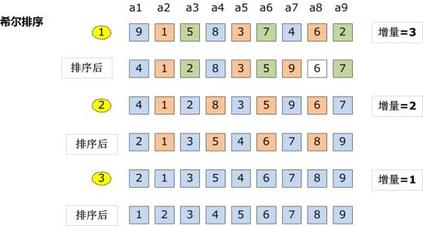
看动画轻松理解时间复杂度
来自:五分钟学算法(微信号:blgczzz)
算法(Algorithm)是指用来操作数据、解决程序问题的一组方法。对于同一个问题,使用不同的算法,也许最终得到的结果是一样的,比如排序就有前面的十大经典排序和几种奇葩排序,虽然结果相同,但在过程中消耗的资源和时间却会有很大的区别,比如快速排序与猴子排序:)。
那么我们应该如何去衡量不同算法之间的优劣呢?
主要还是从算法所占用的「时间」和「空间」两个维度去考量。
时间维度:是指执行当前算法所消耗的时间,我们通常用「时间复杂度」来描述。
空间维度:是指执行当前算法需要占用多少内存空间,我们通常用「空间复杂度」来描述。
本小节将从「时间」的维度进行分析。
什么是大O
当看「时间」二字,我们肯定可以想到将该算法程序运行一篇,通过运行的时间很容易就知道复杂度了。
这种方式可以吗?当然可以,不过它也有很多弊端。
比如程序员小吴的老式电脑处理10w数据使用冒泡排序要几秒,但读者的iMac Pro 可能只需要0.1s,这样的结果误差就很大了。更何况,有的算法运行时间要很久,根本没办法没时间去完整的运行,还是比如猴子排序:)。
那有什么方法可以严谨的进行算法的时间复杂度分析呢?
有的!
「 远古 」的程序员大佬们提出了通用的方法:「 大O符号表示法 」,即 T(n) = O(f(n))。
其中 n 表示数据规模 ,O(f(n))表示运行算法所需要执行的指令数,和f(n)成正比。
上面公式中用到的 Landau符号是由德国数论学家保罗·巴赫曼(Paul Bachmann)在其1892年的著作《解析数论》首先引入,由另一位德国数论学家艾德蒙·朗道(Edmund Landau)推广。Landau符号的作用在于用简单的函数来描述复杂函数行为,给出一个上或下(确)界。在计算算法复杂度时一般只用到大O符号,Landau符号体系中的小o符号、Θ符号等等比较不常用。这里的O,最初是用大写希腊字母,但现在都用大写英语字母O;小o符号也是用小写英语字母o,Θ符号则维持大写希腊字母Θ。
注:本文用到的算法中的界限指的是最低的上界。
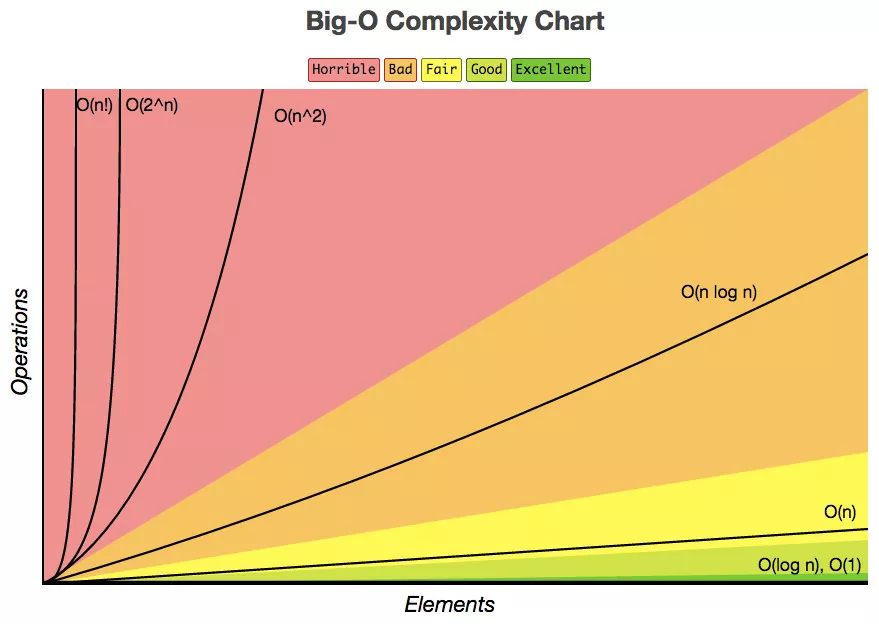
常见的时间复杂度量级
