BERT+知识图谱:北大-腾讯联合推出知识赋能的K-BERT模型

作者丨周鹏
单位丨腾讯
研究方向丨自然语言处理、知识图谱


背景
方法

▲ 图1. K-BERT总体架构图
得到了句子树以后,问题出现了。传统的 BERT 类模型,只能处理序列结构的句子输入,而图结构的句子树是无法直接输入到 BERT 模型中的。如果强行把句子树平铺成序列输入模型,必然造成结构信息的丢失。在这里,K-BERT 中提出了一个很巧妙的解决办法,那就是软位置(Soft-position)和可见矩阵(Visible Matrix)。下面我们详细看看具体的实现方法。
众所周知,在 BERT 中将句子序列输入到模型之前,会给句子序列中的每个 token 加上一个位置编码,即 token 在句子中的位次,例如“Tim(0) Cook(1) is(2) currently(3) visiting(4) Beijing(5) now(6)”。如果没有位置编码,那 BERT 模型是没有顺序信息的,相当于一个词袋模型。
在 K-BERT 中,首先会将句子树平铺,例如图 2 中的句子树平铺以后是“[CLS] Tim Cook CEO Apple is currently visiting Beijing capital China is_a City now”。

▲ 图2. 软位置(Soft-position)和硬位置(Hard-position)
显然,平铺以后的句子是杂乱不易读的,K-BERT 通过软位置编码恢复句子树的顺序信息,即“[CLS](0) Tim(1) Cook(2) CEO(3) Apple(4) is(3) visiting(4) Beijing(5) capital(6) China(7) is_a(6) City(7) now(6)”,可以看到“CEO(3)”和“is(3)”的位置编码都 3,因为它们都是跟在“Cook(2)”之后。
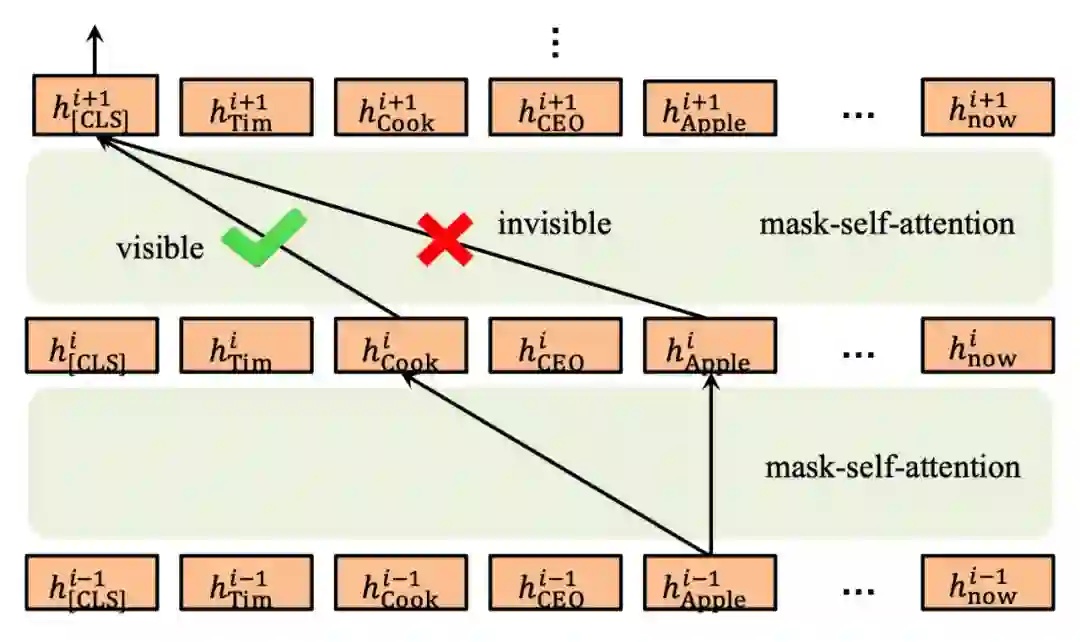
只用软位置还是不够的,因为会让模型误认为 Apple (4) 是跟在 is (3) 之后,这是错误的。K-BERT 中最大的亮点在于 Mask-Transformer,其中使用了可见矩阵(Visible matrix)将图或树结构中的结构信息引入到模型中。
回顾一下 BERT 中 Self-attention,一个词的词嵌入是来源于其上下文。Mask-Transformer 核心思想就是让一个词的词嵌入只来源于其同一个枝干的上下文,而不同枝干的词之间相互不影响。这就是通过可见矩阵来实现的,图 2 中的句子树对应的可见矩阵如图 3 所示,其中一共有 13 个 token,所以是一个 13*13 的矩阵,红色表示对应位置的两个 token 相互可见,白色表示相互不可见。
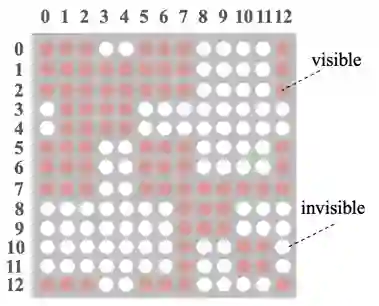
▲ 图3. 可见矩阵(Visible matrix)
有了可见矩阵以后,可见矩阵该如何使用呢?其实很简单,就是 Mask-Transformer。对于一个可见矩阵 M,相互可见的红色点取值为 0,相互不可见的白色取值为负无穷,然后把 M 加到计算 self-attention 的 softmax 函数里就好,即如下公式。

