探索到空间中的一小部分。这样来看,随机梯度下降算法是解释深度学习泛化能力的关键。
我们在2019年NeurIPS上的文章指出:随机梯度下降的优化过程形成路径可以用偏微分方程进行表示。SGD优化的过程可以描述为:T+1时刻的参数-T时刻的参数=学习率*函数的梯度。显然,这个表达式就是偏微分方程。由于Batch是随机的,初始化是随机的,对于梯度的建模也引入了噪声。这意味着,当前的梯度等于整个数据集上梯度的平均值加上一个不确定的噪声。目前大家会假设是该噪声是正态(高斯)分布,最近也有研究用别的分布来建模噪声。
SGD的优化路径可以用随机过程的稳态分布来给随机梯度下降算法学到的模型进行建模。然后,我们就可以利用PAC-Bayes得到泛化误差的上界。
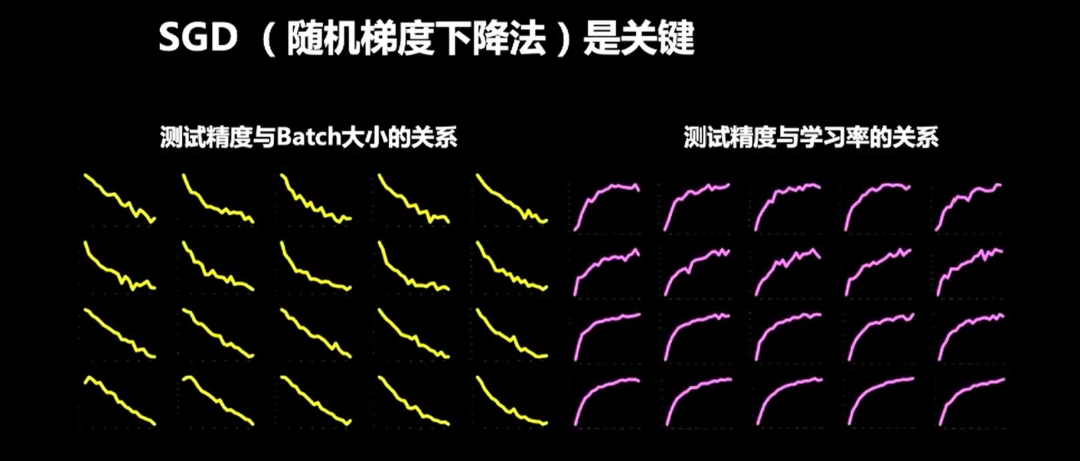
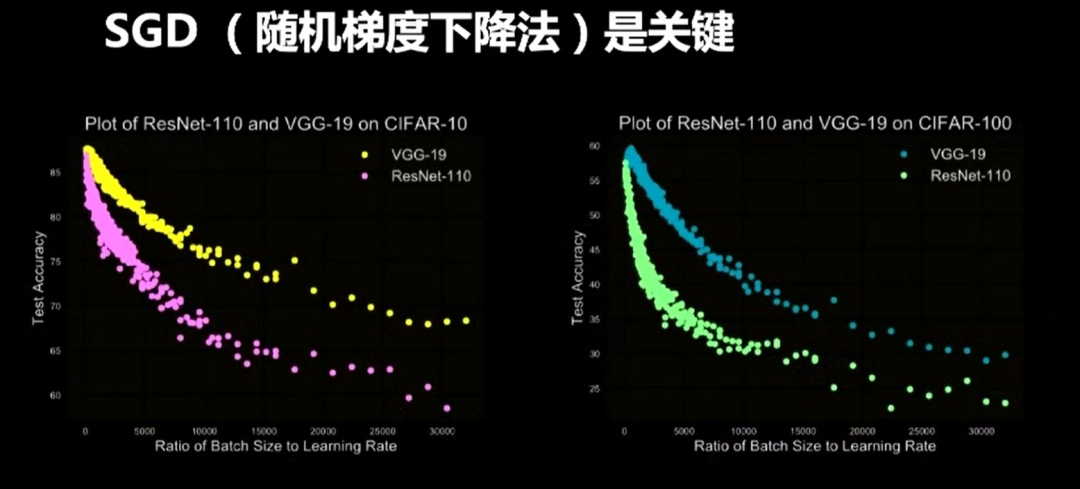
由此,我们得出结论:泛化能力和学习率与Batch Size之间存在正比例相关关系。这个关系也说明了超参数的调整有一定的规律可循。
我们在CIFAR-10和CIFAR-100上基于ResNet和VGG两个网络训练了1600个模型,来验证“正相关”关系。上图是所有模型的测试精度分析,每一个小图由20个模型画成。我们用测试精度表示泛化能力,因为训练精度几乎是100%。左边显示学习率不变的条件下,测试精度和Batch大小之间的关系:随着Batch Size的增加,测试精度下降。右边是Batch Size不变的条件下,测试精度和学习率之间的关系:随着学习率的增加,测试精度提升。
上图是测试精度和Batch Size、学习率之间的比值的关系,每种颜色各由400个模型画成。显然,随着比值的增加,测试精度下降。
所以,利用偏微分方程对SGD的优化轨迹进行建模,对理解深度学习非常有价值。同时这也要求我们深入理解损失曲面的几何结构,因为
损失曲面的几何结构决定了偏微分方程在损失曲面上的轨迹。
这主要有两方面的原因:首先,随机偏微分方程包含了损失函数以及损失函数的各阶导数,所以损失曲面的几何结构直接影响了随机偏方程的结构。
其次,损失曲面也决定了随机偏微分方程的边际条件,因此损失曲面决定了随机梯度下降算法“输出的解”的性质。
因此透彻理解损失曲面的几何结构,对于研究深度学习的优化以及泛化能力非常重要。
在2018年Novak等人用实验说明:神经网络的泛化性能和损失曲面的几何结构相关:神经网络的泛化性能和输入空间的区域个数相关。
然而,非线性激活函数使得损失曲面极端的非凸,并且不光滑,这使得优化算法的理论分析非常困难。这种混乱的局面使得目前已有的优化算法的理论分析变得非常困难。比如,为什么凸优化的算法可以去优化神经网络这种非凸的问题?
但是,深度学习模型在很多实际问题中,的确有很好的使用效果。由此可以想象,混乱的局面之下可能存在某种未被发现的秩序。
