资源 | DeepPavlov:一个训练对话系统和聊天机器人的开源库
选自GitHub
机器之心编译
参与:思源、刘晓坤
本文介绍了一个构建端到端对话系统和训练聊天机器人的开源项目 DeepPavlov,该开源库的构建基于 TensorFlow 和 Keras,并旨在推动 NLP 和对话系统的研究,提升复杂对话系统的实现和评估效果。机器之心简要介绍了该项目和基本技术,希望实现对话机器人的读者可进一步阅读原项目。
项目地址:https://github.com/deepmipt/DeepPavlov
这是一个开源的对话 AI 库,建立在 TensorFlow 和 Keras 上,其用途是:
NLP 和对话系统研究;
复杂对话系统的实现和评估。
我们的目标是为研究者提供:
用于实现和测试他们自己的对话模型并随后将模型共享的框架;
一系列预定义的 NLP 模型/对话系统组件(机器学习/深度学习/规则系统)和流程模板;
对话模型的基准测试环境和对相关数据的系统性评估。
并为 AI 应用开发者提供:
建立对话软件的框架;
将应用与对应基础建设(通讯、技术支持软件等)相集成的工具。
项目特征
格位填充组件(Slot filling component):基于命名实体识别(NER)神经网络和模糊 Levenshtein 搜索,以从文本中提取归一化的格位值(slot values)。NER 网络组件根据论文《Application of a Hybrid Bi-LSTM-CRF model to the task of Russian Named Entity Recognition》重新生成了架构,由《Neural Architectures for Named Entity Recognition》中的 LSTM+CRF 架构所启发。
专用分类组件:基于论文《Convolutional Neural Networks for Sentence Classification》中的 shallow-and-wide CNN 架构。该模型允许语句的多标签分类。
自动拼写和校正组件:基于论文《An Improved Error Model for Noisy Channel Spelling Correction》,并使用基于统计学的误差模型、一个静态词典和一个 ARPA 语言模型以校正拼写错误。
目标导向的对话机器人:基于论文《Hybrid Code Networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning》中的 Hybrid Code Networks 架构。它允许在目标导向任务的对话中预测回应。该模型是相当可定制的:嵌入、格位填充器和专用分类器可以根据需要使用或者不用。
为俄语预训练的嵌入:在联合俄语 Wikipedia 和 Lenta.ru 语料库词向量上进行预训练得到的词嵌入。
简单示例
用 Telegram 部署目标导向的对话机器人和格位填充(slot-filling)的视频 demo:
用 Telegram 接口运行目标导向的对话机器人:
python deep.py interactbot skills/go_bot/config.json -t <TELEGRAM_TOKEN>用控制台接口运行目标导向的对话机器人:
python deep.py interact skills/go_bot/config.json用 Telegram 接口运行格位填充模型:
python deep.py interactbot models/ner/config.json -t <TELEGRAM_TOKEN>用控制台接口运行格位填充模型:
python deep.py interact models/ner/config.json概念简述
原则
这个库遵循以下原则设计:
将端到端学习架构作为长期目标;
目前采用混合的机器学习/深度学习/规则系统的架构;
模块化的对话系统架构;
基于组件的软件工程,最大化复用性;
易于扩展和基准测试;
为单个 NLP 任务提供多个组件,通过数据驱动选择合适的组件。
目标架构
我们的库的目标架构:
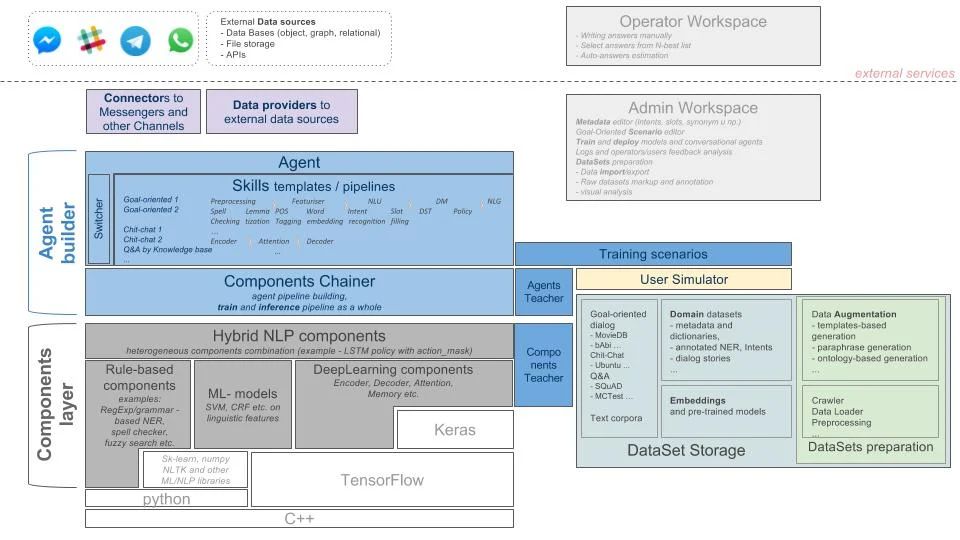
DeepPavlov 建立在机器学习库(TensorFlow、Keras)之上。可以用其它外部的库建立基础组件。
关键概念
Agent(智能体):对话智能体用自然语言(文本)和用户进行交流。
Skill(技能):用于满足用户需求的交互单元。通常可以通过展示信息或完成任务(例如,通过 FAQ 回答问题等);然而,根据经验,某些任务的成功会被定义成连续的进展(例如,闲聊)。
Components(组件):基础功能模块:
Rule-based Components(基于规则的组件)—无法训练;
Machine Learning Components(机器学习组件)—仅能独立训练;
Deep Learning Components(深度学习组件)—可以独立地训练,也能以端对端的方式结合到工作链中。
Switcher(转换器):智能体排序和选择向用户展示的最终应答的机制。
Components Chainer(组件链接器):从各种组件(Rule-based/ml/dl)构建智能体/组件管道的工具,允许以整体的形式训练和推理管道。
技术概览
项目模块

配置
NLP 的流程配置为 JSON 文件,它包含四个元素:
{
"dataset_reader": {
},
"dataset": {
},
"vocabs": {
},
"model": {
}