我们先从常见的时间复杂度量级进行大O的理解:
常数阶O(1)
线性阶O(n)
平方阶O(n²)
对数阶O(logn)
线性对数阶O(nlogn)
O(1)

无论代码执行了多少行,其他区域不会影响到操作,这个代码的时间复杂度都是O(1)
1void swapTwoInts(int &a, int &b){
2 int temp = a;
3 a = b;
4 b = temp;
5}
O(n)
在下面这段代码,for循环里面的代码会执行 n 遍,因此它消耗的时间是随着 n 的变化而变化的,因此可以用O(n)来表示它的时间复杂度。
1int sum ( int n ){
2 int ret = 0;
3 for ( int i = 0 ; i <= n ; i ++){
4 ret += i;
5 }
6 return ret;
7}
特别一提的是 c * O(n) 中的 c 可能小于 1 ,比如下面这段代码:
1void reverse ( string &s ) {
2 int n = s.size();
3 for (int i = 0 ; i < n/2 ; i++){
4 swap ( s[i] , s[n-1-i]);
5 }
6}
O(n²)

当存在双重循环的时候,即把 O(n) 的代码再嵌套循环一遍,它的时间复杂度就是 O(n²) 了。
1void selectionSort(int arr[],int n){
2 for(int i = 0; i < n ; i++){
3 int minIndex = i;
4 for (int j = i + 1; j < n ; j++ )
5 if (arr[j] < arr[minIndex])
6 minIndex = j;
7
8 swap ( arr[i], arr[minIndex]);
9 }
10}
这里简单的推导一下
当 i = 0 时,第二重循环需要运行 (n - 1) 次
当 i = 1 时,第二重循环需要运行 (n - 2) 次
。。。。。。
不难得到公式:
1(n - 1) + (n - 2) + (n - 3) + ... + 0
2= (0 + n - 1) * n / 2
3= O (n ^2)
