【机器学习】关于机器学习算法 你需要了解的东西;机器学习方法体系汇总;图解机器学习十大算法;机器学习中的数学基础
关于机器学习算法 你需要了解的东西
摘要: 对学习算法进行分类是基于构建模型时所需的数据:数据是否需要包括输入和输出或仅仅是输入,需要多少个数据点以及何时收集数据。根据上述分类原则,可以分为4个主要的类别:监督学习、无监督学习、半监督学习和强化学习。
算法、模型和数据
从概念层面上来讲,我们正在构建一个机器,给这个机器一组输入数据,然后通过找到数据中的模式并从中学习,能够产生某种预期的输出。
一种非常常见的情况就是让机器在一组输入数据中查找,然后产生相对应的输出数据。机器在输入数据中识别出模式,并创建一组复杂的规则,然后将其应用于以前从未见过的输入并产生所需的输出。例如,给定房屋的面积、地址和房间数(输入),我们来预测房屋的销售价格(输出)。假设我们有10000组这样的数据,包括房屋的面积、地址、房间数量,以及销售价格。则机器会基于这些数据“训练”自己,即识别出房间面积、地址、房间数影响房屋价格的模式,这样,只要我们给出一个从未见过的房子的3个输入项,就可以预测出房子的价格了。
数据科学家的作用是找到给定输入并能够获得预期输出的最佳机器。她有多个模板,对于机器来说,称之为**算法**。从这些模板中生成的解决具体问题的机器被称为**模型**。模板有各种不同的选项和设置,可以通过调整这些选择和设置来从同一模板生成不同的模型。还可以使用不同的模板或调整相同模板的设置来生成多个模型,以便测试出哪个模型能提供最佳结果。
请注意,模型输出只是在一定概率上对决策是正确的或者有用的。模型并不是100%正确的,而是根据模型所看到的大量数据而进行的“最佳猜测”。模型看到的数据越多,提供有用输出的可能性就越大。
数据科学家用来“训练”机器的已知输入和输出集合(即让模型识别数据中的模式并创建规则)叫做“**训练集**”。该数据用于与一个或多个“模板”一起创建用于解决问题的一个或多个模型。记住,即使只使用了一个“模板”(算法),也可以通过调整某些选项来从同一模板生成多个模型。
在得到了几个“训练过”的模型之后,就必须对它们进行检查,看看它们是否能正常工作,哪一个最有效。用来检查的一组新的数据称为“**验证集**”。将验证集作为输入,然后运行模型,查看哪一个模型输出的结果最接近验证集的输出。在我们上面的例子中,就是看哪一种模型预测出来的房屋的价格与实际售价最接近。在这个阶段中,需要有一组新的数据来作为验证集,因为这些模型是根据训练集创建的,所以它们在训练集上能够工作得很好,不会给出真实的结果。
一旦验证了哪种模型性能最佳并选择了最优者,我们的数据科学家就需要确定该模型的实际性能,也就是说,这个最好的模型在解决问题方面到底好到什么程度。再一次,我们需要另外一个新的数据集,因为模型在训练集和验证集上都能表现良好!这最后一个数据集称为“**测试集**”。在我们的例子中,系统会检查对于用测试集作为输入预测出来的房价有多接近测试集的实际价格。
“学习”的类型
应用于解决机器学习问题的算法类型取决于你所拥有的数据。对学习算法进行分类是基于构建模型时所需的数据:数据是否需要包括输入和输出或仅仅是输入,需要多少个数据点以及何时收集数据。根据上述分类原则,可以分为4个主要的类别:监督学习、无监督学习、半监督学习和强化学习。
监督学习
我们在上一节中详细讨论的案例描述了我们所说的“监督学习”。这种学习类型需要有大量**标记数据**示例,即由输入和相应的输出组成的数据。在我们的房屋价格示例中,“标记”是指用模型预测的结果来对输入进行标记。
在监督学习算法中可以看到标记数据(也称为“**参考标准**”数据),从这些数据中学习并根据这些实例进行预测。他们需要大量的标记数据:虽然数据的数量取决于用例,但几百个数据点是最起码的。
使用监督学习解决的两个经典问题是:
回归。根据其他明显的数据集对变量产生的影响来推断未知变量的值。在时间预测中有两个常见用途。例如,我们之前的那个根据位置和面积等变量来预测住宅价格的例子,以及预测未来价格,例如,根据历史和目前的价格数据,预测房屋从现在到一年以后的价格。回归是一种统计方法,它用于确定自变量(你已拥有的数据)与其所需预测值的因变量之间的关系。
分类。确定实体属于多个类别中的哪一个类别。这可以是一个二元分类,例如,确定某个帖子是否会像病毒一样传播(是/否);也可以是多标签分类,例如,在产品照片上标记合适的类别(可能有数百个类别)。
无监督学习
在无监督学习中,算法在试图识别数据中模式的时候,无需使用预期结果来标记数据集。数据是“未标记的”,即没有附加任何有意义的标记。通过无监督学习方法可以解决一些经典问题:
聚类给定某个相似性标准,找出哪些与其他另外一个更相似。使用聚类的一个领域是文本搜索,例如,返回的搜索结果包含了很多非常相似的文档。聚类可用来将它们进行分组,让用户更方便地识别出差异较大的文档。
关联。根据某种关系将对象分类到不同的桶中,这样,桶中某个物体的存在预示着另一个物体也存在。比如类似于“买了xxx的人也买了yyy”这样的推荐问题:如果对大量的购物车进行分析,则可以看出,购物车中商品xxx的存在很有可能暗示着产品yyy也在购物车中,那么,你可以立即向将产品xxx放入购物车的人推荐产品yyy。
异常检测在需要标记和处理的数据中识别意外模式。标准的应用范围包括了对复杂系统的欺诈检测和健康监测。
半监督学习
这是监督学习和无监督学习混合的结果,在这种“学习”中,算法需要一些训练数据,但是比监督学习的要少很多(可能要差一个数量级)。其算法可以是在监督学习和无监督学习中使用的方法的扩展:分类、回归、聚类、异常检测等等。
强化学习
算法以有限的数据集开始,在学习的同时,还可以获得更多关于其预测的反馈信息,以进一步改善学习效果。
正如你所看到的,除了要解决的问题类型外,你所拥有的数据量也会影响到你所能使用的学习方法。这也适用于另一种方式:你需要使用的学习方法可能需要比你现在拥有的更多的数据,这样才能有效地解决你的问题。我们稍后再讨论这个。
