教程 | 深度Q学习:一步步实现能玩《毁灭战士》的智能体
选自Medium
作者:Thomas Simonini
机器之心编译
参与:Panda
近年来,深度强化学习已经取得了有目共睹的成功。机器之心也曾发布过很多介绍强化学习基本理论和前沿进展的文章,比如《专题 | 深度强化学习综述:从 AlphaGo 背后的力量到学习资源分享(附论文)》。近日,深度学习工程师 Thomas Simonini 在 freeCodeCamp 上发表了介绍深度强化学习的系列文章,已发布的三篇分别介绍了强化学习基本概念、Q 学习以及在《毁灭战士》游戏上开发智能体的过程。机器之心已经编译介绍了其中第二篇,本文为第三篇,前两篇可参阅:
https://medium.freecodecamp.org/an-introduction-to-reinforcement-learning-4339519de419
上一次,我们介绍了 Q 学习:这种算法可以得到 Q-table,并且智能体可将其用于寻找给定状态的最佳动作。但正如我们所见,当状态空间很大时,求取和更新 Q-table 的效果会很差。
本文是深度强化学习系列博客文章的第三篇。我们将在本文中介绍创造一个深度 Q 网络的过程。我们不会使用 Q-table,我们会实现一个神经网络,其以状态为输入,然后基于该状态为每个动作逼近 Q 值。在这种模型的帮助下,我们将创造一个能玩《毁灭战士》(Doom)的智能体!

我们的 DQN 智能体
在这篇文章中,你将学习到:
什么是深度 Q 学习(DQL)?
使用 DQL 的最佳策略是什么?
如何处理有时间限制的问题?
为什么要使用经历重放(experience replay)?
DQL 背后的数学
如何用 TensorFlow 实现它?
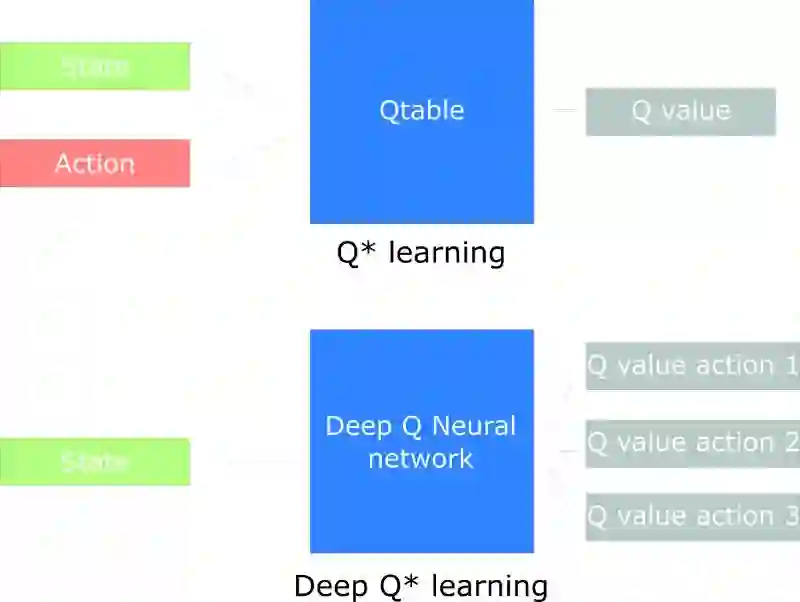
让 Q 学习变「深度」
在上一篇文章中,我们使用 Q 学习算法创造了一个能玩《Frozen Lake》的智能体。
我们实现了用于创建和更新 Q-table 的 Q 学习函数。你可以将其看作是一个参考表,能帮助我们找到一个给定状态下一个动作的最大预期未来奖励。这个策略很不错——但却难以扩大规模。
比如我们今天要完成的目标。我们将创造一个能玩《毁灭战士》的智能体。《毁灭战士》是一个有很大的状态空间的环境(有数百万个不同状态)。为这样的环境创建和更新 Q-table 根本不行。
针对这种情况的最好想法是创建一个神经网络,使之能在给定状态下逼近每个动作的不同 Q 值。
深度 Q 学习的工作方式
这是我们的深度 Q 学习的架构:

看起来很复杂,但我会一步步地解释这个架构。
我们的深度 Q 神经网络以 4 帧一组为输入。这些帧会通过该网络,然后为给定状态的每个可能动作输出一个 Q 值的向量。我们需要取这个向量的最大 Q 值来找到我们最好的动作。
一开始的时候,这个智能体的表现真的很差。但随着时间的推移,它能越来越好地将帧(状态)与最佳的动作关联起来。
预处理部分
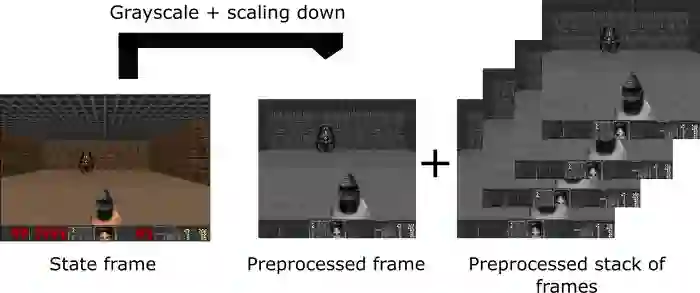
预处理是很重要的步骤。我们希望降低状态的复杂度,从而减少训练所需的计算时间。
首先,我们可以将每个状态灰度化。颜色并不能提供重要的信息(在我们的情况中,我们只需要找到敌人并杀死敌人,而我们不需要颜色就能找到它们)。这能节省很多资源,因为我们将 3 个颜色通道(RGB)变成了 1 个通道(灰度)。
然后我们对帧进行裁剪。在我们的情况下,可以看到屋顶实际没什么用。
然后我们降低帧的尺寸,再将 4 个子帧堆叠到一起。
时间有限的问题
Arthur Juliani 在他的文章中对此给出了很好的解释,参阅:https://goo.gl/ZU2Z9a。他有个很巧妙的想法:使用 LSTM 神经网络来处理这个问题。
但是,我觉得对初学者来说,使用堆叠的帧更好。
你可能会问的第一个问题是:我们为什么要把帧堆叠到一起?
我们把帧堆叠到一起的原因是这有助于我们处理时间有限的问题。
比如,在《乒乓球》(Pong)游戏中,你会看到这样的帧:

你能告诉我球会往哪边走吗?
不能,因为一帧不足以体现运动情况。
但如果我再添加另外 3 帧呢?这里你就能看到球正往右边运动:

对于我们的《毁灭战士》智能体而言,道理也是一样。如果我们一次只为其提供 1 帧,它就没有运动的概念。如果它没法确定目标的移动方向和速度,它又怎能做出正确的决定呢?
使用卷积网络
这些帧会在 3 个卷积层中得到处理。这些层让你能利用图像之中的空间关系。另外,因为帧是堆叠在一起的,所以你可以利用这些帧之间的一些空间属性。
如果你对卷积不熟悉,可以阅读 Adam Geitgey 这篇出色的直观介绍:https://goo.gl/6Dl7EA。
这里的每个卷积层都使用 ELU 作为激活函数。事实证明,ELU 是一种用于卷积层的优良激活函数。
我们使用了一个带有 ELU 激活函数的万全连接层和一个输出层(一个带有线性激活函数的完全连接层),其可以得到每个动作的 Q 值估计。
经历重放:更高效地利用已观察过的经历
经历重放(Experience Replay)有助于我们完成两件事:
避免忘记之前的经历
降低经历之间的相关性
我将会解释这两个概念。
这部分内容和插图的灵感来自 Udacity 的「深度学习基础」纳米学位课程中的深度 Q 学习章节。
避免忘记之前的经历
我们有个大问题:权重的可变性,因为动作和状态之间有很高的相关性。
回忆一下我们在第一篇文章中介绍的强化学习过程:
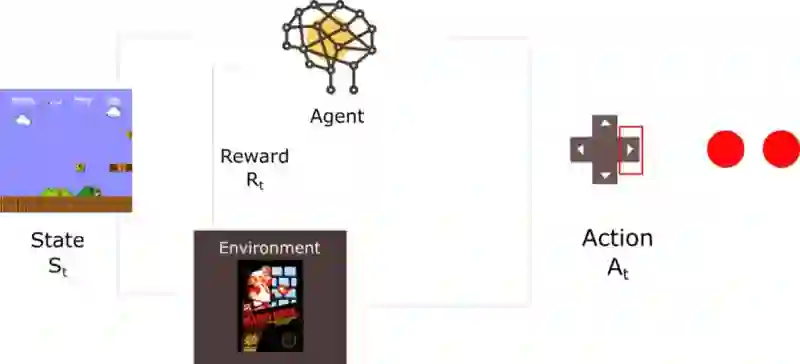
在每个时间步骤,我们都会收到一个元组(状态,动作,奖励,新状态)。我们从中学习(将该元组输入我们的神经网络),然后丢弃这个经历。
我们的问题是为神经网络提供来自与环境交互的序列样本。因为在它使用新经历覆写时,往往会忘记之前的经历。
比如,如果我们先在第一关,然后到了第二关(这两者完全不一样),那么我们的智能体就会忘记在第一关的做法。