当然并不是所有的双重循环都是 O(n²),比如下面这段输出 30n 次 Hello,五分钟学算法:)的代码。
1void printInformation (int n ){
2 for (int i = 1 ; i <= n ; i++)
3 for (int j = 1 ; j <= 30 ; j ++)
4 cout<< "Hello,五分钟学算法:)"<< endl;
5}
O(logn)
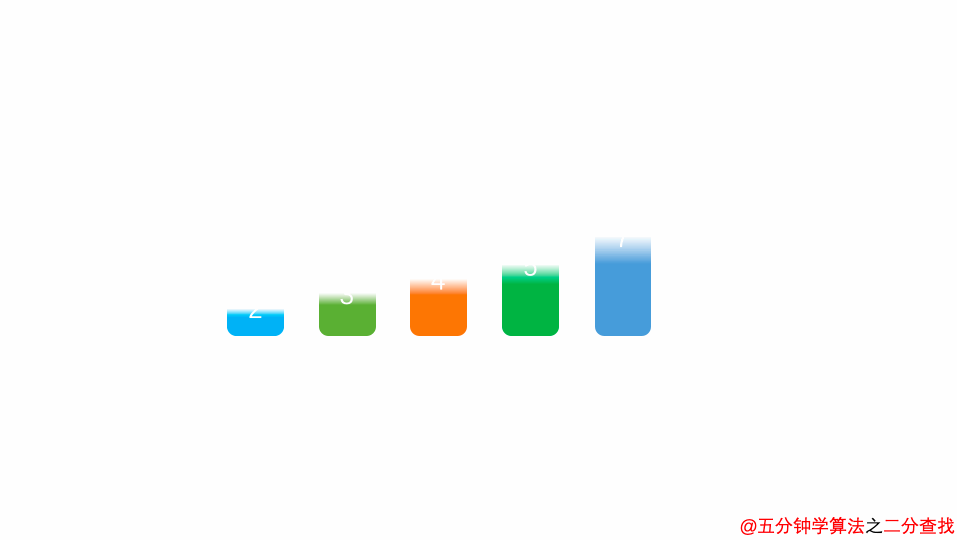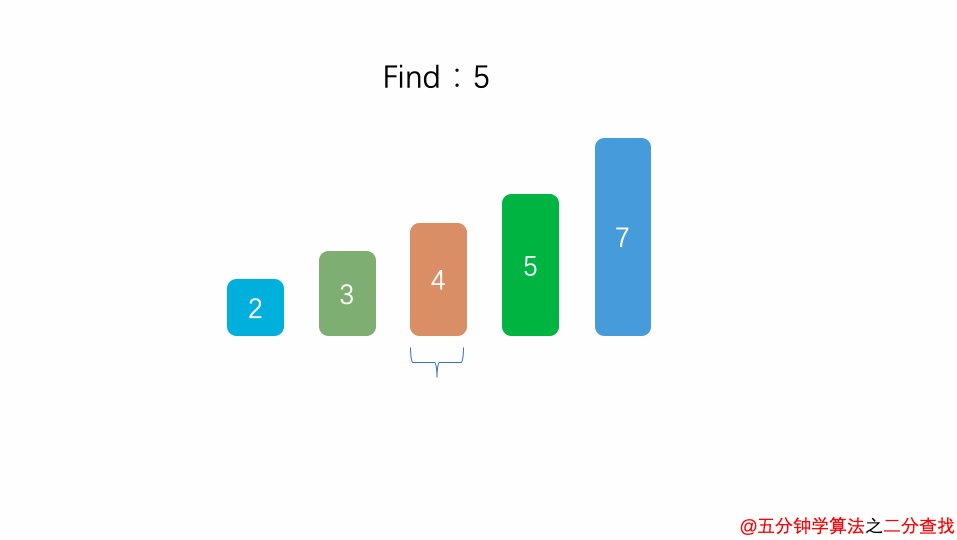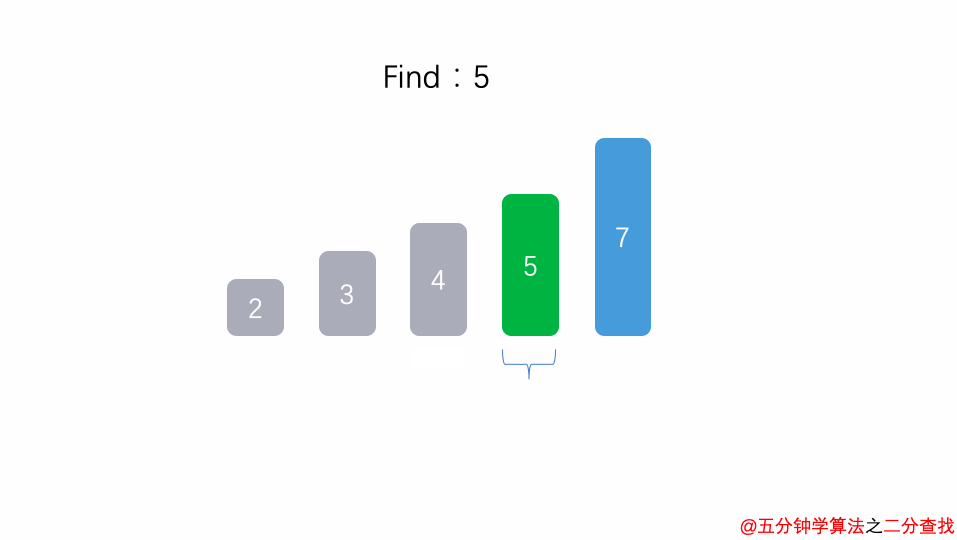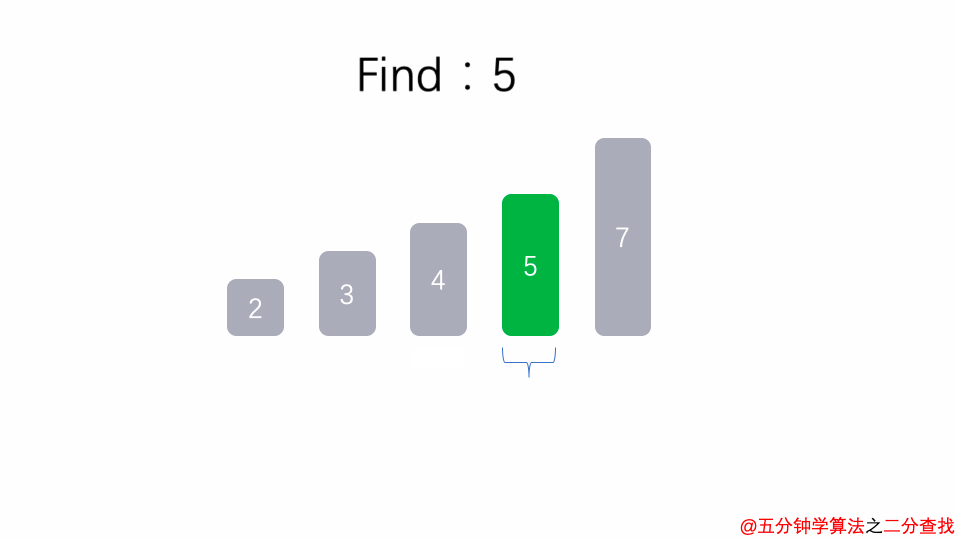
1int binarySearch( int arr[], int n , int target){
2 int l = 0, r = n - 1;
3 while ( l <= r) {
4 int mid = l + (r - l) / 2;
5 if (arr[mid] == target) return mid;
6 if (arr[mid] > target ) r = mid - 1;
7 else l = mid + 1;
8 }
9 return -1;
10}
在二分查找法的代码中,通过while循环,成 2 倍数的缩减搜索范围,也就是说需要经过 log2^n 次即可跳出循环。
同样的还有下面两段代码也是 O(logn) 级别的时间复杂度。
1 // 整形转成字符串
2 string intToString ( int num ){
3 string s = "";
4 // n 经过几次“除以10”的操作后,等于0
5 while (num ){
6 s += '0' + num%10;
7 num /= 10;
8 }
9 reverse(s)
10 return s;
11 }
1void hello (int n ) {
2 // n 除以几次 2 到 1
3 for ( int sz = 1; sz < n ; sz += sz)
4 for (int i = 1; i < n; i++)
5 cout<< "Hello,五分钟学算法:)"<< endl;
