Twitch表情中的情绪分析

近年来,人们在社交媒体平台上 越来越多地使用emoji、表情符号、颜文字、GIF 以及各种非文字的表达方式,这让数据科学家们在研究全球范围的社会学格局时愈发艰难,但从人们公开的发言中还是能找到全球化社会学的一些趋势的。
尽管在过去的十年里,自然语言处理(NLP)是个非常强大的情绪分析工具,但它不仅跟不上快速更新发展、跨语言的网络词汇和缩写,面对脸书和推特等社交网站上以图为主的帖子也束手无策。
因为这类研究真正能依靠的超大规模资源只有这些为数不多的大型社交媒体平台,所以人工智能必须要做到与时俱进。
今年七月,一篇论文提出了一种新方法,该方法利用包含了 30000 条推文的数据库,根据用户发到社交网络博文下的“GIF 反应”(见下图),对博文引发的情绪进行归类和预测。该论文发现,这类以图像为主的反应从各方面来说都很容易衡量,因为大多数都不会包含情绪分析中的弱势项:讽刺。

研究学者们将人们使用的动态表情 GIF 称作“还原指标”,并在他们发布于 2021 的论文中分析其用法。
2021 年上半年,波士顿大学带领研究团队通过训练 机器学习模型 预测推特上可能会流行的梗图。2021 年八月,英国学者们通过研究社交媒体中人们使用表情符号(指图像形式的数字、字母和标点)或 emoji(指图像形式的人脸、物品和符号)的趋势对比,整合了一个包含七种语言的大型推特情绪数据集。
现在,美国的研究者们已经开发出了一种机器学习训练方法,可以更好地理解、归类并测量 Twitch(国外一游戏直播平台)上不断发展变化的颜文字(emotes)伪词汇。
颜文字 emotes 是指 Twitch 上用来表达情绪、情感或小众笑话的新造词。因为其定义便是新造表情,所以对于机器学习系统来说,最难的并不是对源源不断新产生的新表情进行归类,总结的速度恐怕还赶不上他们过气的速度;我们要让机器能更好地理解这些表情背后的结构,并开发系统将这些颜表情识别为“临时”的单词或组合短语,而其所代表的情感则完全需要依靠上下文情景来判断。
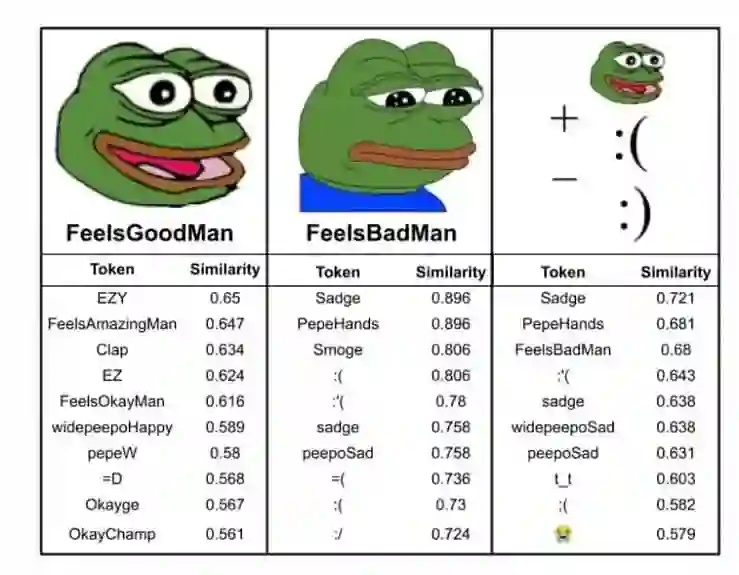
与快乐蛙相类似的颜文字,简单更改后缀其含义便完全不同了。
上图来自旧金山的一家社交媒体分析公司中的三位研究者发布的论文,《快乐蛙:推断 Twitch 中新造词背后的情绪含义 (https://arxiv.org/pdf/2108.08411.pdf)》。
尽管这些表情新鲜一时又多数短命,但 Twitch 经常会把旧表情素材挖出来回收利用,让饱经训练的情绪分析框架判断错误。通过追溯表情在演变过程中含义的变化,经常会发现他们现在所代表的情感或意图与最初创造时完全是天翻地覆。
举例来说,研究者们注意到由于极右翼对快乐蛙梗图的滥用,这个表情几乎完全失去了它在 Twitch 上最初流行时代表的政治含义。
快乐蛙的形象和它那句经典的“真不错兄弟(Feels Good Man)”,最初是出现在 2005 年美国插画家 Matt Furie 的一本漫画中,随后在 2010 年左右变成了极右翼的代表梗图。Vox 曾在 2017 年发文称,虽然 Furie 自称与其撇清关系,但这种右翼挪用后所代表的含义还是流传了下来,但这篇论文背后的旧金山研究人员却并不认同:
在 2010 年早些时候,Furie 创作的卡通青蛙形象被 4chan(外网匿名论坛)等各种线上论坛中的右翼用作宣传。而从那时起,Furie 一直在努力赢回青蛙 Pepe 本身的意义,而在 Twitch 上,大量非仇恨、积极的青蛙表情成为了主流,让快乐蛙和它对应的悲伤蛙用法更加倾向表情的字面意义。
后续麻烦