其他常见的“流行语”
在你的工作中,还会遇到其他一些术语。了解他们与我们今天谈论到的类别之间的关系很重要。
深度学习与上面的那些定义并没有什么关系。它只是应用特定类型的系统来解决学习问题,其解决方案可以是监督的,也可以是无监督的,等等。
人工神经网络(ANN)是一种学习系统,它试图通过不同层上的“神经”网络来模拟我们大脑的工作方式。神经网络至少有一个输入层(即数据被摄入网络的一组神经元),一个输出层(将结果传递出来的神经元)以及两者之间的一个或多个层,称为“隐藏层”(真正做计算工作的层)。深度学习只是使用具有多个隐藏层的神经网络来完成学习任务。如果你曾经使用过这样的网络,恭喜你,你也可以合理地扔掉这个时髦术语了!
集合方法或**综合学习**是使用多个模型来获得结果,这样比利用单个模型获得的结果要更好。这些模型可以采用不同的算法,或是使用不同参数的相同算法。比如,对于某种类型的预测,你有一组模型,每一个模型都能产生一个预测,有一些处理方法能够平衡不同的预测结果,并决定应该输出什么样的组合。集合方法通常用于监督学习(它们在预测问题中非常有用),但也可以用于无监督学习。你的数据科学团队可能会测试这些方法,并在适当的时候使用它们。
自然语言处理(NLP)是计算机科学领域的一门研究机器理解语言的学科。不是所有类型的NLP都使用机器学习。例如,如果我们生成一个“标签云”(一个词出现在文本中的次数的视觉表示法),这就不涉及学习。对语言和文字的更加复杂的分析和理解往往需要机器学习。这里有一些例子:
关键字生成。理解正文的主题并自动为其创建关键字。
语言歧义。从一个词或一句句子的多种可能的解释中确定相关的含义。
情绪分析理解在文字中表达出来的情绪的积极或者消极的程度。
命名实体提取在文本中识别公司、人员、地点、品牌等等;当这些名称并不特殊时,要提取出来就会特别困难(例如,公司“微软”比公司“目标”更容易识别,因为“目标”是英文中的一个单字)。
NLP不仅用于机器学习领域里面向语言的应用,例如chatbots,它也被广泛用于准备和预处理数据,这样,这些数据才能成为许多机器学习模型的有用输入。我们稍后在讨论这个。
请注意:上面的定义是为了表达其主要思想,让大家更易理解;对于详细的科学定义,请参考其他来源。
问题如何影响解决方案(另外还有一些关键的机器学习概念)
用机器学习来实现的战略目标将决定许多下游决策。为了确保你的数据科学团队能为业务生成正确的解决方案,了解一些基本的机器学习概念及其对业务目标的影响是非常重要的。
算法的选择
在问题定义上的一个小变动可能需要有一个完全不同的算法来解决,或者至少要使用不同的数据输入来构建不同的模型。一个能够为用户识别照片类型的约会网站可以使用无监督学习技术(比如聚类)来识别常见的主题。而如果要向特定的某个人推荐潜在的约会对象,则网站可能要使用基于输入的监督学习,输入数据需具体到个人,例如他们已经看过的照片。
特征的选择
机器学习模型识别数据中的模式。输入到模型中的数据被组织成特征(也称为变量或属性):这些特征都是相关的、大部分独立的数据片段,描述了你想要预测或识别的现象的某些方面。
以前文提到的那家希望优先考虑贷款申请人外展服务的公司为例。如果我们将问题定义为“根据客户转换的可能性优先考虑”,我们将会得到包括类似客户对公司各种外展活动的响应率等特征。如果我们将问题定义为“优先考虑最可能偿还贷款的客户”,我们就不会得到这些特征,因为它们与评估客户的可能性无关。
目标函数的选择
目标函数是你要优化的目标,或者是模型试图预测的结果。例如,如果你向用户推荐他们可能感兴趣的商品,则模型的输出可能是用户在看到商品时点击该商品的概率,也可能是用户购买商品的概率。目标函数的选择主要取决于业务目标,在这个例子中,你对用户的参与感兴趣(目标函数可能是点击或停留的时间)还是对营业收入感兴趣(目标函数是购买)?另一个要考虑的关键因素是数据的可用性:对于要学习的算法,你必须提供大量“标记”为正(用户看到并点击的产品)或负(用户看到的产品,但没有点击)的数据点。
文章原标题《What You Need to Know About Machine Learning Algorithms and Why You Should Care》,作者:Yael Gavish,译者:夏天,审校:主题曲哥哥。
文章为简译,更为详细的内容,请查看原文
文章来源:云栖社区
机器学习方法体系汇总
来源:机器学习算法与Python学习
监督学习 Supervised learning
人工神经网络 Artificial neural network
自动编码器 Autoencoder
反向传播 Backpropagation
玻尔兹曼机 Boltzmann machine
卷积神经网络 Convolutional neural network
Hopfield网络 Hopfield network
多层感知器 Multilayer perceptron
径向基函数网络(RBFN) Radial basis function network(RBFN)
受限玻尔兹曼机 Restricted Boltzmann machine
回归神经网络(RNN) Recurrent neural network(RNN)
自组织映射(SOM) Self-organizing map(SOM)
尖峰神经网络 Spiking neural network
贝叶斯 Bayesian
朴素贝叶斯 Naive Bayes
高斯贝叶斯 Gaussian Naive Bayes
多项朴素贝叶斯 Multinomial Naive Bayes
平均一依赖性评估(AODE) Averaged One-Dependence Estimators(AODE)
贝叶斯信念网络(BNN) Bayesian Belief Network(BBN)
贝叶斯网络(BN) Bayesian Network(BN)
决策树 Decision Tree
分类和回归树(CART) Classification and regression tree (CART)
迭代Dichotomiser 3(ID3) Iterative Dichotomiser 3(ID3)
C4.5算法 C4.5 algorithm
C5.0算法 C5.0 algorithm
卡方自动交互检测(CHAID) Chi-squared Automatic Interaction Detection(CHAID)
决策残端 Decision stump
ID3算法 ID3 algorithm
随机森林 Random forest
SLIQ
线性分类 Linear classifier
Fisher的线性判别 Fisher's linear discriminant
线性回归 Linear regression
Logistic回归 Logistic regression
多项Logistic回归 Multinomial logistic regression
朴素贝叶斯分类器 Naive Bayes classifier
感知 Perceptron
支持向量机 Support vector machine
无监督学习 Unsupervised learning
人工神经网络 Artificial neural network
对抗生成网络
前馈神经网络 Feedforward neurral network
极端学习机 Extreme learning machine
逻辑学习机 Logic learning machine
自组织映射 Self-organizing map
关联规则学习 Association rule learning
先验算法 Apriori algorithm
Eclat算法 Eclat algorithm
FP-growth算法 FP-growth algorithm
分层聚类 Hierarchical clustering
单连锁聚类 Single-linkage clustering
概念聚类 Conceptual clustering
聚类分析 Cluster analysis
BIRCH
DBSCAN
期望最大化(EM) Expectation-maximization(EM)
模糊聚类 Fuzzy clustering
K-means算法 K-means algorithm
k-均值聚类 K-means clustering
k-位数 K-medians
平均移 Mean-shift
OPTICS算法 OPTICS algorithm
异常检测 Anomaly detection
k-最近邻算法(K-NN) k-nearest neighbors classification(K-NN)
局部异常因子 Local outlier factor
半监督学习 Semi-supervised learning
生成模型 Generative models
低密度分离 Low-density separation
基于图形的方法 Graph-based methods
联合训练 Co-training
强化学习 Reinforcement learning
时间差分学习 Temporal difference learning
Q学习 Q-learning
学习自动 Learning Automata
状态-行动-回馈-状态-行动(SARSA) State-Action-Reward-State-Action(SARSA)
深度学习 Deep learning
深度信念网络 Deep belief machines
深度卷积神经网络 Deep Convolutional neural networks
深度递归神经网络 Deep Recurrent neural networks
分层时间记忆 Hierarchical temporal memory
深度玻尔兹曼机(DBM) Deep Boltzmann Machine(DBM)
堆叠自动编码器 Stacked Boltzmann Machine
生成式对抗网络 Generative adversarial networks
迁移学习 Transfer learning
传递式迁移学习 Transitive Transfer Learning
其他
集成学习算法
Bootstrap aggregating (Bagging)
AdaBoost
梯度提升机(GBM) Gradient boosting machine(GBM)
梯度提升决策树(GBRT) Gradient boosted decision tree(GBRT)
降维
主成分分析(PCA) Principal component analysis(PCA)
主成分回归(PCR) Principal component regression(PCR)
因子分析 Factor analysis
图解机器学习十大算法
导读:通过本篇文章可以对ML的常用算法有个常识性的认识,没有代码,没有复杂的理论推导,就是图解一下,知道这些算法是什么,它们是怎么应用的,例子主要是分类问题。
1. 决策树
根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
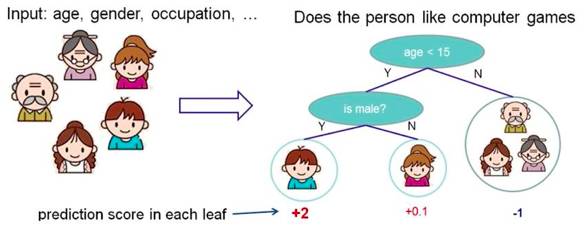
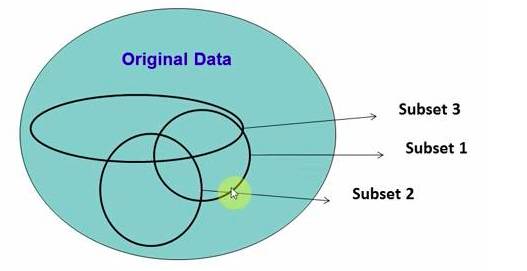
2、随机森林
在源数据中随机选取数据,组成几个子集:
S矩阵是源数据,有1-N条数据,A、B、C 是feature,最后一列C是类别:
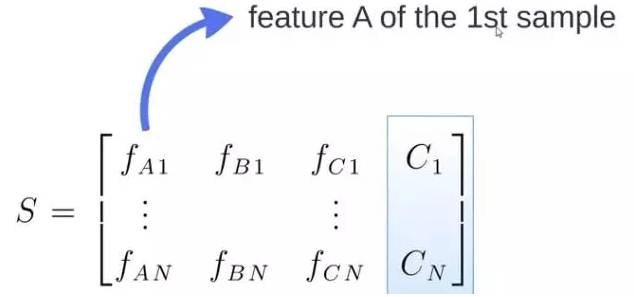
由S随机生成M个子矩阵:

这M个子集得到 M 个决策树:
将新数据投入到这M个树中,得到M个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果。
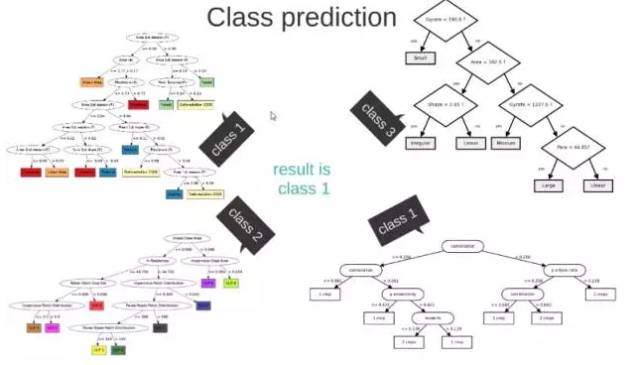
3、逻辑回归
当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
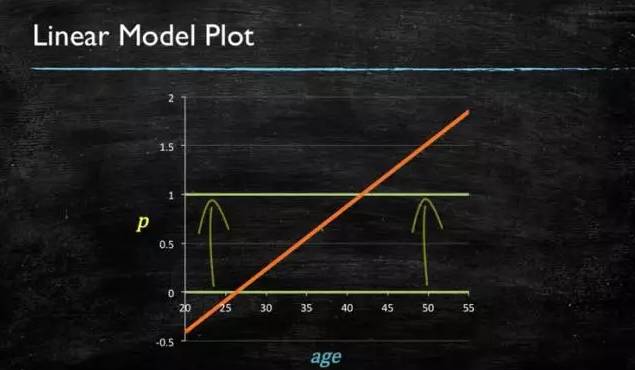
所以此时需要这样的形状的模型会比较好:
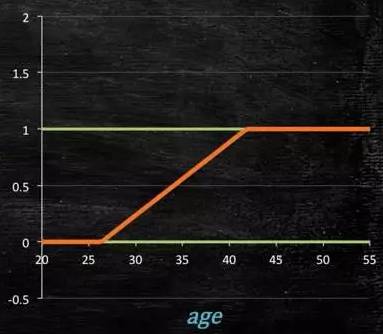
那么怎么得到这样的模型呢?
这个模型需要满足两个条件 “大于等于0”,“小于等于1”
大于等于0 的模型可以选择绝对值,平方值,这里用指数函数,一定大于0;
小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了。
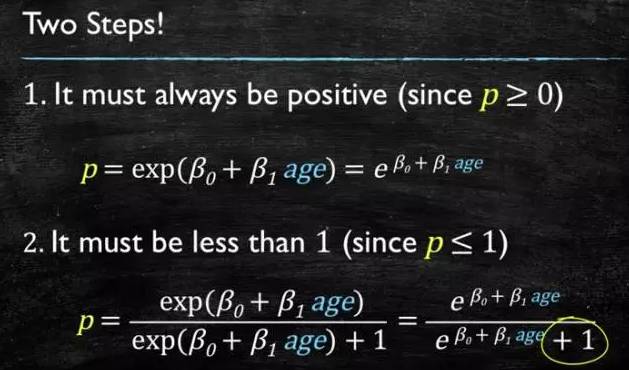
再做一下变形,就得到了 logistic regressions 模型:

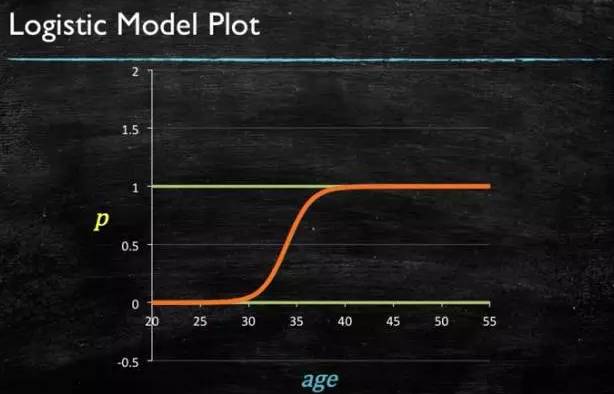
通过源数据计算可以得到相应的系数了:

最后得到 logistic 的图形:
4、SVM
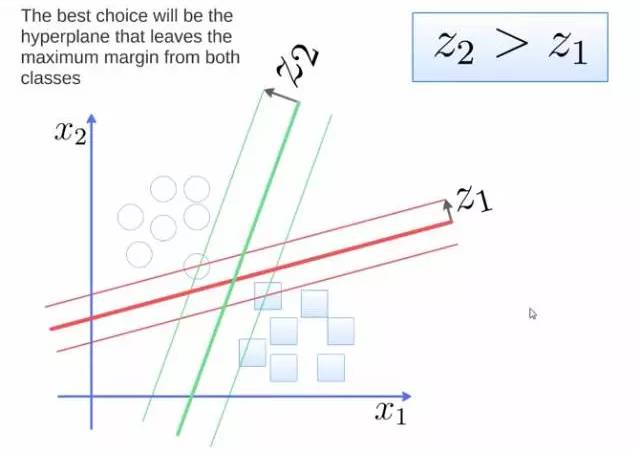
要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好。
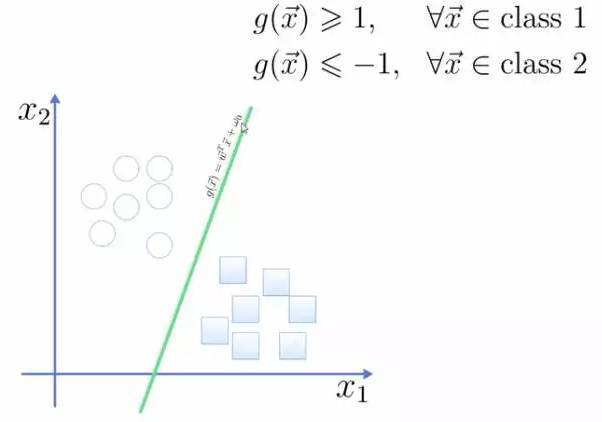
将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类小于等于-1:
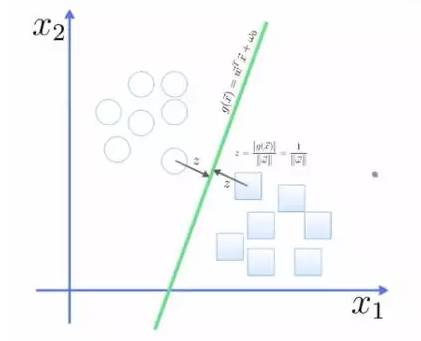
点到面的距离根据图中的公式计算:
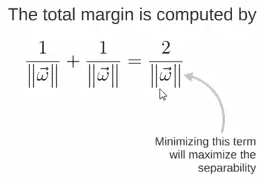
所以得到total margin的表达式如下,目标是最大化这个margin,就需要最小化分母,于是变成了一个优化问题:
举个例子,三个点,找到最优的超平面,定义了 weight vector=(2,3)-(1,1):
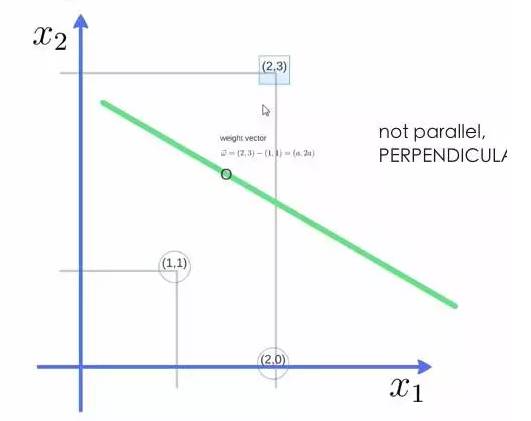
得到weight vector为(a,2a),将两个点代入方程,代入(2,3)另其值=1,代入(1,1)另其值=-1,求解出 a 和 截矩 w0 的值,进而得到超平面的表达式。
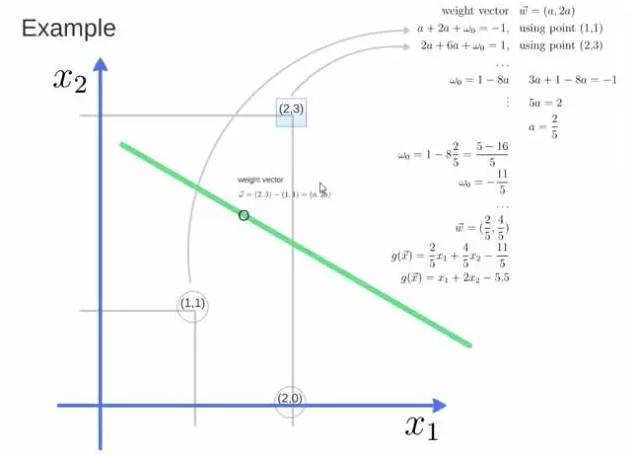
a求出来后,代入(a,2a)得到的就是support vector,
a和w0代入超平面的方程就是support vector machine。
5、朴素贝叶斯
举个在 NLP 的应用:
给一段文字,返回情感分类,这段文字的态度是positive,还是negative:

为了解决这个问题,可以只看其中的一些单词:

这段文字,将仅由一些单词和它们的计数代表:
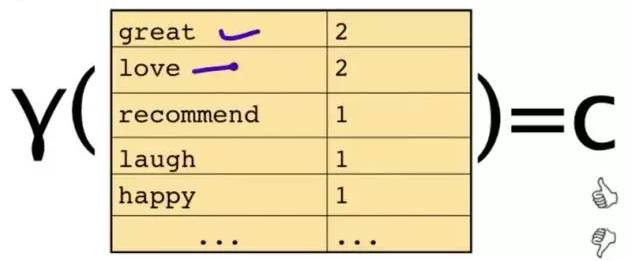
原始问题是:给你一句话,它属于哪一类 ?
通过bayes rules变成一个比较简单容易求得的问题:

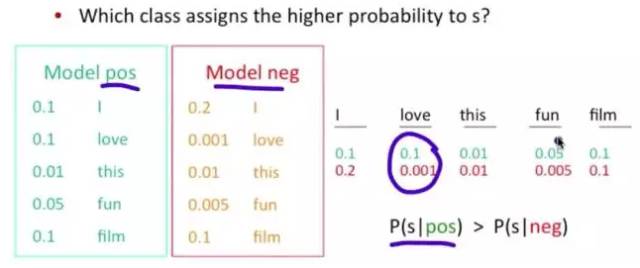
问题变成,这一类中这句话出现的概率是多少,当然,别忘了公式里的另外两个概率。
例子:单词“love”在positive的情况下出现的概率是 0.1,在negative的情况下出现的概率是0.001。
6、K最近临算法
给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类。
例子:要区分“猫”和“狗”,通过“claws”和“sound”两个feature来判断的话,圆形和三角形是已知分类的了,那么这个“star”代表的是哪一类呢?
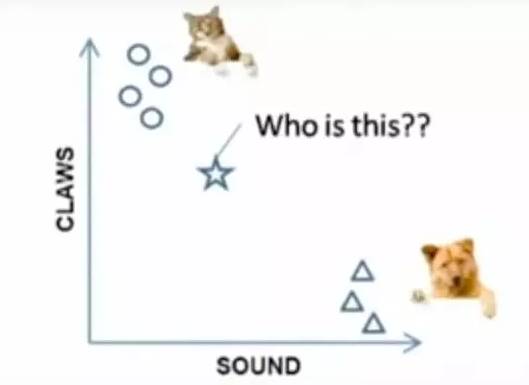
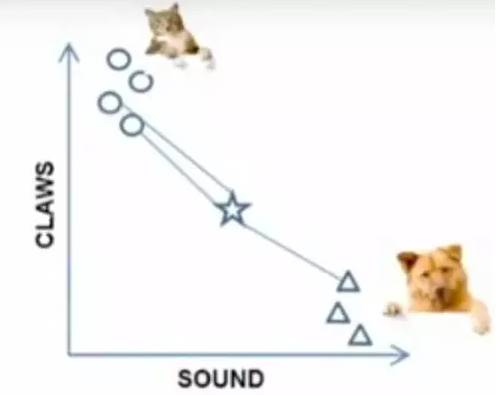
k=3时,这三条线链接的点就是最近的三个点,那么圆形多一些,所以这个star就是属于猫。
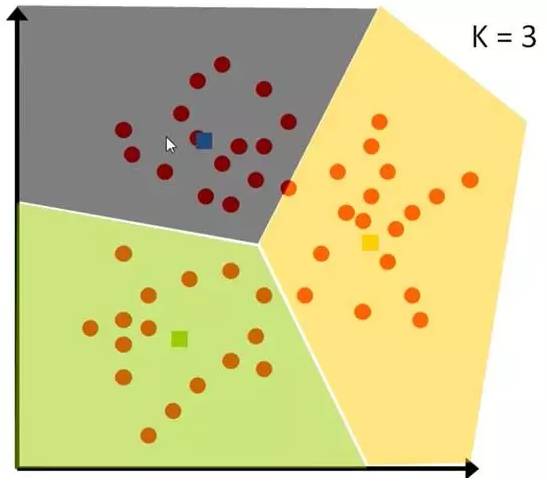
7、K均值算法
先要将一组数据,分为三类,粉色数值大,黄色数值小 。
最开始先初始化,这里面选了最简单的 3,2,1 作为各类的初始值 。
剩下的数据里,每个都与三个初始值计算距离,然后归类到离它最近的初始值所在类别。

分好类后,计算每一类的平均值,作为新一轮的中心点:

几轮之后,分组不再变化了,就可以停止了:

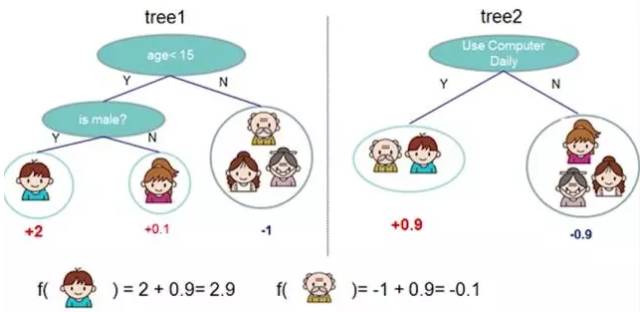
8、Adaboost
adaboost 是 bosting 的方法之一。
bosting就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。
下图,左右两个决策树,单个看是效果不怎么好的,但是把同样的数据投入进去,把两个结果加起来考虑,就会增加可信度。
adaboost 的例子,手写识别中,在画板上可以抓取到很多 features,例如始点的方向,始点和终点的距离等等。
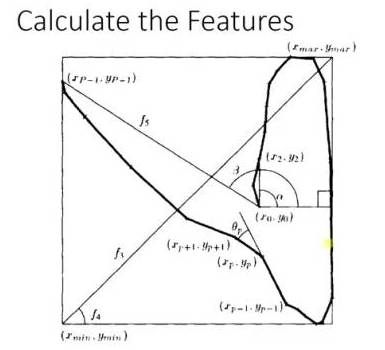
training的时候,会得到每个feature的weight,例如2和3的开头部分很像,这个feature对分类起到的作用很小,它的权重也就会较小。