6}
O(nlogn)
将时间复杂度为O(logn)的代码循环N遍的话,那么它的时间复杂度就是 n * O(logn),也就是了O(nlogn)。
1void hello (){
2 for( m = 1 ; m < n ; m++){
3 i = 1;
4 while( i < n ){
5 i = i * 2;
6 }
7 }
8}
上面讲述了与复杂度有关的大 O 表示法和常见的时间复杂度量级,这篇文章来讲讲另外几种复杂度: 递归算法的时间复杂度(recursive algorithm time complexity),最好情况时间复杂度(best case time complexity)、最坏情况时间复杂度(worst case time complexity)、平均时间复杂度(average case time complexity)和均摊时间复杂度(amortized time complexity)。
递归算法的时间复杂度
如果递归函数中,只进行一次递归调用,递归深度为depth;
在每个递归的函数中,时间复杂度为T;
则总体的时间复杂度为O(T * depth)。
在前面的学习中,归并排序 与 快速排序 都带有递归的思想,并且时间复杂度都是O(nlogn) ,但并不是有递归的函数就一定是 O(nlogn) 级别的。从以下两种情况进行分析。
① 递归中进行一次递归调用的复杂度分析
二分查找法
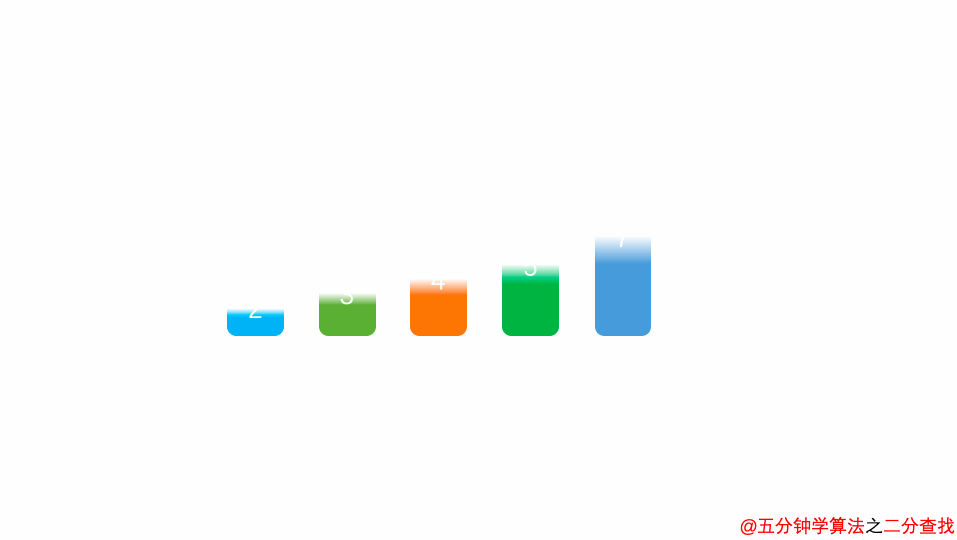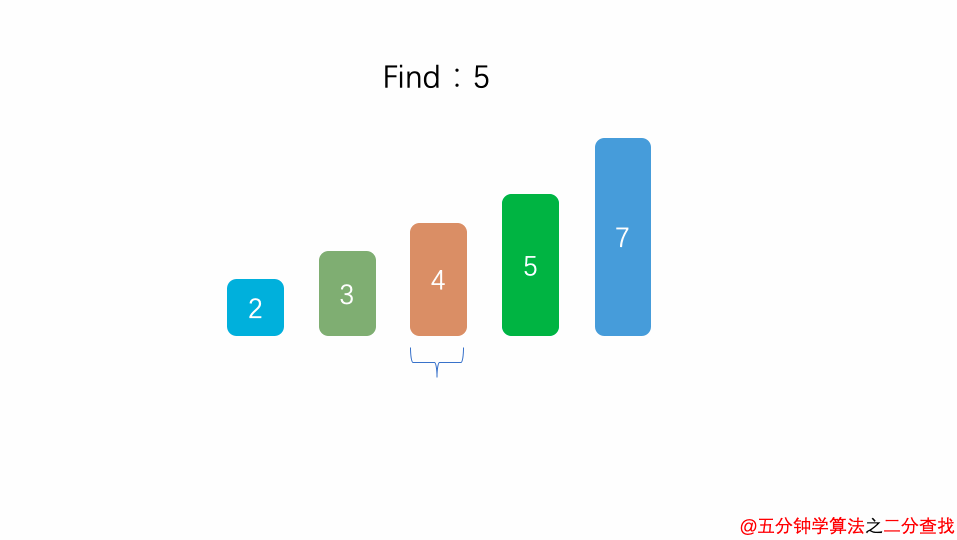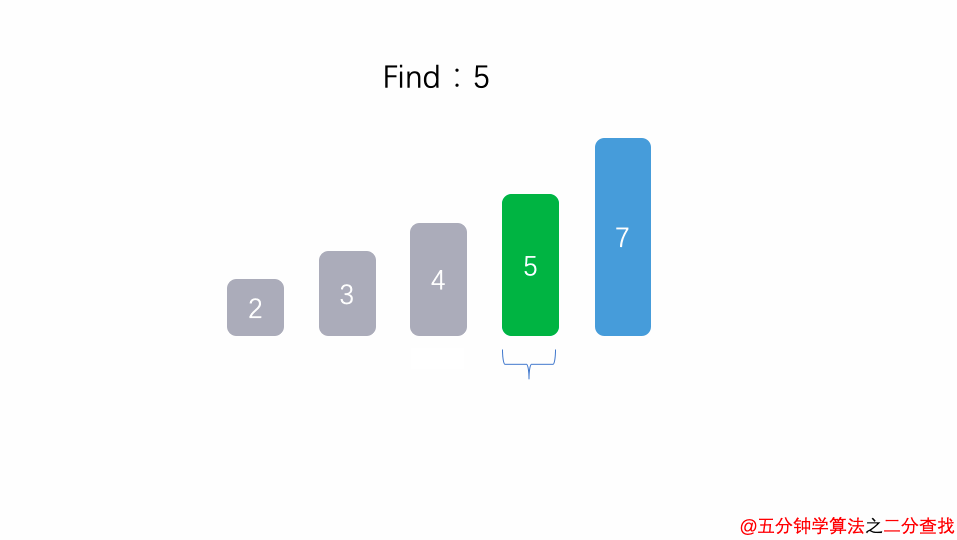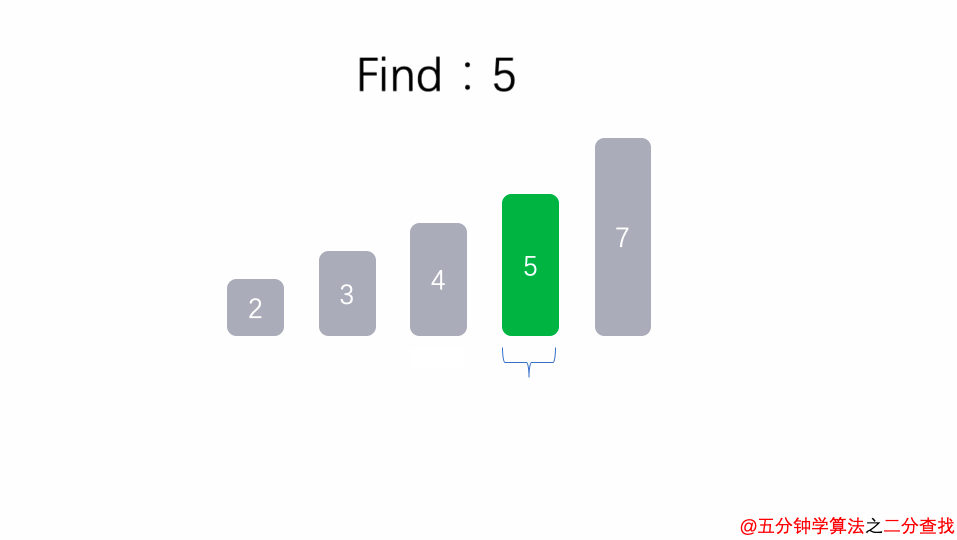
1int binarySearch(int arr[], int l, int r, int target){
2 if( l > r ) return -1;
3
4 int mid = l + (r-l)/2;
5 if( arr[mid] == target ) return mid;
6 else if( arr[mid] > target )
7 return binarySearch(arr, l, mid-1, target); // 左边
