GitHub出现一个大型中文NLP资源,宣称要放出亿级语料库
乾明 发自 凹非寺
量子位 报道 | 公众号 QbitAI
中文信息很多,但要找到合适的中文语料很难。
有人看不下去了,在GitHub上开了一个项目,专门贡献中文语料资源。
他说,要为解决中文语料难找贡献一份力量。
什么样的资源?
目前,这个项目中一共有3种json版资源:
包含104万个词条的维基百科资源,包含250万篇新闻的新闻语料,以及包含150万个问答的百科类问答资源。
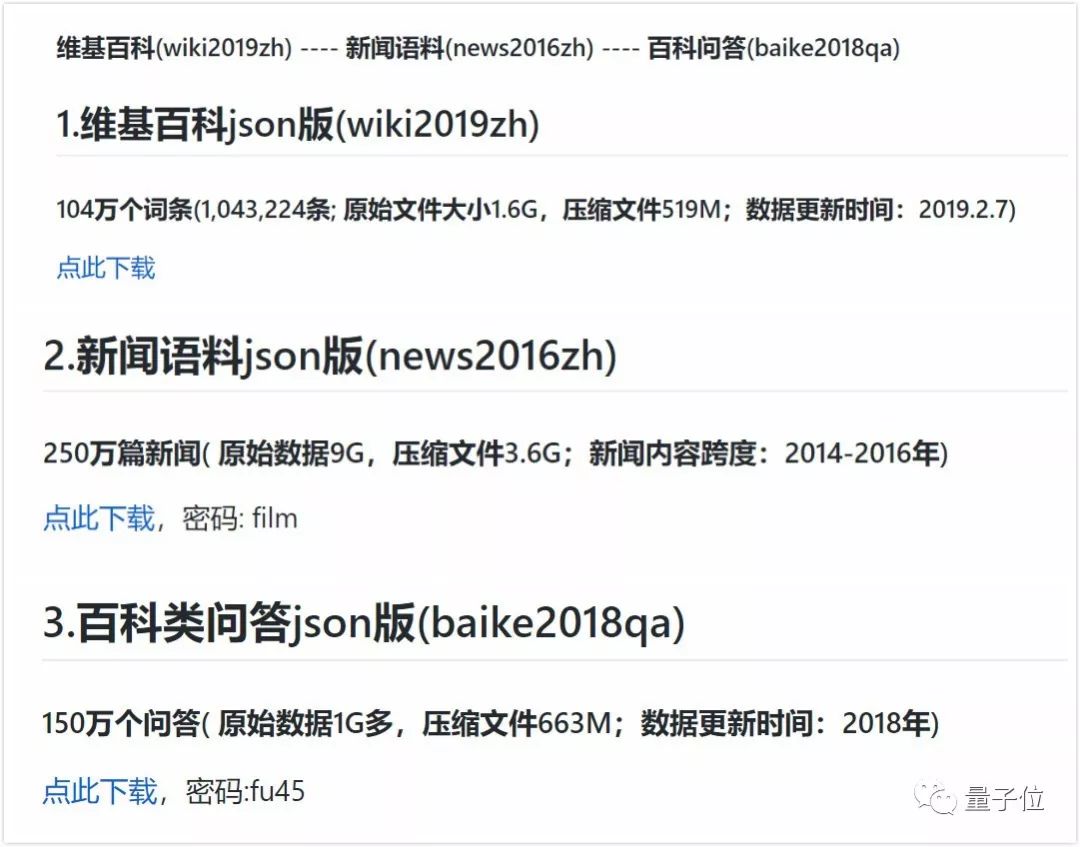
一般来说,这些资源可以作为通用的中文语料,用于预训练或者构建词向量等等。
不同的资源,用处也有不同,比如维基百科和问答百科,可以用来构建知识问答等等。
新闻语料资源,囊括了标题、关键词、描述和正文,也可以用来训练标题生成模型、关键词生成模型等等。
此外,在对数据集划分过的新闻语料和百科类问答资源中,只提供训练集和验证集,不提供测试集数据的下载。
是因为——
希望更多人参与
资源的贡献者表示,希望大家报告模型在验证集上的准确率,并提供模型信息、方法描述、运行方式,以及可运行的源代码(可选)。
这些信息都有的话,资源贡献者会在测试集上测试模型,并给出准确率。
他表示,项目中的语料库将会不断扩充,号召大家多多贡献资源,并给出了相应的目标:
到2019年5月1日,放出10个百万级中文语料&3个千万级中文语料。
到2019年12月31日,放出30个百万级中文语料 & 10个千万级中文语料 & 1个亿级中文语料。
从目前已经有的资源来看,一个语料可以是一个问答,也可以是一个词条等等。
这份资源的贡献者,名为徐亮,杭州实在智能的算法专家,主要关注文本分类、意图识别、问答和面向任务的对话。
如果你有兴趣,请收好资源传送门:
https://github.com/brightmart/nlp_chinese_corpus
此外,量子位之前也介绍过几份中文NLP资源,也一并附于此:
— 完 —
加入社群
量子位现开放「AI+行业」社群,面向AI行业相关从业者,技术、产品等人员,根据所在行业可选择相应行业社群,在量子位公众号(QbitAI)对话界面回复关键词“行业群”,获取入群方式。行业群会有审核,敬请谅解。
此外,量子位AI社群正在招募,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式。
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !





