开源 | 猿辅导分布式机器学习库ytk-learn、分布式通信库ytk-mp4j
机器之心投稿
作者:猿辅导研究团队语音识别负责人夏龙、机器学习工程师吴凡
近期,猿辅导公司开源了两个机器学习项目—ytk-learn, ytk-mp4j,其中 ytk-mp4j 是一个高效的分布式通信库,基于该通信库我们实现了 ytk-learn 分布式机器学习库,该机器学习库目前在猿辅导很多应用场景中使用,比如,自适应学习、学生高考分预测、数据挖掘、课程推荐等。
ytk-learn 分布式机器学习库
项目背景
LR(Logistic Regression), GBDT(Gradient Boosting Decision Tree), FM(Factorization Machines), FFM(Field-aware Factorization Machines) 模型是广告点击率预测和推荐系统中广泛使用的模型,但是到目前为止几乎没有一个高效的机器学习开源项目集这几种常用模型于一身,而且很多机器学习开源项目只能在特定计算平台下使用,最重要的是不能高效的整合到线上生产环境中。ytk-learn 就是解决以上问题而产生的。
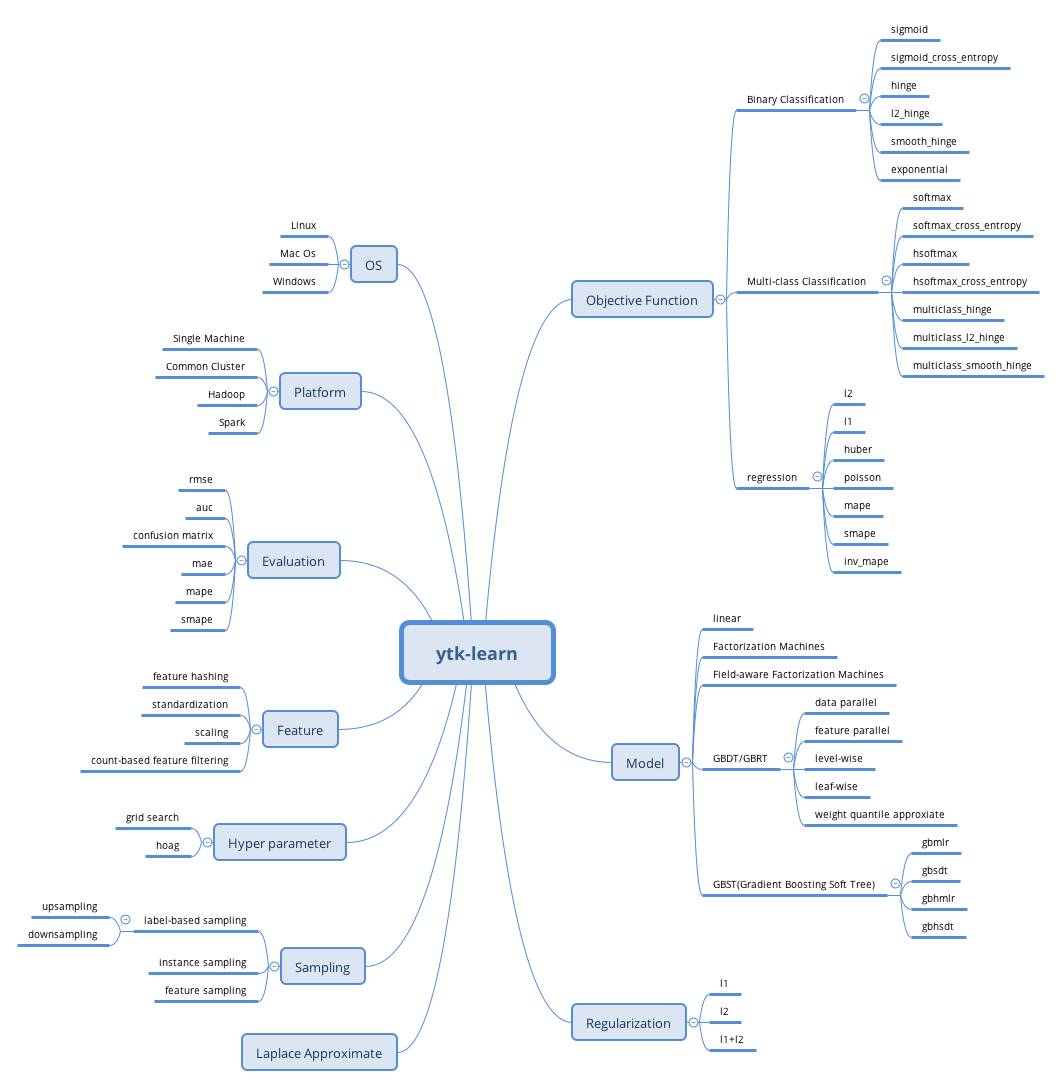
图 1 ytk-learn 特性概略
项目简介
