ICML 2020 | 提升神经网络架构搜索稳定性,UCLA提出新型NAS算法
作者:陈相宁
可微网络架构搜索能够大幅缩短搜索时间,但是稳定性不足。为此,UCLA 基于随机平滑(random smoothing)和对抗训练(adversarial training),提出新型 NAS 算法。

论文:https://arxiv.org/abs/2002.05283
代码:https://github.com/xiangning-chen/SmoothDARTS
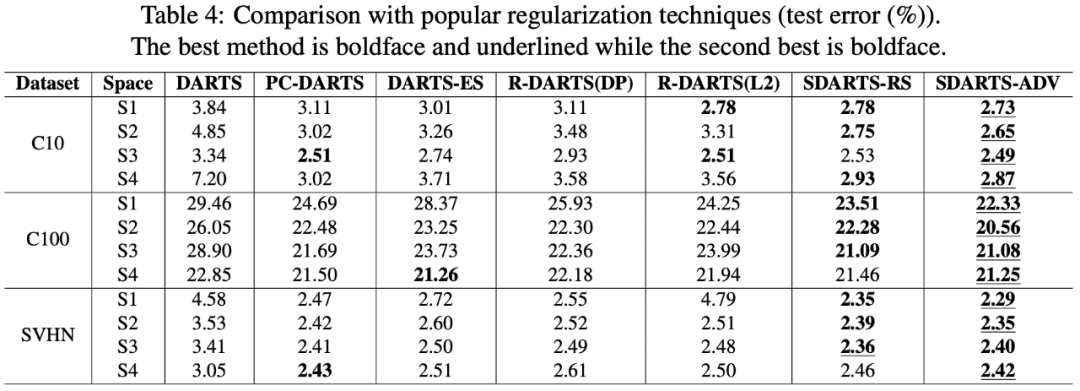