8 else
9 return binarySearch(arr, mid+1, r, target); // 右边
10}
比如在这段二分查找法的代码中,每次在 [ l , r ] 范围中去查找目标的位置,如果中间的元素 arr[mid] 不是 target,那么判断 arr[mid]是比 target 大 还是 小 ,进而再次调用 binarySearch这个函数。
在这个递归函数中,每一次没有找到target时,要么调用 左边 的 binarySearch函数,要么调用 右边 的 binarySearch函数。也就是说在此次递归中,最多调用了一次递归调用而已。根据数学知识,需要log2n次才能递归到底。因此,二分查找法的时间复杂度为 O(logn)。
求和

1int sum (int n) {
2 if (n == 0) return 0;
3 return n + sum( n - 1 )
4}
在这段代码中比较容易理解递归深度随输入 n 的增加而线性递增,因此时间复杂度为 O (n)。
求幂

1//递归深度:logn
2//时间复杂度:O(logn)
3double pow( double x, int n){
4 if (n == 0) return 1.0;
5
6 double t = pow(x,n/2);
7 if (n %2) return x*t*t;
8 return t * t;
9}
递归深度为 logn,因为是求需要除以 2 多少次才能到底。
② 递归中进行多次递归调用的复杂度分析
递归算法中比较难计算的是多次递归调用。
先看下面这段代码,有两次递归调用。
1// O(2^n) 指数级别的数量级,后续动态规划的优化点
2int f(int n){
3 if (n == 0) return 1;
4 return f(n-1) + f(n - 1);
5}

递归树中节点数就是代码计算的调用次数。
比如 当 n = 3 时,调用次数计算公式为
1 + 2 + 4 + 8 = 15
一般的,调用次数计算公式为
2^0 + 2^1 + 2^2 + …… + 2^n
= 2^(n+1) - 1
= O(2^n)

与之有所类似的是 归并排序 的递归树,区别点在于