ytk-learn 是基于 Java 的高效分布式机器学习库,实现大量的主流传统机器学习模型 (GBDT, LR, FM, FFM 等) 和 loss 函数,支持单机多线程、多机集群及分布式计算环境。
其中 GBDT/GBRT 的实现借鉴吸收了 XGBoost 和 LightGBM 的大部分有用特性,支持特征并行和数据并行,支持传统的精确算法和直方图近似算法,支持 level-wise 或者 leaf-wise 的建树方式,而且还实现了分布式带权分位数近似。在单机数据并行的场景中训练速度跟 XGBoost 相当,在非
传统的 GBDT/GBRT 在含有大量 Categorical 特征的场景中无法使用,我们实现了多种适用于大量 Categorical 特征的 GBST(Gradient Boosting Soft Tree) 模型,在猿辅导的点击率预测和推荐场景中效果明显好于 LR、FM、FFM 等模型。
ytk-learn 实现了改进 Hoag(Hyperparameter optimization with approximate gradient,ICML2016) 算法,能够自动高效的进行超参数搜索。当目标函数是凸函数时,hoag 能快速得到最优超参数 (kaggle 比赛利器),效率明显高于传统的网格超参数搜索算法 (grid search),而且在非凸目标函数场景中也适用。
其他特性:
