【姿态估计比Mask-RCNN提高8%】上交卢策吾团队开源AlphaPose
上海交通大学卢策吾团队开源AlphaPose系统,在姿态估计(Pose Estimation)标准测试集MSCOCO上比现有最好姿态估计开源系统Mask-RCNN相对提高8.2%,比另一常用开源系统OpenPose(CMU)相对提高17%。在MPII排行榜上比第二名相对提高6%。同时,也开源了两个基于AlphaPose的工作:
一个高效率的视频姿态跟踪器(Pose Tracker),目前姿态跟踪准确率第一。
一个新的应用“视觉副词识别“(Visual Adverb Recognition)。
开源系统 |
检测准确率 |
Ours |
72.3 mAP |
Mask-RCNN |
67 mAP (相对提升8.2%) |
OpenPose [1] |
61.8 mAP (相对提升17.3%) |
表格1:现有姿态估计开源系统在COCO数据集[2]上的结果比较。
方法 |
检测准确率 |
Ours |
82.1 mAP |
Newell&Deng, arXiv'16 |
77.5 mAP |
Cao et al., CVPR'17 |
75.6 mAP |
Insafutdinov et al.,CVPR'17 |
74.3 mAP |
表格2:现有方法在MPII数据集[3]上结果比较
AlphaPose姿态估计系统是基于该团队发表在ICCV 2017的RMPE算法。在COCO数据集上报道的结果中,AlphaPose为单模型准确率最高。该模型的训练仅用8块GPU,如果有更大的GPU集群,相信会有更好的效果。
RMPE: Regional multi-person pose estimation ( ICCV'17 )
Hao-shu Fang, Shuqin Xie, Yu-wing Tai and Cewu Lu(通信作者)
主页:http://mvig.sjtu.edu.cn/research/alphapose.html
代码:https://github.com/MVIG-SJTU/AlphaPose
应用一:视频姿态跟踪(Pose Tracking)
在视频中跟踪人体姿态可以帮助我们更好地理解视频中人的行为以及人与周边环境的交互。针对这一问题,我们在AlphaPose的基础上,提出了一种新的姿态跟踪器(Pose Tracker)。目前,该算法在PoseTrack dataset [4]的测试集上达到53.6 MOTA的跟踪精度,大幅度超过该数据集上最好结果(28.2 MOTA),而在PoseTrack Challenge dataset[5]的验证集上达到58.3 MOTA 66.5 mAP,跟踪精度比Facebook最好结果55.2 MOTA 相对提高5.6%,人体姿态估计精度比Facebook之前的最好结果[6] 60.6 mAP 相对提高9.7%。更重要的是我们的视频姿态跟踪器(pose tracker),是基于AlphaPose在每一帧上结果的一个扩展模块,该模块的跟踪速度能达到100FPS。
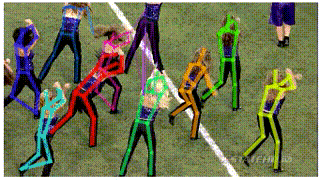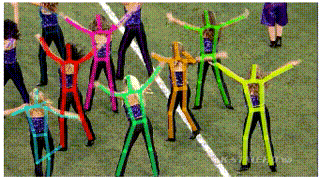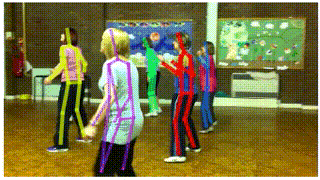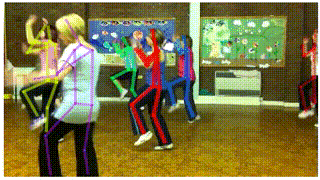

Pose Flow: Efficient Online Pose Tracking (arXiv'18)
Yuliang Xiu, Jiefeng Li, Haoyu Wang, Yinghong Fang, Cewu Lu(通信作者)
论文及代码:http://mvig.sjtu.edu.cn/research/alphapose.html
应用二:视觉副词识别(Visual Adverb Recognition)
计算机视觉学科在努力挖掘图像视频中的语义信息,对于到自然语义系统,是名词识别对应object detection,动词识别对应action recognition。但我们忽略了一类重要语义-副词,这是相对于名词,动词有更为深刻的语义的描述。因此卢策吾团队推出了视觉副词的研究方向,提供了新的ADHA数据集和一个基于AlphaPose的算法,但是目前准确率还是偏低。
Human Action Adverb Recognition: ADHA Dataset and Four-Stream Hybrid Model (arXiv'18)
Bo Pang, Kaiwen Zha and Cewu Lu(通信作者)
主页:http://mvig.sjtu.edu.cn/research/adha/adha.html
数据集:http://mvig.sjtu.edu.cn/research/adha/download.html
Reference
[1] Realtime Multi-Person 2D Pose Estimationusing Part Affinity Fields (CVPR'17) Zhe Cao and Tomas Simon and Shih-En Wei andYaser Sheikh
[2] http://cocodataset.org/#keypoints-challenge2017
[3] http://human-pose.mpi-inf.mpg.de/
[4] PoseTrack: Joint Multi-Person Pose Estimation and Tracking (CVPR'17) Umar Iqbal , Anton Milan, and Juergen Gall.
[5] PoseTrack: A Benchmark for Human Pose Estimation and Tracking (arXiv'17) Andriluka, Mykhaylo and Iqbal
[6] Detect-and-Track: Efficient Pose Estimation in Videos (arXiv'17) Girdhar, Rohit and Gkioxari, Georgia and Torresani, Lorenzo and Paluri, Manohar and Tran, Du

Prof. Cewu Lu is a research Professor at Shanghai Jiao Tong University, leading Machine Vision and Intelligence Group. He was Postdoc at Stanford AI lab (under Fei-Fei Li and Leonidas Guibas) and selected as the 1000 Overseas Talent Plan (Young Talent) (中组部青年千人计划). He is also one of MIT TR35 -"MIT Technology Review, 35 Innovators Under 35 (China)" and co-chair of CVM 2018.