提出 SDARTS,大幅提升了可微架构搜索算法的鲁棒性和泛化性。SDARTS 在搜索时优化 A 整个邻域的网络权重,而不仅仅像传统可微 NAS 那样只基于当前这一组参数。第一种方法优化邻域内损失函数的期望,没有提升搜索时间却非常有效。第二种方法基于整个邻域内的最差损失函数(worst-case loss),取得了更强的稳定性和搜索性能。
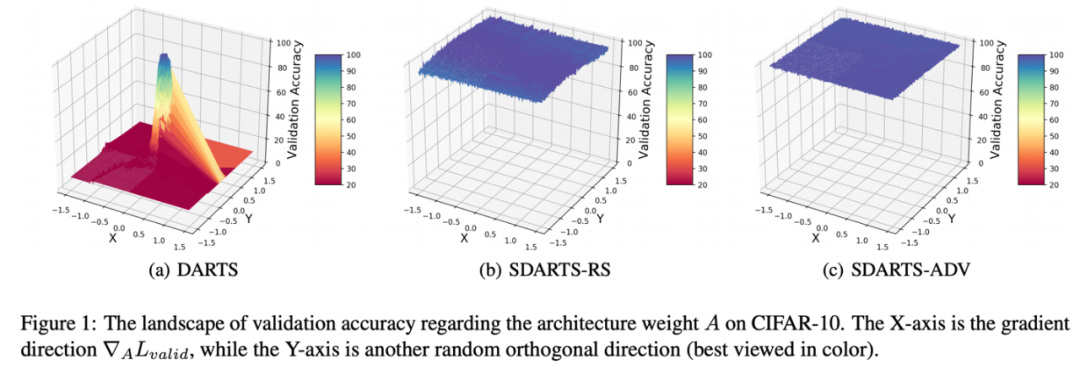
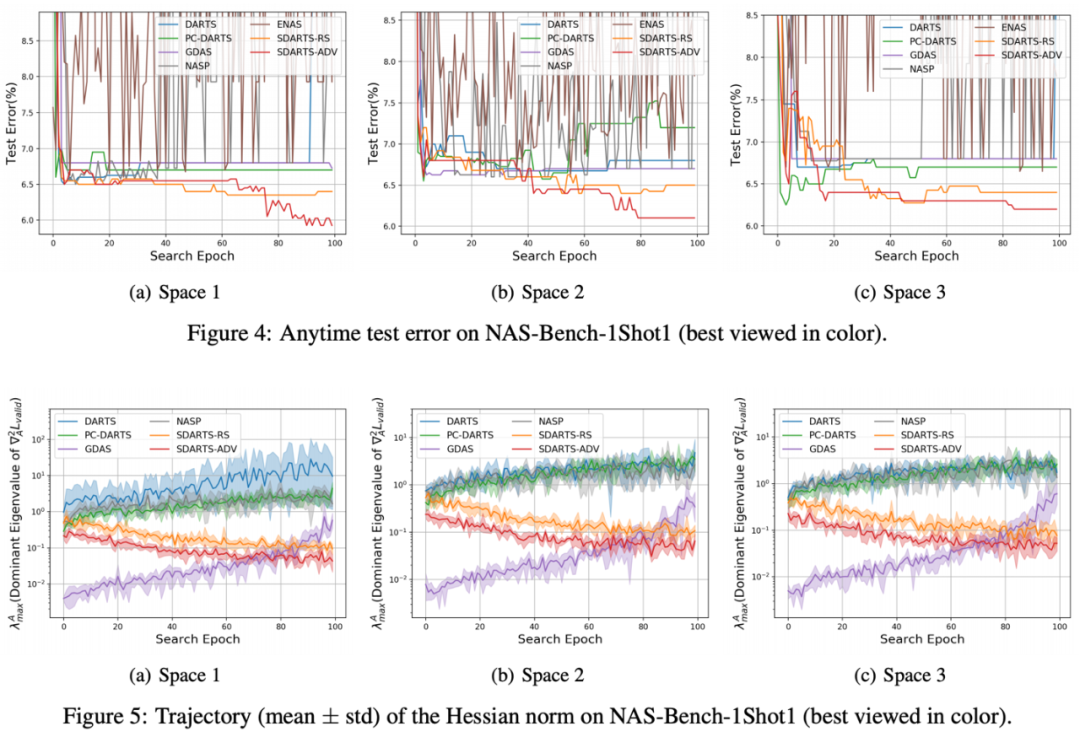
