协作过滤算法
机器学习是一个门槛相对比较高的领域,有很多高大上的算法。其对数学知识有一定的要求,对于一个初学者,尤其是踏上工作岗位数年,已经把大多数数学知识还给老师的IT从业人员来说有一定的难度。但是,也有很多一些相对简单,又非常有用的算法,可以让大家迅速入门并且运用到实际项目之中。在本文中,将介绍这么一个“性价比”较高的算法----协作过滤。
在当今多数的电子商务网站,视频类网站中,协同过滤被用于为用户提供推荐服务。
协作过滤的作用:
既然是推荐服务,以视频为例,要怎么给该用户推荐一些他/她喜欢的视频呢?在日常生活中通常这种推荐行为来源于朋友,身边的人推荐的越多越好看。但是这样的信息来源毕竟不够广泛,之后大家会想到去网上找一些评论。但是这些人品味相差甚远,无法判断哪些人的品味对这些评论对用户自身的价值。
这时候我们就需要协作过滤算法来帮助我们解决这个问题。协作过滤算法是一种对大多数人或者物品进行相似度比较,然后产生一个可靠性较高的推荐列表来提供推荐服务。通俗的说,要为一个人在片海中推荐一些他/她可能喜欢的片子,那么我们先要在很多用户中寻找和其品位相近的用户,然后找出这些用户喜欢看的片子并以分值形式生成一个列表,把这个列表中前几位也就是这些拥有相同爱好的人认为最好的片子推荐给该用户。
协作过滤按用途进行分类:
按照用途可以分为两类。
第一类为寻找类似的人(User_Base):
就像之前部分所说的,按照人群分。然后把兴趣相同人群都喜欢的作品推荐给该用户。
第二类为寻找相似的物(Item_Base):
按照物品或者影片之间的相似度,给用户推荐与当前物品/影片相似度较高的。
协作过滤算法的组成结构:
协作过滤分为两个重要阶段,第一个阶段是计算相关系数,第二个阶段是预测评分。
相关系数计算:
相关系数计算是个非常重要的环节,是通过人们对物品的打分计算出人与人之间的相似度。而支持这个阶段的算法有很多,比如欧几里得距离、皮尔逊相关度、哈曼吨距离、Jaccard、spearman等方法,在实际应用中很难说清楚哪个好,需要每位机器学习人员或者是数据挖掘人员在具体业务使用中慢慢尝试,慢慢摸索,至少这里的每种算法都有其特点,都值得一试。而本文中将重点介绍欧几里得距离和皮尔逊相关度。
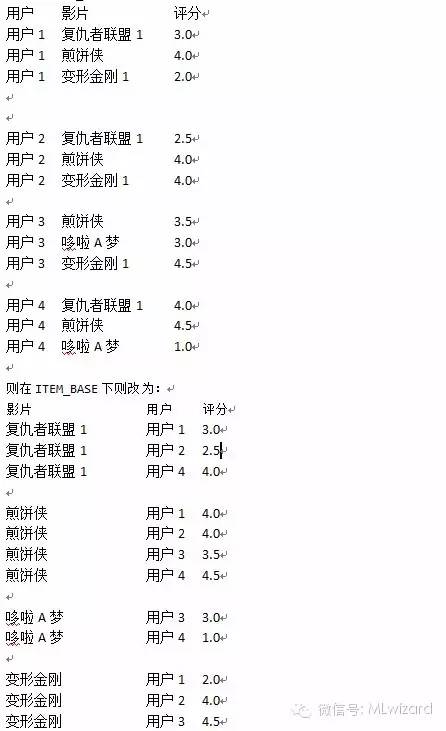
首先我们来看一组数据:
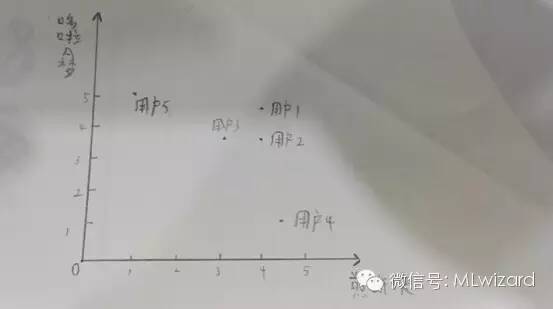
欧几里得距离就是以片子为轴,算出所有用户之间距离。如图1所示。距离越近相似度也就越高。图1是一个二维图。
其算法公式为:0ρ = sqrt( (x1-x2)^2+(y1-y2)^2 )|x| =√( x2 + y2 )
这个公式把所有用户坐标的X轴值和Y轴值两两相减平方后,把结果想家得出相似度系数,其数值越大越不相似。
