业界 | 英特尔深度学习产品综述:如何占领人工智能市场
机器之心原创
作者:Haojin Yang
参与:Jake Zhao、侯韵楚、黄小天
2017 年 2 月 9 日,机器之心技术分析师应邀参加了在 SAP 创新中心召开的英特尔创新研讨会。英特尔数据中心组(Data Center Group , DCG)的成员对目前深度学习及其人工智能产品的发展做了有关介绍。根据本次研讨会的内容,我们可以预测 CPU 硬件生产商(如英特尔)在下一场计算浪潮来袭时的发展趋势或战略,尤其是人工智能的相关方面。
简介
2017 年第一季度,英伟达数据中心收入同比增长 63%,总体收入也得到增长。这一显著增长主要归功于大型 IT 公司,如谷歌和亚马逊主要基于英伟达 GPU 来加速其人工智能云产品的研发。相较而言,在数据中心领域处于霸主地位的英特尔仅增长了 9%。如此悬殊的差距表明,市场中有越来越多的公司正采用深度学习技术;但英特尔已经增加了在深度学习方面的投入与发展力度。本文将就英特尔近期的深度学习产品表达一些见解。
英特尔的人工智能产品
英特尔加强了人工智能硬、软件领域的开发工作。英特尔已在数据中心领域发布了 Xeon 和 Xeon Phi 处理器用于机器学习及其他高性能计算(HPC)应用的通用性案例。为了满足对人工智能日益增长的需求,英特尔还推出了两个用于深入学习模型训练和高效推理的优化产品:
训练:英特尔 Xeon 处理器 + 英特尔深度学习引擎「Lake Crest」,「Lake Crest」具有同类之最的神经网络性能,并能提供前所未有的高带宽互连的计算密度。
推理:英特尔 Xeon 处理器 + FPGA(ARRIA 10)。FPGA 引擎可定制和编程,能提供带有用于机器学习推理的更高 perf/w 的低延迟以及灵活的精度。该解决方案专为机器学习应用的高效推理和实时预过滤而设计。
下述章节将提供有关 Lake Crest 、英特尔 FPGA 解决方案 ARRIA 10 以及 Xeon Phi 深度学习模型训练评估结果的更多细节。
Lake Crest
英特尔深度学习引擎「Lake Crest」是一款新型芯片产品,可实现神经网络计算的硬件级优化。与可编程的 FPGA 相比,硬件网络的优势主要在于:像 Lake Crest 这样的芯片在运行时能与代码相适应,并且网络也会在硬件层面进行更新。Lake Crest 具有基于架构的张量,其内存层次结构具有以下特点:高维度(> 2)张量是默认的数据类型;没有应用缓存机制,由编译器分配内存。这些张量可读为转置或定期。它始终具有 ECC 保护,且应用比 DDR4 快 12 倍的 HBM2 RAM。
Lake Crest 的另一项重要创新是数据传输,并拥有高带宽互连——具有 6 个用于 3D 环面互连的双向链接,这些链接比 PCIe 快 20 倍。Lake Crest 的 12 个计算单元直接连接到所有其他计算单元,其吞吐率高达每秒 100 千兆字节。
Lake Crest 支持用于深度模型的 16 个 FlexPoint,且聚焦于优化占据大部分神经网络执行时间的 Mat-Mult 和 Convolution。它还支持如(A ^ 2 * 4B)+ C 这样复杂的 GEMM 函数、自动矩阵阻塞以及部分乘积相加等。
在 Lake Crest 中设计的具体数据类型如图 1 所示。

图 1: Lake Crest 支持的数据类型(图片来自英特尔)。
FlexPoint 引擎能够实现基于 12x100Gbps interc 和 32 GB HDM2 RAM 的 50TOP。2017 年底将推出基于深度学习平台的 Lake Crest,而 2018 年底将推出下一代英特尔深度学习芯片「Spring Crest」,其能使用 8g winograd 实现 80-90 的 TOP。
Arria 10 FPGA
Arria 10 是英特尔目前用于机器学习的最新一代 FPGA,它的计算能力可以单精度达到 1.5 TF,Int16 达到 3 个 TOP,Int8 达到 6 个 TOP。2017 年末将计划发布下一代 FPGA——「Stratix 10」,它的计算能力将更强大,单精度高达 9 TF,而 Int16 / 8 则会高达 18/36 TOP。
英特尔为安装 Arria 10 FPGA 模块提供了两种选择:作为单独的 PCIe 组件进行安装,即将来的「离散」版本;另一方面,它可被集成到在内部与处理器直接相连的 Xeon 处理器包中,并在外部与 FPGA 模块之间直接提供一个连接管道,从而实现灵活的数据访问,这便是「集成」版本。
表 1 和 2 显示了使用 Arria 10 FPGA 组件的 Xeon 处理器的吞吐量以及能耗。(所有统计数据收集自英特尔的公开资料。)

表 1:使用 Arria 10 离散版本的英特尔 Xeon
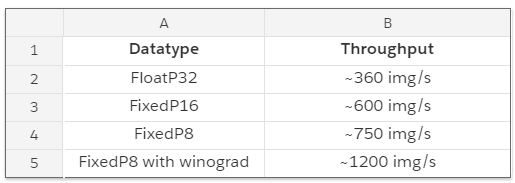
表 2:分类任务中「集成」版本的吞吐量。表中的结果基于以 224x224x3 作为输入、1000x1 为输出的 AlexNet 分类。
Xeon Phi Knights Mill
Xeon Phi 处理器被定义为高性能的通用机器学习应用程序。2017 年最新发布的是使用 Groveport 平台的「Knights Landing」(KNL)。下一代芯片「Knights Mill」将在年末推出,它将具有以下计算功能:单精度达到 13.8TF,VNNI 中达到 27.6TOP。VNNI 通过使用 Int16 输入来支持 2 倍的每秒浮点计算,并且使用 Int32 输出可以实现与单精度类似的精度。
图 2 显示了使用 MxNet 框架对各种深度模型进行推理速度测试的一些基准结果。与开箱即用的性能相比,它经过硬件级别的优化后,可在 2S Intel Xeon 处理器 E5 2699v4 上实现高达 123 倍的提速。
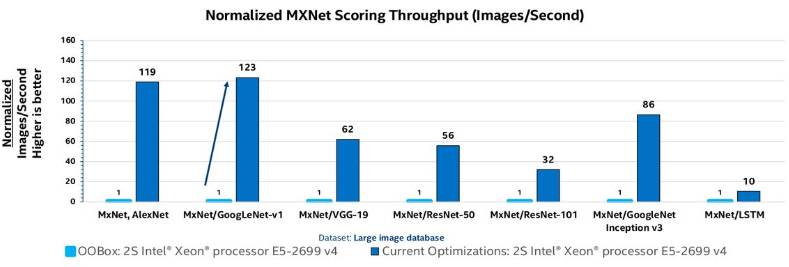
图 2:对已优化的英特尔微处理器进行推理测试(本图来自英特尔)。
英特尔推出 Knight Mill&Groveport 平台来优化训练性能,该平台在速度、内存以及一致性方面做了整体改进。它具有适于深度学习训练负荷的高度分布式多节点扩展,能实现高于 KNL 2.5 倍的单精度性能提升。分布式多节点扩展可以越过多达 72 个内核。它具有集成式 16 GB MC DRAM 的高内存带宽,且具有用于大量人工智能使用案例的 384GB 的 6 通道 DDR4 存储能力。本地支持通用的英特尔 Xeon 编程,且该框架已针对开源机器学习框架的行业标准进行了优化,其单精度峰值性能可高达 13.8TF。
据英特尔报告称,与在 2S 英特尔 Xeon 处理器 E5 2699 v4 中开箱即用的性能相比,它能以优化为基础,实现高达 340 倍的性能提升用于训练 TensorFlow 中的 VGG 模型。此外,如图 3 所示,它可以在英特尔 Xeon Phi 处理器 7250 上实现高达 273 倍的累积加速来训练 VGG 模型。
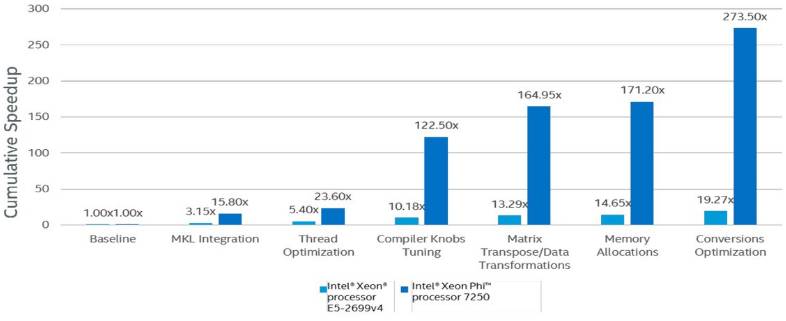
图 3:已优化的英特尔微处理器的累积加速(本图来自 Intel)。
图 4 显示了使用英特尔 Omni Path Fabric 的 GoogleNet v1 扩展至英特尔 Xeon Phi 处理器 7250 中多达 32 个节点集群的训练时间,图中表明,最大扩展效率高达 97%。
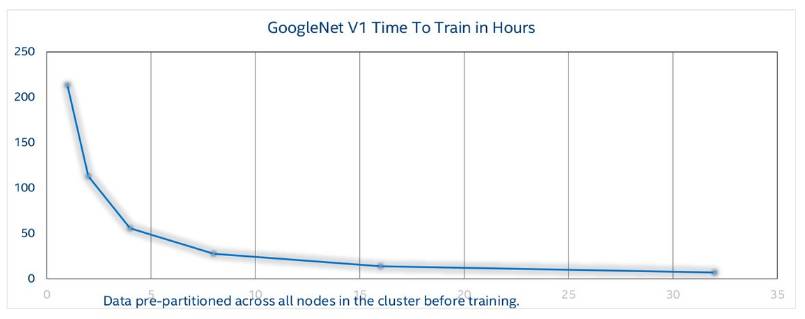
图 4:扩展训练时间。X 轴:节点集群的数量,Y 轴:小时数(本图来自英特尔)。
软件及工具
软件也是英特尔人工智能计算基础的重要组成部分。图 5 显示了英特尔在深度学习/机器学习环境中所开发的软件库以及工具。
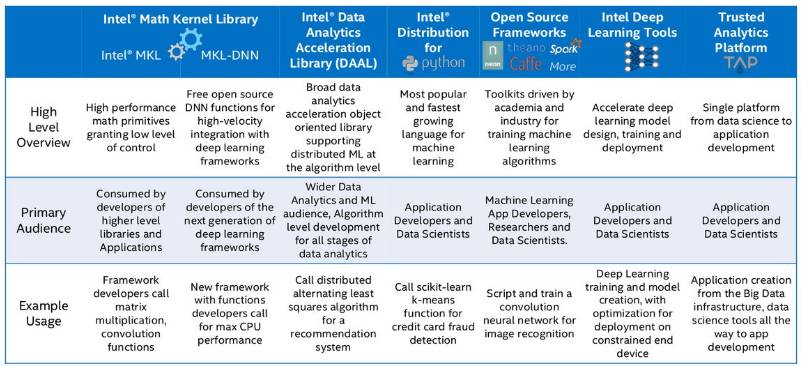
图 5:英特尔的深度学习软件及工具(本图来自英特尔)。
很明显,英特尔正试图为深度学习/人工智能产品构建完整的计算基础。它的深度学习平台不仅支持所有主流的开源深度学习库,而且专为快速充电的深度神经网络提供了更优的数学内核库 MKL-DNN。我们把这样的库看作计算原语(computational primitive),但英特尔的机器学习扩展库作为通信原语使用。
最近英特尔的研究团队在 FPGA'17 会议上发表了一篇名为「FPGA 在下一代深度神经网络的加速中能否胜过 GPU」的论文,该论文对基于英特尔 FPGA 产品 Arria 10 和 Stratix 10 加速深度学习模型的性能提升进行了深入实验,并相交于目前英伟达的 TitanX Pascal GPU 做出了评估。结果表明,用于深度学习时,英特尔的 FPGA 解决方案与最先进的 GPU 处理器相比更具竞争力。

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