在学习水中关卡的玩法后,我们的智能体会忘记第一关的玩法。
因此,多次学习之前的经历会更加有效。
我们的解决方案:创建一个「回放缓冲(replay buffer)」。这能在存储经历元组的同时与环境进行交互,然后我们可以采样少部分元组以输入我们的神经网络。
你可以将回放缓冲看作是一个文件夹,其中每个表格都是一个经历元组。你可以通过与环境的交互向其提供信息。然后你可以随机取某个表格来输入神经网络。

这能防止网络只学习它刚刚做的事情。
降低经历之间的相关性
我们还有另一个问题——我们知道每个动作都会影响下一个状态。这会输出一个高度相关的经历元组序列。
如果我们按顺序训练这个网络,我们的智能体就有被这种相关性效应影响的风险。
通过随机采样回放缓冲,我们可以打破这种相关性。这能防止动作值发生灾难性的震荡或发散。
举个例子能让人更好地理解。比如说我们在玩一个第一人称的射击游戏,其中的怪可能出现在左边,也可能出现在右边。我们的智能体的目标是用枪打怪。它有两把枪和两个动作:射击左边或射击右边。
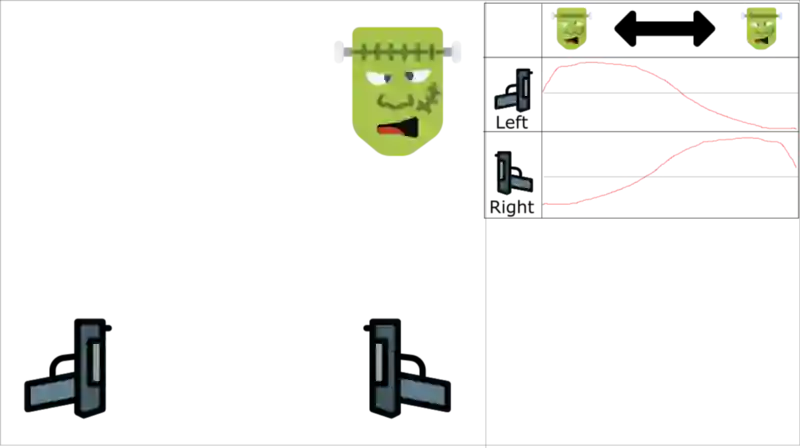
这张表表示 Q 值的近似。
我们学习了有顺序的经历。假如我们知道:如果我们击中了一个怪,下一个怪出现在同一方向的概率是 70%。在我们的情况中,这就是我们的经历元组之间的相关性。
让我们开始训练。我们的智能体看到了右边的怪,然后使用右边的枪射击了它。这做对了!
然后下一个怪也来自右边(有 70% 的概率),然后智能体又会射击右边的枪。再次成功,很好!
然后一次又一次亦复如是……