在数学上,尖锐的损失函数意味着其 Hessian 矩阵范数非常大。作者发现随着搜索进行,这一范数极速扩大,导致了 DARTS 的不稳定性。而本文提出的两种框架都有数学保障可以一直降低 Hessian 范数,这也在理论上解释了其有效性。
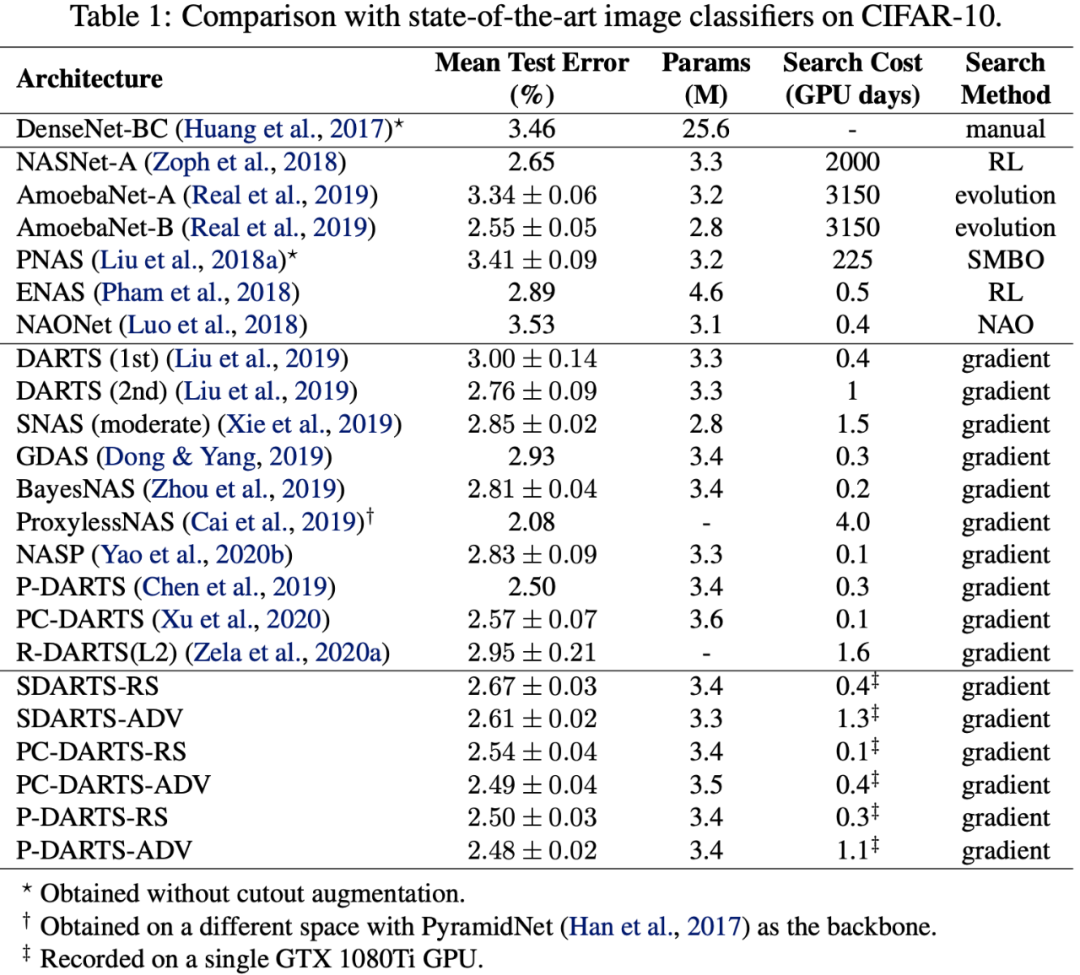
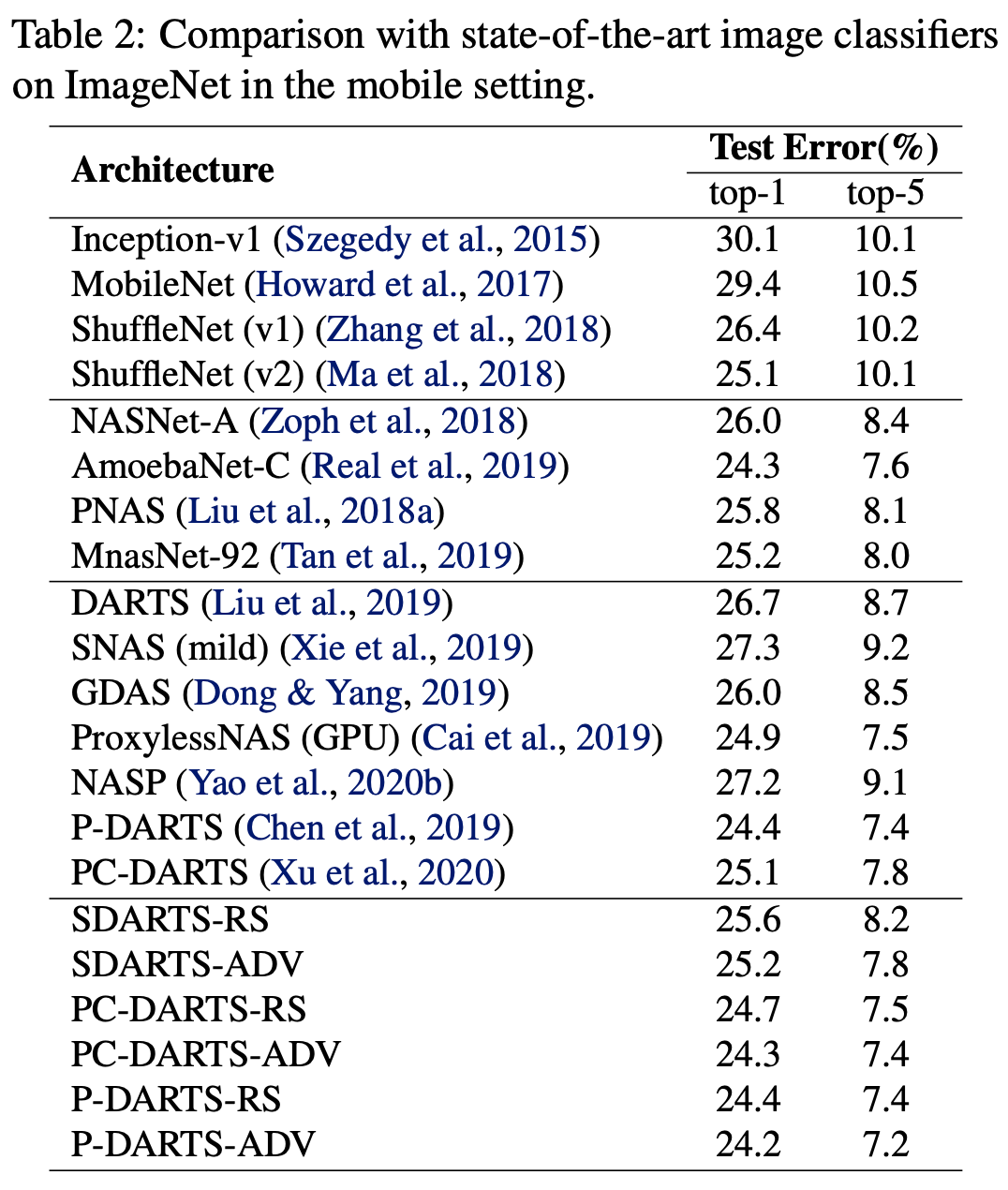
最后,本文提出的方法可以广泛应用于各种可微架构算法。在各种数据集和搜索空间上,作者发现 SDARTS 可以一贯地取得性能提升。