}配置文件中每一个类都有一个 name 参数,它是注册的代码名。通过重复它的__init__() 方法参数,我们可以定义其它任何参数。__init__() 参数的默认值在类的实例初始化中被配置值覆盖。
数据集读取器
DatasetReader 类能读取数据并返回特定的格式。一个具体的 DatasetReader 类应该从基本的 deeppavlov.data.dataset_reader.DatasetReader 类继承,并注册为代码名:
@register('dstc2_datasetreader')
class DSTC2DatasetReader(DatasetReader):数据集
Dataset 类构成我们所需的数据集(「训练」、「验证」和「测试」)和批量数据。一个具体的 Dataset 类应该注册并可以从 deeppavlov.data.dataset_reader.Dataset 类继承。
deeppavlov.data.dataset_reader.Dataset 类不是抽象类,它同样可以像 Dataset 类那样使用。
词汇
Vocab 是一个可训练的类,它能构建和序列化词汇。Vocab 能索引任何数据,它能索引 X(特征)和 y(回答)类型的数据。一个具体的 Vocab 类应该注册并可以从 deeppavlov.data.vocab.DefaultVocabulary 类继承。
deeppavlov.data.vocab.DefaultVocabulary 并不是一个抽象的类,它同样可以像 Vocab 类那样使用。
模型
Model 是制定训练、推断过程和生成特征的主要类。如果模型需要其它模型生成特征,那么就需要将其传递到构造函数和配置文件中。所有的模型可根据需要嵌套,例如 deeppavlov.skills.go_bot.go_bot.GoalOrientedBot 主要由 11 个独立的 Model 类构建,其中有三个为神经网络:
{
"model": {
"name": "go_bot",
"network": {
"name": "go_bot_rnn"
},
"slot_filler": {
"name": "dstc_slotfilling",
"ner_network": {
"name": "ner_tagging_network",
}
},
"intent_classifier": {
"name": "intent_model",
"embedder": {
"name": "fasttext"
},
"tokenizer": {
"name": "nltk_tokenizer"
}
},
"embedder": {
"name": "fasttext"
},
"bow_encoder": {
"name": "bow"
},
"tokenizer": {
"name": "spacy_tokenizer"
},
"tracker": {
"name": "featurized_tracker"
}
}
}
所有模型都应该注册并从 deeppavlov.core.models.inferable.Inferable 或 Inferable 和 deeppavlov.core.models.trainable.Trainable 接口继承。从 Trainable 继承的模型可以继续训练,从 Inferable 接口继承的模型只能执行推断。通常,Inferable 模型是基于规则的模型或从第三方库导入的预训练模型。
训练
所有从 deeppavlov.core.models.trainable.Trainable 接口继承的模型都可训练,训练过程在 train() 方法中有详细描述。
@register("my_model")
class MyModel(Inferable, Trainable):
def train(*args, **kwargs):
"""
Implement training here.
"""所有在实验中可以改变的训练参数(如 Epoch 数、批量大小、容忍度、学习率个优化器等)都应该传递到模型的构造函数__init__(),且__init__() 中的默认参数值将会被 JSON 配置值覆盖。要改变这些值,我们不需重写代码,只需要修改配置文件就行。
训练过程由 train_now 属性控制。如果 train_now 为真,表示模型正在执行训练。在使用 Vocab 时,这个参数十分有用,因为可以在单个模型中训练一些词汇,而另一些词汇只会在流程中的其它模型上执行推断。JASON 配置文件中的训练参数以设置成:
{
"model": {
"name": "my_model",
"train_now": true,
"optimizer": "Adam",
"learning_rate": 0.2,
"num_epochs": 1000
}
}推断
所有从 deeppavlov.core.models.inferable.Inferable 接口继承的模型都能执行推断。infer() 方法应返回模型可执行的操作,例如分词器应该返回符号、命名实体识别器应该返回识别的实体等。此外,infer() 中应该定义特定格式的返回数据。
推断由 deeppavlov.core.commands.train.infer_model_from_config()函数触发,并不需要单独的 JSON 进行推断,且 train_now 参数在推断中也会被忽略。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


