GPT迭代成本「近乎荒谬」,Karpathy 300行代码带你玩转迷你版

新智元报道
新智元报道
来源:reddit
编辑:小智
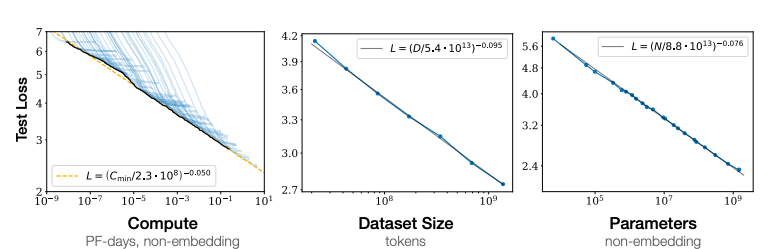
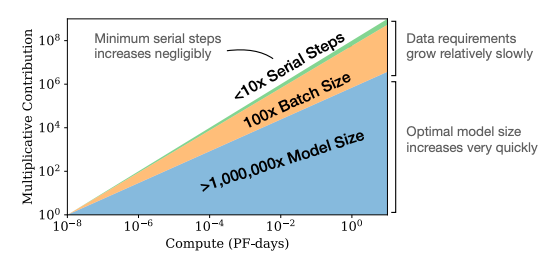
【新智元导读】最近,特斯拉AI总监Karpathy开源了一个名为minGPT的项目,用300行代码实现了GPT的训练。没有OpenAI的超级算力,该如何调整GPT这类语言模型的各种超参数?





登录查看更多
相关内容
Arxiv
4+阅读 · 2020年10月15日
Arxiv
0+阅读 · 2020年10月13日
Arxiv
0+阅读 · 2020年10月8日
Arxiv
6+阅读 · 2020年2月25日
相关主题

相关VIP内容
相关资讯