而这个alpha角就具有很强的识别性,这个feature的权重就会较大,最后的预测结果是综合考虑这些feature的结果。

9、网络神经
Neural Networks适合一个input可能落入至少两个类别里:
NN由若干层神经元,和它们之间的联系组成。
第一层是input层,最后一层是output层。
在hidden层和output层都有自己的classifier。
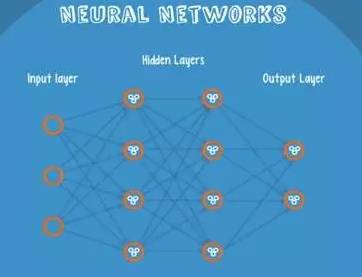
input输入到网络中,被激活,计算的分数被传递到下一层,激活后面的神经层,最后output层的节点上的分数代表属于各类的分数,下图例子得到分类结果为class 1;
同样的input被传输到不同的节点上,之所以会得到不同的结果是因为各自节点有不同的weights 和bias,这也就是forward propagation。

10、马尔可夫
Markov Chains 由state和transitions组成。
例子,根据这一句话 ‘the quick brown fox jumps over the lazy dog’,要得到markov chains。
步骤,先给每一个单词设定成一个状态,然后计算状态间转换的概率。
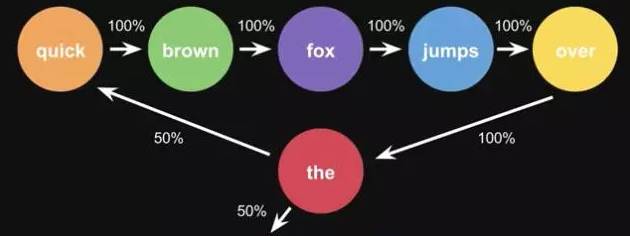
这是一句话计算出来的概率,当你用大量文本去做统计的时候,会得到更大的状态转移矩阵,例如the后面可以连接的单词,及相应的概率。
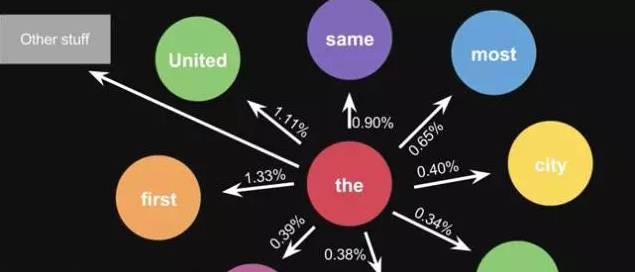
生活中,键盘输入法的备选结果也是一样的原理,模型会更高级。

此链接可观看详细视频讲解:
https://www.leiphone.com/news/201707/nL57wR7ZtbfsRgDR.html?viewType=weixin
机器学习中的数学基础
导语:现在出现了很多易于使用的机器学习和深度学习的软件包,例如 scikit-learn, Weka, Tensorflow 等等。机器学习理论是统计学、概率学、计算机科学以及算法的交叉领域,是通过从数据中的迭代学习去发现能够被用来构建智能应用的隐藏知识。尽管机器学习和深度学习有着无限可能,然而为了更好地掌握算法的内部工作机理和得到较好的结果,对大多数这些技术有一个透彻的数学理解是必要的。