1. 上述例子中树的深度为
n,而 归并排序 的递归树深度为logn。2. 上述例子中每次处理的数据规模是一样的,而在 归并排序 中每个节点处理的数据规模是逐渐缩小的
因此,在如 归并排序 等排序算法中,每一层处理的数据量为 O(n) 级别,同时有 logn层,时间复杂度便是 O(nlogn)。
最好、最坏情况时间复杂度

最好、最坏情况时间复杂度指的是特殊情况下的时间复杂度。
动图表明的是在数组 array 中寻找变量 x 第一次出现的位置,若没有找到,则返回 -1;否则返回位置下标。
1int find(int[] array, int n, int x) {
2 for ( int i = 0 ; i < n; i++) {
3 if (array[i] == x) {
4 return i;
5 break;
6 }
7 }
8 return -1;
9}
在这里当数组中第一个元素就是要找的 x 时,时间复杂度是 O(1);而当最后一个元素才是 x 时,时间复杂度则是 O(n)。
最好情况时间复杂度就是在最理想情况下执行代码的时间复杂度,它的时间是最短的;最坏情况时间复杂度就是在最糟糕情况下执行代码的时间复杂度,它的时间是最长的。
平均情况时间复杂度
最好、最坏时间复杂度反应的是极端条件下的复杂度,发生的概率不大,不能代表平均水平。那么为了更好的表示平均情况下的算法复杂度,就需要引入平均时间复杂度。
平均情况时间复杂度可用代码在所有可能情况下执行次数的加权平均值表示。
还是以 find 函数为例,从概率的角度看, x 在数组中每一个位置的可能性是相同的,为 1 / n。那么,那么平均情况时间复杂度就可以用下面的方式计算:
((1 + 2 + … + n) / n + n) / 2 = (3n + 1) / 4
find 函数的平均时间复杂度为 O(n)。
均摊复杂度分析
我们通过一个动态数组的 push_back 操作来理解 均摊复杂度。

1template <typename T>
2class MyVector{
3private:
4 T* data;
5 int size; // 存储数组中的元素个数
6 int capacity; // 存储数组中可以容纳的最大的元素个数
7 // 复杂度为 O(n)