关于损失曲面的几何结构,对于线性网络(即激活函数是线性函数的网络)现有的结论是:线性网络在平方损失函数下,所有的局部极小值都是同样好的,也即局部最小值就是全局最小值。如果非线性网络也能找到类似的性质,那么后面对于深度学习的理论分析就会比较顺利。
现有的研究对线性和非线性有着有趣的辩论,例如非线性是不重要,因为非线性网络继承了线性网络的性质。但是另一些文章则指出实际情况并非如此。
在2019年,Yun等人证明了单层的神经网络损失曲面有无穷多的次优局部极小值。此结论需要有4个条件保证:1.单个隐藏层;2.平方损失;3.一维输出;4.两段线性激活。
我们今年在ICLR 2020的文章中,显著扩展了这四个条件:1.任意深度;2.任意可微分损失;3.任意维输出;4.任意分段线性激活。
那么之前猜测的秩序有可能是什么?Soudry和Hoffer在2018年指出,ReLU网络的损失平面被划分为若干光滑的多线性区域。
我们在文章中进一步指出:
在每一个区域中,每一个局部极小值都是全局最小值;在每一个区域中,所有的局部极小值也汇聚成了一个极小值峡谷。
第三,一个峡谷上所有的点构成一个等价类;第四,此等价类还存在着平行峡谷;第五,
所有的等价类构成一个商空间。
其实,这里的第二条性质就解释了模式连接。即随机梯度下降找到的局部极小值的附近,存在着一些经验风险差别很小的点,并且这些点连成了一条线。很遗憾,目前这些几何性质只对单个隐藏层的神经网络成立,对于多隐藏层的深度网络,还有很多工作要做。
在陶大程教授分享之后。复旦大学类脑人工智能科学与技术研究院院长、上海脑科学与类脑研究中心副主任冯建峰,上海科技大学信息科学与技术学院教授、执行院长虞晶怡和陶大程教授进行交流。
虞晶怡:陶院士这次报告非常精彩,
整个报告聚焦于理论层面,当前有很多工作利用深度学习进行快速的3D估算,从而加速整个的判断过程。您对此有何看法?
陶大程:
对于物体跟踪和检测,三维重构可以提供很多非常有价值的信息:(1)物体在场景中的位置信息,帮助提高基于二维图像的物体跟踪和检测的定位精度;(2)物体和物体之间的前后顺序信息(在实际三维场景中,物体处在不同的layer上),帮助减少遮挡的影响并提升区分不同物体的能力;(3)通过三维重构,我们可以获得更加精细的物体的特征,帮助提高被跟踪检测的物体的表达能力。
今天的深度学习成功的主要原因,在于其很强的特征表达能力。目前深度学习的泛化能力在理论上有很多问题还没有解答。
对于这些问题的回答,需要大家更加深入的研究深度学习的基础理论:让我们充分理解深度学习什么时候能成功,让我们有效界定某一个特定的深度模型的使用范围、让我们知道该如何选择训练的技巧、以及让我们更加高效的去调整参数等等。
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiangbaoshang@yanxishe.com
击"阅读原文",直达“ICML 交流小组”了解更多会议信息。