红色的枪是所采取的动作。
问题是,这种方法会增大在整个状态空间中使用右边的枪的值。
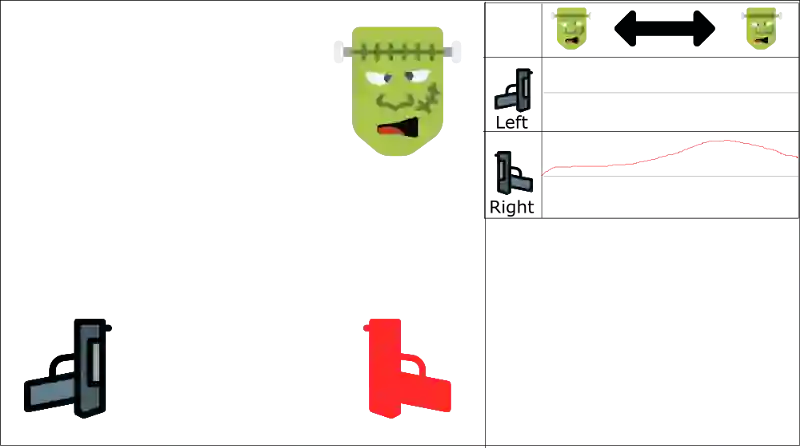
我们可以看到怪在左边而射击右边的枪是正例(即使这不合理)。
如果我们的智能体没有看到很多左边出怪的样本(因为只有 30% 的可能性在左边),那么我们的智能体最后就只会选择右边的枪,而不管从那边出怪。这根本不合理。
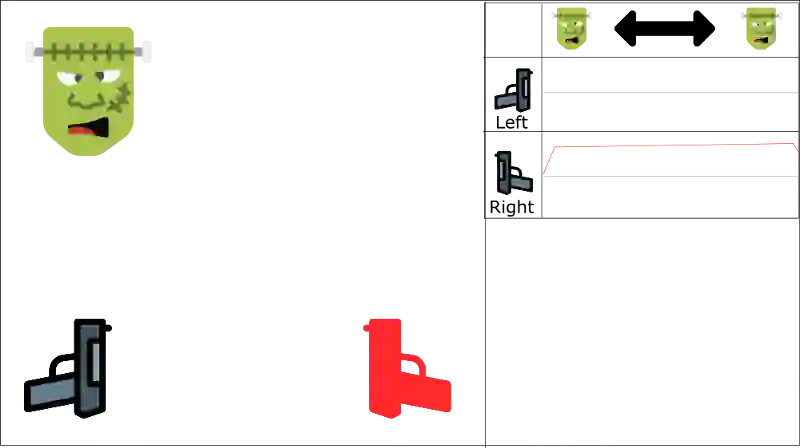
即使左边出怪,我们的智能体也会开右边的枪。
我们有两种解决这一问题的策略。
首先,我们必须停止在学习的同时与环境进行交互。我们应该尝试不同的情况,随机地玩玩以探索状态空间。我们可以将这些经历保存在回放缓冲之中。
然后,我们可以回忆这些经历并从中学习。在那之后,再回去调整更新过的价值函数。
这样,我们才会有更好的样本集。我们才能根据这些样本生成模式,以任何所需的顺序回忆它们。
这有助于避免过于关注状态空间的一个区域。这能防止不断强化同一个动作。
这种方法可以被视为一种形式的监督学习。
在未来的文章中,我们还将介绍使用「优先的经历重放」。这让我们可以更加频繁地为神经网络提供罕见或「重要的」元组。
我们的深度 Q 学习算法
首先来点数学运算。回想一下我们使用贝尔曼方程在给定状态和动作下更新 Q 值的方法:
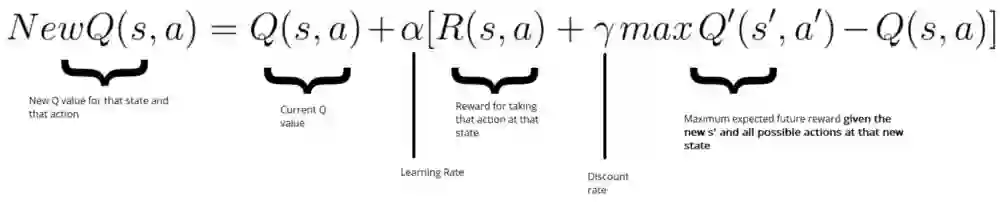
在我们的这个案例中,我们希望更新神经网络的权重以减小误差。
通过求取我们的 Q_target(来自下一个状态的最大可能值)和 Q_value(我们当前预测的 Q 值)之间的差异,可以计算误差(TD 误差)。

Initialize Doom Environment E
Initialize replay Memory M with capacity N (= finite capacity)
Initialize the DQN weights w
for episode in max_episode:
s = Environment state
for steps in max_steps:
Choose action a from state s using epsilon greedy.
Take action a, get r (reward) and s' (next state)
Store experience tuple <s, a, r, s'> in M
s = s' (state = new_state)
Get random minibatch of exp tuples from M
Set Q_target = reward(s,a) + γmaxQ(s')
Update w = α(Q_target - Q_value) * ∇w Q_value这个算法中发生着两个过程:
我们采样我们执行动作的环境并将所观察到的经历元组存储在回放记忆(replay memory)中。
随机选择小批量的元组,并使用梯度下降更新步骤从中学习。
实现我们的深度 Q 神经网络
现在我们知道其工作方式了,我们可以一步步地实现它了。我们在这个 Jupyter 笔记中介绍了代码的每个步骤和每一部分:https://github.com/simoninithomas/Deep_reinforcement_learning_Course/blob/master/DQN%20Doom/Deep%20Q%20learning%20with%20Doom.ipynb。
一步步完成之后,你就创造出了一个能学习玩《毁灭战士》的智能体!

原文链接:https://medium.freecodecamp.org/an-introduction-to-deep-q-learning-lets-play-doom-54d02d8017d8
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