以上公式只是对 BERT 里的 self-attention 做简单的修改,多加了一个 M,其余并无差别。如果两个字之间相互不可见,它们之间的影响系数 S[i,j] 就会是 0,也就使这两个词的隐藏状态 h 之间没有任何影响。这样,就把句子树中的结构信息输入给 BERT 了。
总结一下,Mask-Transformer 接收句子树作为输入的过程如图 5。
▲ 图5. 句子树的输入过程
其实就是对应了原论文中的结构图,如图 6,对于一个句子树,分别使用 Token 序列保存内容,用可见矩阵保存结构信息。
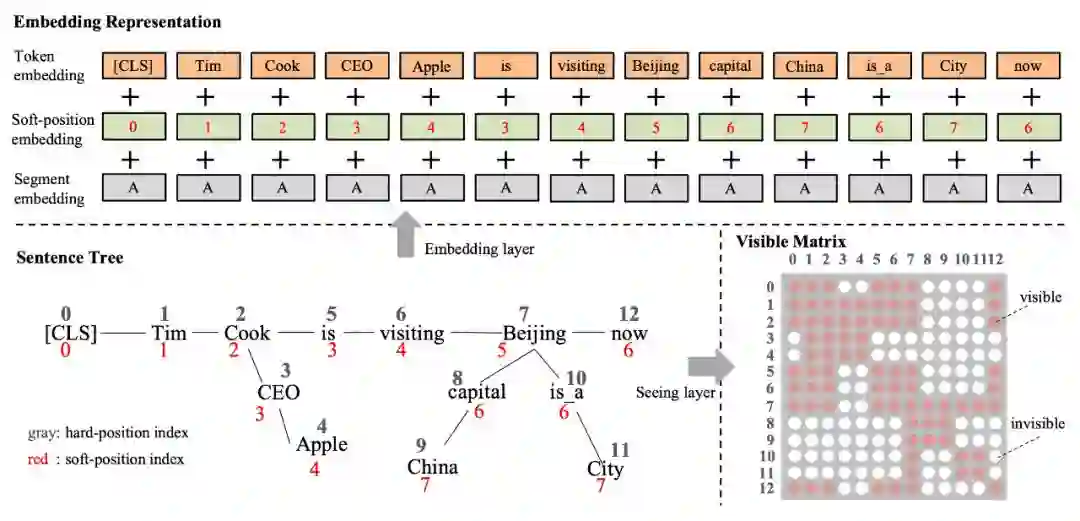
▲ 图6. 句子树转化为Embedding representation和可见矩阵
从图 6 中可以看出,除了软位置和可见矩阵,其余结构均与 Google BERT 保持一致,这就给 K-BERT 带来了一个很好的特性——兼容 BERT 类的模型参数。K-BERT 可以直接加载 Google BERT、Baidu ERNIE、Facebook RoBERTa 等市面上公开的已预训练好的 BERT 类模型,无需自行再次预训练,给使用者节约了很大一笔计算资源。
实验结果
下面我们来看看 K-BERT 的实验效果。首先,本文采用了三个知识图谱,分别是 CN-DBpedia、知网(HowNet)和自建的医学知识图(MedicalKG)。用于测评的任务分为两类,分别是开放领域任务和专业领域任务。开放领域任务一共有 8 个,分别是 Book review、Chnsenticorp、Shopping、Weibo、XNLI、LCQMC、NLPCC-DBQA、MSRA-NER,实验结果如下表。
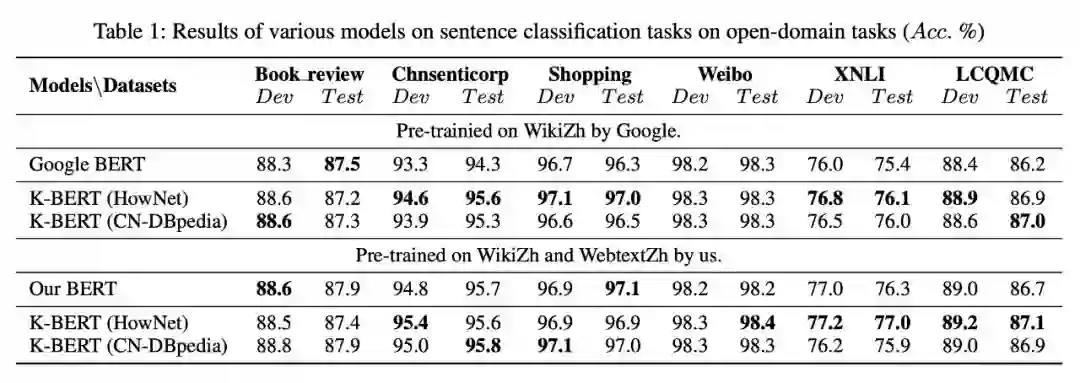
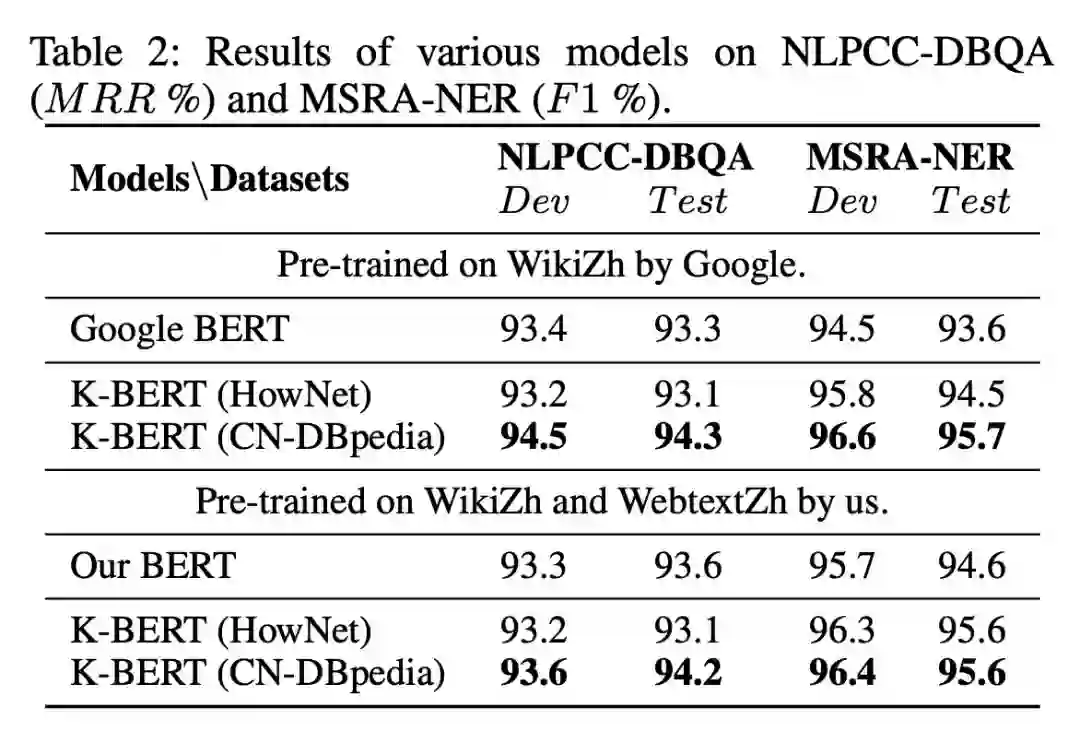
可以看出,K-BERT 相比于 Google BERT,在开放领域的任务上有一点微小的提升,但是提升不是很明显。可能的原因在于开放领域的任务并不需要背景知识。
为了测试在需要“背景知识”的任务上的效果,研究者使用了四个特定领域的任务,分别是金融问答、法律问答、金融实体识别和医学实体识别。实验效果见下图。

可以看出,在特定领域任务上的表现还是不错的,这些特定领域任务对背景知识的要求较高。总体而言,知识图谱适合用于提升需要背景知识的任务,而对于不需要背景知识的开放领域任务往往效果不是很显著。
目前,本工作已被 AAAI-2020 收录。研究者还指出,目前 K-BERT 还存在很多问题需要被解决,例如:当知识图谱质量过差时如何提升模型的鲁棒性;在实体关联时如何剔除因一词多义造成的错误关联。研究者希望将结构化的知识图谱引入到 NLP 社区中,目前还需要做很多努力。K-BERT 还不够完善,将来还会不断更新,欢迎大家关注。
后记
参考文献
[1] Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[2] Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; and Liu, Q. 2019. ERNIE: Enhanced language representation with informative entities. arXiv preprint arXiv:1905.07129.
[3] Xu, B.; Xu, Y.; Liang, J.; Xie, C.; Liang, B.; Cui, W.; and Xiao, Y. 2017. Cn-dbpedia: A never-ending chinese knowl- edge extraction system. International conference industrial, engineering and other applications applied intelligent sys- tems 428–438.
[4] Dong, Z.; Dong, Q.; and Hao, C. 2006. Hownet and the computation of meaning.

点击以下标题查看更多期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码