8 void resize(int newCapacity){
9 T *newData = new T[newCapacity];
10 for( int i = 0 ; i < size ; i ++ ){
11 newData[i] = data[i];
12 }
13 data = newData;
14 capacity = newCapacity;
15 }
16public:
17 MyVector(){
18 data = new T[100];
19 size = 0;
20 capacity = 100;
21 }
22 // 平均复杂度为 O(1)
23 void push_back(T e){
24 if(size == capacity)
25 resize(2 * capacity);
26 data[size++] = e;
27 }
28 // 平均复杂度为 O(1)
29 T pop_back(){
30 size --;
31 return data[size];
32 }
33
34};
push_back实现的功能是往数组的末尾增加一个元素,如果数组没有满,直接往后面插入元素;如果数组满了,即 size == capacity ,则将数组扩容一倍,然后再插入元素。
例如,数组长度为 n,则前 n 次调用 push_back 复杂度都为 O(1) 级别;在第 n + 1 次则需要先进行 n 次元素转移操作,然后再进行 1 次插入操作,复杂度为 O(n)。
因此,平均来看:对于容量为 n 的动态数组,前面添加元素需要消耗了 1 * n 的时间,扩容操作消耗 n 时间 ,总共就是 2 * n 的时间,因此均摊时间复杂度为 O(2n / n) = O(2),也就是 O(1) 级别了。
可以得出一个比较有意思的结论:一个相对比较耗时的操作,如果能保证它不会每次都被触发,那么这个相对比较耗时的操作,它所相应的时间是可以分摊到其它的操作中来的。
●编号813,输入编号直达本文
●输入m获取文章目录

人工智能与大数据技术
更多推荐《25个技术类公众微信》
涵盖:程序人生、算法与数据结构、黑客技术与网络安全、大数据技术、前端开发、Java、Python、Web开发、安卓开发、iOS开发、C/C++、.NET、Linux、数据库、运维等。