逻辑回归和神经网络的代价函数的计算方法
为什么要重视数学?
机器学习中的数学是重要的,有很多原因,下面我将强调其中的一些:
1. 选择正确的算法,包括考虑到精度、训练时间、模型复杂度、参数的数量和特征数量。
2. 选择参数的设置和验证策略。
3. 通过理解偏差和方差之间的 tradeoff 来识别欠拟合与过拟合。
4. 估计正确的置信区间和不确定度。
你需要什么水平的数学?
当你尝试着去理解一个像机器学习(ML)一样的交叉学科的时候,主要问题是理解这些技术所需要的数学知识的量以及必要的水平。这个问题的答案是多维的,也会因个人的水平和兴趣而不同。关于机器学习的数学公式和理论进步正在研究之中,而且一些研究者正在研究更加先进的技术。下面我会说明我所认为的要成为一个机器学习科学家/工程师所需要的最低的数学水平以及每个数学概念的重要性。
1. 线性代数:我的一个同事 Skyler Speakman 最近说过,「线性代数是 21 世纪的数学」,我完全赞同他的说法。在机器学习领域,线性代数无处不在。主成分分析(PCA)、奇异值分解(SVD)、矩阵的特征分解、LU 分解、QR 分解、对称矩阵、正交化和正交归一化、矩阵运算、投影、特征值和特征向量、向量空间和范数(Norms),这些都是理解机器学习中所使用的优化方法所需要的。令人惊奇的是现在有很多关于线性代数的在线资源。我一直说,由于大量的资源在互联网是可以获取的,因而传统的教室正在消失。我最喜欢的线性代数课程是由 MIT Courseware 提供的(Gilbert Strang 教授的讲授的课程):http://ocw.mit.edu/courses/mathematics/18-06-linear-algebra-spring-2010/
2. 概率论和统计学:机器学习和统计学并不是迥然不同的领域。事实上,最近就有人将机器学习定义为「在机器上做统计」。机器学习需要的一些概率和统计理论分别是:组合、概率规则和公理、贝叶斯定理、随机变量、方差和期望、条件和联合分布、标准分布(伯努利、二项式、多项式、均匀和高斯)、时刻生成函数(Moment Generating Functions)、最大似然估计(MLE)、先验和后验、最大后验估计(MAP)和抽样方法。
3. 多元微积分:一些必要的主题包括微分和积分、偏微分、向量值函数、方向梯度、海森、雅可比、拉普拉斯、拉格朗日分布。
4. 算法和复杂优化:这对理解我们的机器学习算法的计算效率和可扩展性以及利用我们的数据集中稀疏性很重要。需要的知识有数据结构(二叉树、散列、堆、栈等)、动态规划、随机和子线性算法、图论、梯度/随机下降和原始对偶方法。
5. 其他:这包括以上四个主要领域没有涵盖的数学主题。它们是实数和复数分析(集合和序列、拓扑学、度量空间、单值连续函数、极限)、信息论(熵和信息增益)、函数空间和流形学习。
一些用于学习机器学习所需的数学主题的 MOOC 和材料是(链接经过压缩):
可汗学院的线性代数(http://suo.im/fgMNX)、概率与统计(http://suo.im/CqwY9)、多元微积分(http://suo.im/xh6Zn)和优化(http://suo.im/1o2Axs)
布朗大学 Philip Klein 的「编程矩阵:计算机科学应用中的线性代数(Coding the Matrix: Linear Algebra through Computer Science Applications)」:http://codingthematrix.com
得克萨斯大学的 Robert van de Geijn 在 edX 上的 Linear Algebra – Foundations to Frontiers:http://suo.im/hKRnW
戴维森学院 Tim Chartier 的新课程 Applications of Linear Algebra;第一部分:http://suo.im/48Vary,第二部分:http://suo.im/3Xm3Lh
Joseph Blitzstein 的 Harvard Stat 110 lectures:http://suo.im/2vhVmb
Larry Wasserman 的书《All of statistics: A Concise Course in Statistical Inference》,下载:http://suo.im/v9u7k
斯坦福大学的 Boyd 和 Vandenberghe 的关于凸优化的课程:http://suo.im/2wdQnf
Udacity 的 Introduction to Statistics 课程:http://suo.im/1enl1c
吴恩达授课的 Coursera/斯坦福大学的机器学习课程:http://suo.im/1eCvp9
这篇博文的主要目的是给出一些善意的关于数学在机器学中的重要性的建议,一些一些必需的数学主题以及掌握这些主题的一些有用的资源。然而,一些机器学习的痴迷者是数学新手,可能会发现这篇博客令人伤心(认真地说,我不是故意的)。对于初学者而言,你并不需要很多的数学知识就能够开始机器学习的研究。基本的吸纳觉条件是这篇博文所描述的数据分析,你可以在掌握更多的技术和算法的过程中学习数学。
-END-

新一代技术+商业操作系统:
AI-CPS OS
在新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生,在行业、企业和自身三个层面勇立鳌头。
数字化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置。
分辨率革命:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品控制、事件控制和结果控制。
复合不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊化:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。随着变革范围不断扩大,一切都几乎变得不确定,即使是最精明的领导者也可能失去方向。面对新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)颠覆性的数字化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位。
如果不能在上述三个层面保持领先,领导力将会不断弱化并难以维继:
重新进行行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建你的企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造新的自己:你需要成为怎样的人?要重塑自己并在数字化时代保有领先地位,你必须如何去做?
子曰:“君子和而不同,小人同而不和。” 《论语·子路》
云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。
在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。
云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
人工智能通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
新一代信息技术(云计算、大数据、物联网、区块链和人工智能)的商业化落地进度远不及技术其本身的革新来得迅猛,究其原因,技术供应商(乙方)不明确自己的技术可服务于谁,传统企业机构(甲方)不懂如何有效利用新一代信息技术创新商业模式和提升效率。
“产业智能官”,通过甲、乙方价值巨大的云计算、大数据、物联网、区块链和人工智能的论文、研究报告和商业合作项目,面向企业CEO、CDO、CTO和CIO,服务新一代信息技术输出者和新一代信息技术消费者。
助力新一代信息技术公司寻找最有价值的潜在传统客户与商业化落地路径,帮助传统企业选择与开发适合自己的新一代信息技术产品和技术方案,消除新一代信息技术公司与传统企业之间的信息不对称,推动云计算、大数据、物联网、区块链和人工智能的商业化浪潮。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发人工智能型企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。
重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)正在经历从“概念”到“落地”,最终实现“大范围规模化应用,深刻改变人类生活”的过程。
产业智能官 AI-CPS
用新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com