这种梗图的常见表达含义在爆红后又转换的情况经常会让 NLP 研究项目进展受挫。毕竟这些表情已经被打上了“仇恨”或者“民族主义 (US)”这类标签,并且打包扔进了长期开源仓库里。后续使用这些数据的 NLP 研究项目可能并不会检查数据的正确性,有的会是因为没有数据审计的手段,有的则可能是压根没意识到审计的需要。
这种过期标签的后果很明显,如果在 2017 年使用 Twitch 表情数据集来训练一个“政治分类”的算法,那么归功于悲伤蛙表情的大量使用,我们将观测到 Twitch 上有非常明显的极右翼倾向。当然,也许 Twitch 确实充满了极右翼的主播们,但你并不能靠青蛙头来验证这点。
悲伤蛙梗图的政治意义似乎被 Twitch 上 1.4 亿的用户(其中 41% 的用户未满 24 岁不客气地抛弃了。他们不约而同地从盗图的政治家手中非常效率地将青蛙 Pepe 夺了回来,重新用自己的方式将其定义。
研究者们发现带标签的 Twitch 颜文字数据集“几乎不存在”,虽然先前有研究称他们共使用了八百万的 Twitch 表情,而其中 40 万都是在同一周内造出来的。
2017 年的一份预测 Twitch 上流行颜文字的研究],在将预测范围限制在了前 30 后,仍然只有 0.39 的得分。
为应对这一难题,旧金山的研究者对旧数据使用了新方法,将训练集和测试集的比例分成了 80/20,并采用了朴素贝叶斯,随机森林(RF)、支持向量(SVM,用线性核),以及逻辑回归(Logistic Regression),这些之前并未在 Twitch 数据中使用过的“传统”机器学习算法。
这种算法的性能和先前研究的基准线相比高出了 63.8%,而研究人员借此开发的 LOOVE(“从词汇中学习情绪”的英文缩写)框架做到了新词汇的识别,并将这些全新的定义添加到现有的模型中。
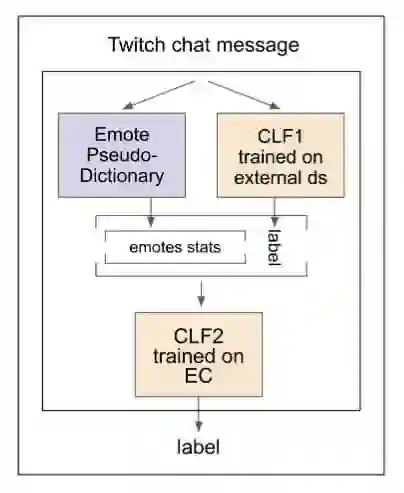
研究人员开发的 LOOVE(Learning Out Of Vocabulary Emotions)框架结构
LOOVE 在无监督训练嵌入词上大展身手,通过定期再训练和微调避免了对标记数据集的需求。考虑到表情的数量和其演化的速度,实时更新标记数据集非常的不现实。
在项目中,研究者们用一个未标记的 Twitch 数据集训练一个颜文字的“伪字典”,在训练过程中,模型生成了 444,714 个单词、颜文字和 emoji 的嵌入。
此外,他们在 VADER 词典中新增了 emoji 和表情符号词汇,除了之前提到的 EC 数据集之外,他们还利用来自推特、烂番茄和 YELP(外网一美食点评网站)采样这三个公开可用的数据集进行三元感情的分类。
由于项目中使用了不止一种方法和数据集,其结果也各不相同,但可以肯定的是,项目中表现最优的基准线比先前研究要高出 7.36 个百分点。
研究者认为,该项目的后续价值是在于 LOOVE 框架的继续开发,借助 K 最邻近法(KNN)和 word-to-vector(W2V)的嵌入训练 Twitch 上超过 3.31 亿条的聊天数据。
论文作者总结道:框架背后的功能驱动是可用于预测未知表情情感的颜文字的伪词典。利用这个颜文字的伪词典,我们创建了一个包含 22,507 个表情的情绪表,可以说是第一个如此规模的颜文字解读案例。
原文链接:
https://www.unite.ai/understanding-twitch-emotes-in-sentiment-analysis/
今日好文推荐
知名开源公司上市造就亿万富翁,创始人不做CEO只想做码农
程序员们,是时候重新关注下企业架构了!
阿里高层大地震,蒋凡不再管天猫;豆瓣回应下架:认真整改;传快手裁员30%;Rust明年或成Linux第二官方语言 | Q资讯
突发!Log4j 爆“核弹级”漏洞,Flink、Kafka等至少十多个项目受影响

点个在看少个 bug 👇