简单易用,文档详细,只需要用户安装 Java 8 运行时环境即可,而且所有模型都有可运行的 demo
支持主流的操作系统:Linux,Windows,Mac OS,仅需安装 Java8 运行环境即可使用
支持单机多线程,多机集群及分布式环境 (Hadoop,Spark),相比 Hadoop Mahout, Spark MLlib 效率高很多
提供简单易用的在线预测代码,可以方便整合到线上生成环境
支持多种目标函数和评估指标,支持 L1,L2,L1+L2 正则
树模型支持样本采样,特征采样,提供初始预估值的训练
支持特征预处理 (归一化,缩放),特征哈希,特征过滤,基于样本标签采样
提供了读取数据时进行高效数据处理的 python 脚本
训练模型支持 checkpoint,继续训练
LR 支持 Laplace 近似,方便做 Exploitation&Exploration
基于猿辅导的 ytk-mp4j 通信库,分布式训练效率非常高
详细细节请参考:https://github.com/yuantiku/ytk-learn
ytk-mp4j 分布式机器学习通信库
项目背景
目前可以用于分布式机器学习的通信主要基于 MPI 和 RPC,其中 MPI 是分布式高性能计算的标配,虽然效率非常高,但是对于开发分布式机器学习任务来说有很多缺点: 开发难度大、数据支持太底层、只能用 C/C++, Fortran 编写等等;RPC 方式来实现类似 allreduce 这种操作,在特征维度特别高的场景,通信效率太低。所以我们开发了一套易用且高效的机器学习分布式通信库。
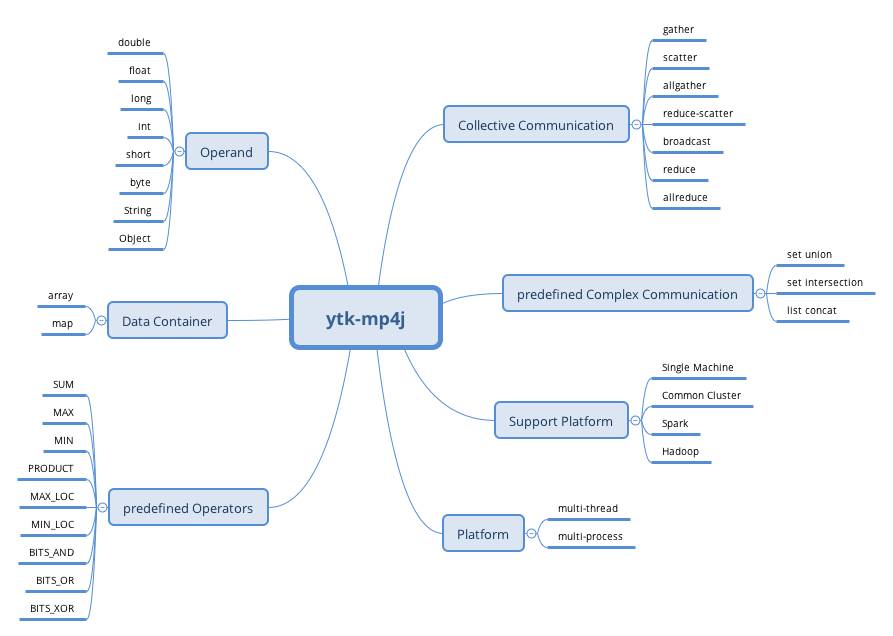
图 2 ytk-mp4j 特性概略
项目简介
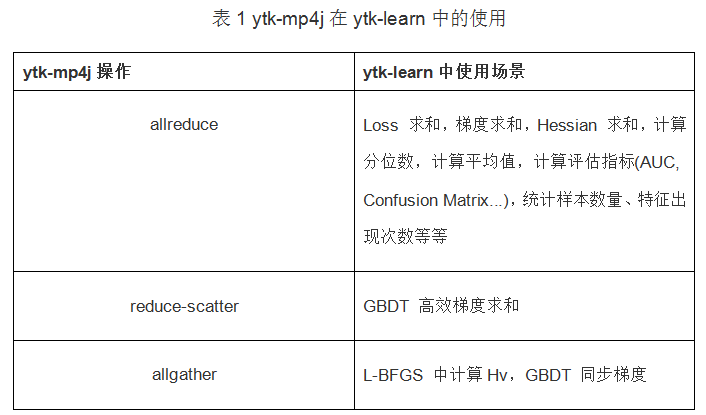
ytk-mp4j 是基于 Java 的高效分布式机器学习通信库,实现了类似 MPI Collective 通信中的大部分操作,包含 gather, scatter, allgather, reduce-scatter, broadcast, reduce, allreduce,使用 ytk-mp4j 可以快速地把串行机器学习程序改造成支持多线程和多进程,ytk-learn 中所有涉及到分布式通信操作都是基于 ytk-mp4j 实现 (表 1 中给出了部分例子)。
相比于 MPI, ytk-mp4j 扩展实现了一些非常实用的特性:
所有的通信操作都是基于最优算法实现 [1,2],性能非常高,同时支持多线程,多进程。同样的功能,在 C/C++ 环境中,可能需要结合 MPI 和 OpenMP 才能实现
