【WWW2021】归一化难样本挖掘的双重注意匹配网络

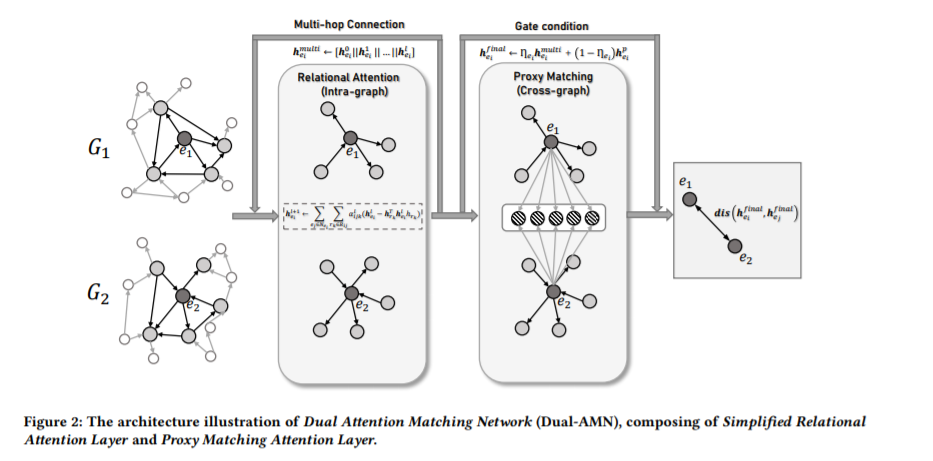
在多源知识图谱(KGs)中寻找等价实体是KGs集成的关键步骤,也称为实体对齐(EA)。然而,现有的EA方法大多效率低下,伸缩性差。最近的总结指出,其中一些甚至需要几天的时间来处理包含20万个节点(DWY100K)的数据集。我们认为过于复杂的图编码器和低效的负采样策略是造成这种现象的两个主要原因。本文提出了一种新的KG编码器-双注意匹配网络(Dual- AMN),该网络不仅能对图内和图间信息进行智能建模,而且大大降低了计算复杂度。此外,我们提出了归一化的难样本挖掘损失来平滑选择硬负样本,减少了损失偏移。在广泛应用的公共数据集上的实验结果表明,该方法具有较高的精度和效率。在DWY100K上,我们的方法的整个运行过程可以在1100秒内完成,比之前的工作至少快10倍。我们的方法在所有数据集上的性能也优于之前的工作,其中𝐻𝑖𝑡𝑠@1和𝑀𝑅𝑅从6%提高到13%。
https://www.zhuanzhi.ai/paper/3d0a0bf7905b28afbdffaa48e0d640c3
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DAMN” 就可以获取《【WWW2021】归一化难样本挖掘的双重注意匹配网络》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2021年6月8日
Arxiv
14+阅读 · 2021年6月5日
Arxiv
7+阅读 · 2019年7月10日
Arxiv
3+阅读 · 2018年5月28日
Arxiv
6+阅读 · 2018年5月17日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年6月8日
Arxiv
14+阅读 · 2021年6月5日
Arxiv
7+阅读 · 2019年7月10日
Arxiv
3+阅读 · 2018年5月28日
Arxiv
6+阅读 · 2018年5月17日