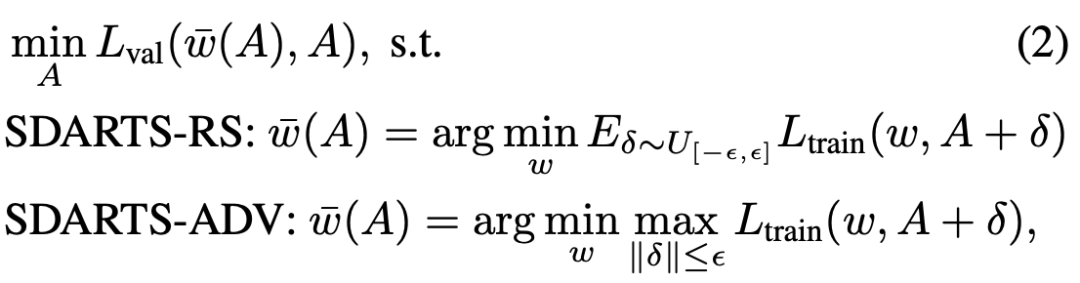
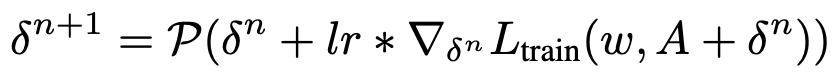

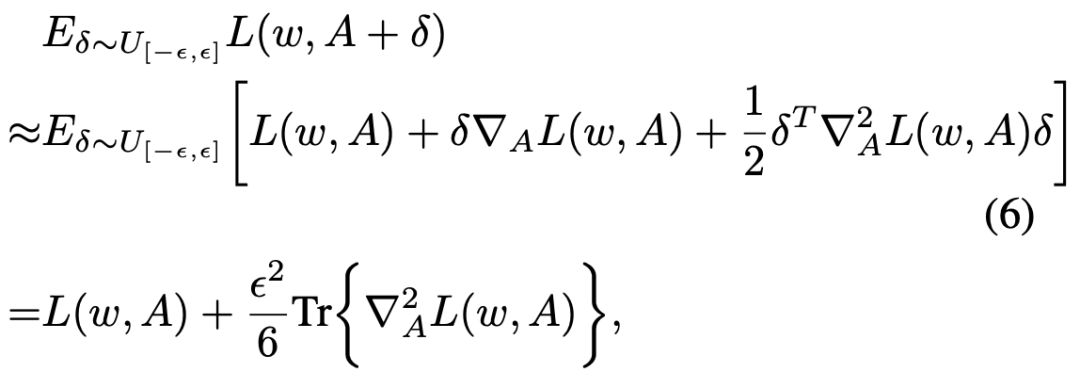
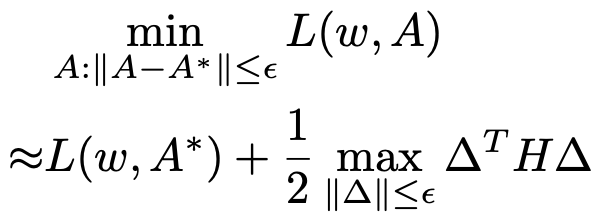

登录查看更多
相关内容
Arxiv
3+阅读 · 2018年10月2日


相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年10月2日