不仅支持基本的数据类型 (double, float, long, int, short, byte),而且还支持 Java String 及任意普通 Java 对象 (Java 对象只需要实现 Kryo 的 Serializer 接口)
不仅支持传统数组类型的 Collective 通信,而且还支持 Java Map 数据类型,使用 Map 数据类型,用户可以实现非常复杂的通信操作 (例如:集合求交、求并,链表的连接等操作)
支持数据压缩传输,在网络资源很紧张的情况下,可以节约大量的带宽
纯 Java 代码实现,可以无缝集成到 Hadoop, Spark 等分布式计算平台,构建自己的分布式机器学习系统
使用 Java 的 SDP(Sockets Direct Protocol) 可以实现高效的 RDMA(Remote Direct Memory Access)
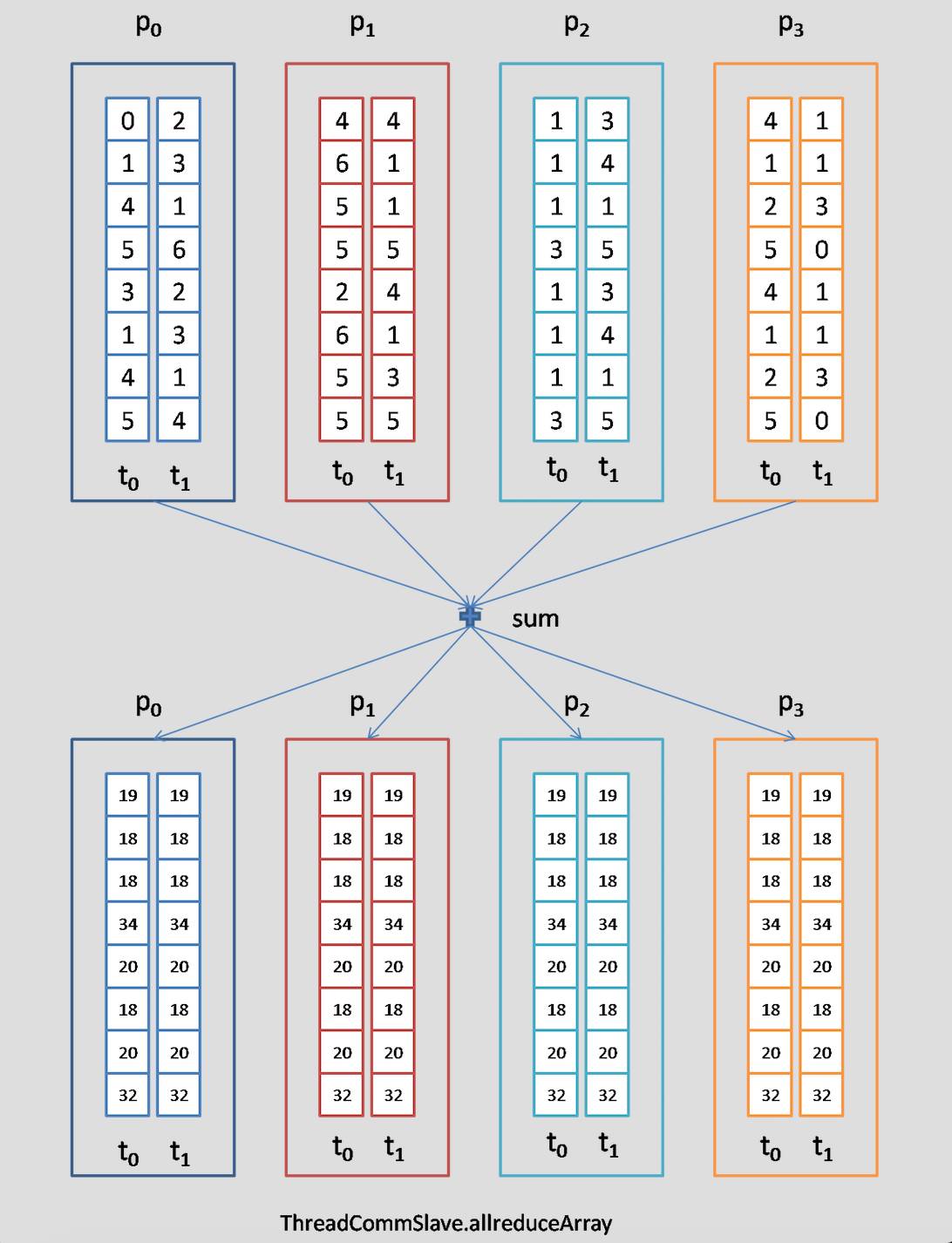
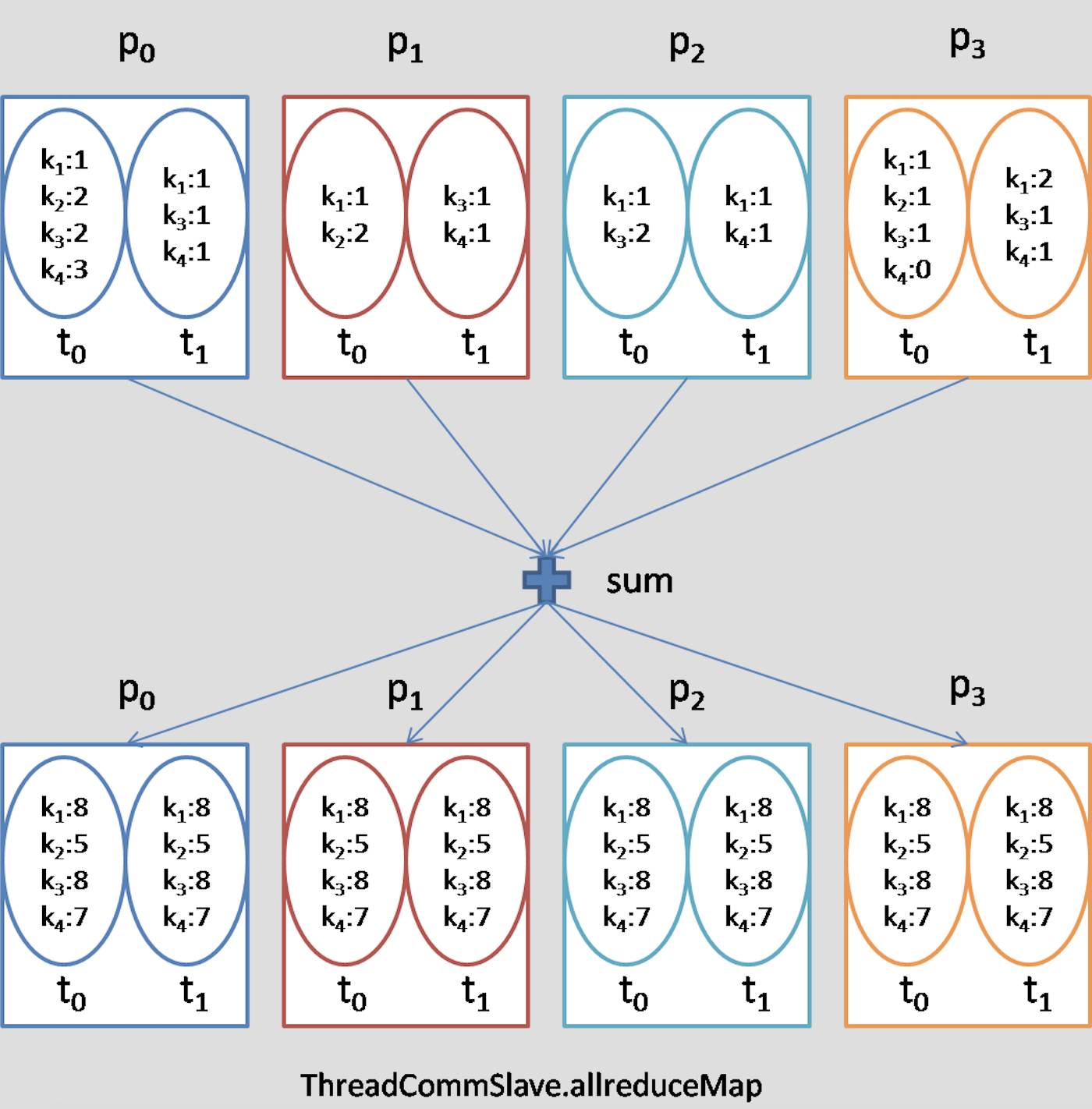
allreduce 操作是分布式机器学习中使用最多的通信操作,它对机群中所有的节点对应的数据进行归约操作,然后再分发给各个节点。下面给出了 ytk-mp4j 在多进程、多进程、数组,Map 下的 allreduce (归约操作为求和) 示意图:
性能测试
表 2 给出了 ytk-mp4j 实现的 Collective 操作时间复杂度,其中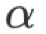
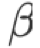
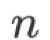
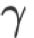
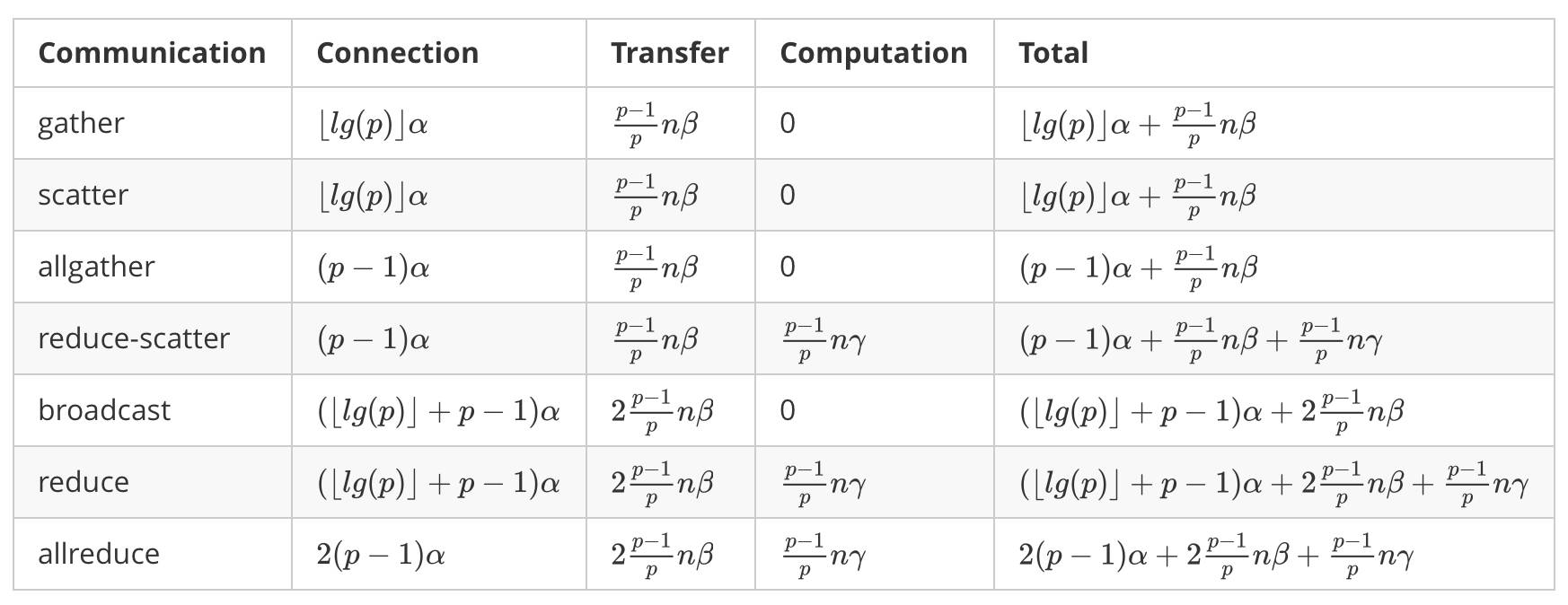
表 2 ytk-mp4j 实现的 Collective 操作时间复杂度
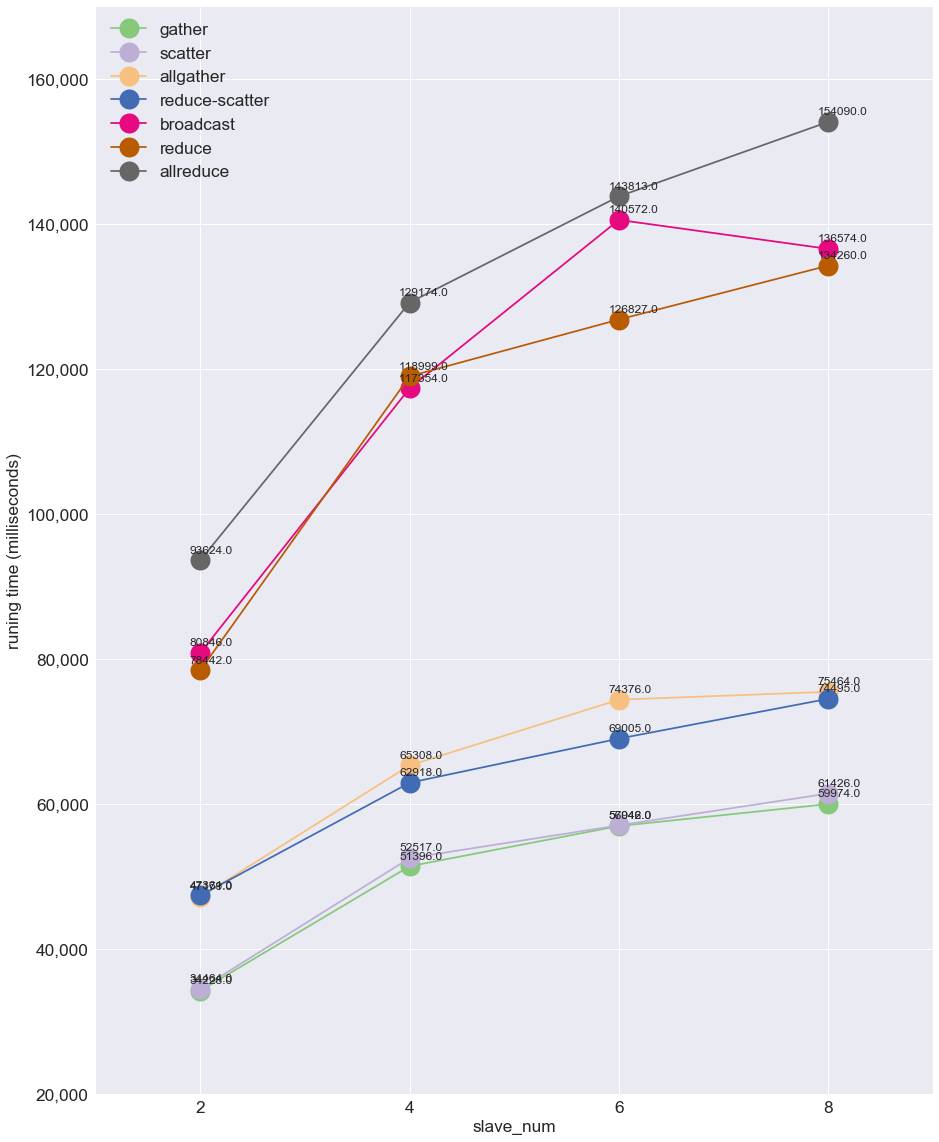
下图是测试在 1Gigabit Ethernet 网络下,10 亿维 double 数组,各种 Collective 通信操作在不同的机器数量下的通信性能 (时间单位: ms),从图中可以看出 ytk-mp4j 中的 7 种 Collective 操作的通信时间与机器数量的关系与理论值完全符合。
详细细节请参考:https://github.com/yuantiku/ytk-mp4j
参考文献
1.Thakur, Rajeev, Rolf Rabenseifner, and William Gropp. "Optimization of collective communication operations in MPICH." The International Journal of High Performance Computing Applications 19.1 (2005): 49-66.
2.Faraj, Ahmad, Pitch Patarasuk, and Xin Yuan. "Bandwidth efficient all-to-all broadcast on switched clusters." Cluster Computing, 2005. IEEE International. IEEE, 2005.
公司简介
猿辅导公司是中国领先的移动在线教育机构,拥有中国最多的中学生移动用户以及国内最⼤的中学生练习行为数据库,旗下有猿题库、小猿搜题、猿辅导三款移动教育 APP。今年 6 月猿辅导获得由华平投资集团领投、腾讯跟投的 1.2 亿美元 E 轮融资,估值超过 10 亿美元,成为国内 K-12 在线教育领域首个独角兽公司。猿辅导研究团队成立于 2014 年年中,致力于在线教育领域的机器学习(尤其是深度学习)相关应用,主要工作包括拍照搜题、手写识别、语音识别、英语作文批改、数据挖掘、自适应学习等。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击阅读原文,查看机器之心官网↓↓↓