通过以上公式算的:
用户1和用户3的相关度系数值为:0.37617851153
用户1 和用户5的相关度系数值为:0.147791668134
也如图1所示,用户1相比用户5和用户3的距离更接近,也就是和用户3的相似度更高
皮尔逊相关度:
皮尔逊相关度算法是一种比欧几里得系数更为复杂的相关系数算法。欧几里得的算法是计算用户之间的距离,而皮尔逊则是计算两组数据关于一条直线的拟合程度的一种度量计算。拟合值越高其相关性也就越高。这种算法相比欧几里得距离更为常用,因为这种算法可以修正实际评分的夸大值(也就是说有些用户喜欢打极端的打分,喜欢的就打5分,不喜欢的就给1分,但是别的用户喜欢给4分,不喜欢给2分。其实这些用户拥有相同的兴趣爱好,只是打分的习惯不同而已)。
其计算公式为:
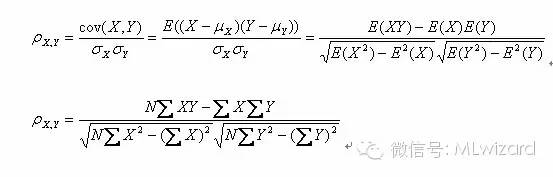
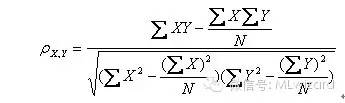
现在我们用两组图片来现实其算法的含义,及如何判断哪两个用户的相似度更高。

图2和图3反映了两组用户用皮尔逊算法所产生的相似度情况,图2为用户1和用户2做对比,而图3是用户1和用户5做对比,通过5部片子的数据情况对比,从图上可以看出,用户1和用户2的相似度高于用户1和用户5(图2和图3相比,图2上的点更贴近直线)。那么事实是不是这样的呢?
通过上面的计算公式,得出图2两用户的相似度为0.661616764014,而图3两用户的相似度为-0.612372435696。按照数值越接近1相似度越高原则,用户1相对用户5而已,和用户2的相似度更高。
这里有个有趣的情况,图3的两个用户的相似度值为负数,而图中直线的走向是向下的。这个并不是错误,而是另一种情况,叫负相关,通俗的说法就是越接近-1,说明两个用户的兴趣为相反的而不是相似的。图3正好证明用户1和用户5存在一定的相反性。
相关系数的介绍到此为止。在此要重申一遍,各种相似度算法都有其特定的应用场景,需要根据具体的应用场景选择更合适的算法,在用推荐算法做推荐功能时,不断的测试每种算法是一个非常必要的过程。
预测评分:
在完成相似度计算以后,我们获得一个相似度的列表,然后我们就要做推荐了
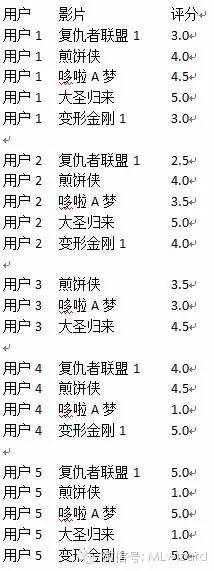
既然是推荐别人看片,肯定是推荐被推荐人没看过的片子。这里我们用用户3为例(因为他看过的片子最少),然后再扩充一下我们的数据集,否则太寒酸了。把原数据集扩充为如下:
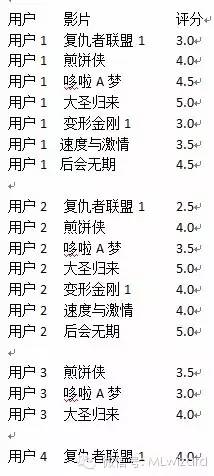
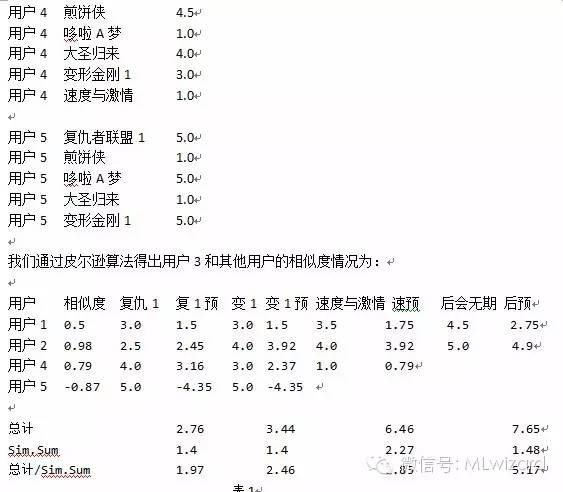
这里来解释一下这张表,我们从表1中看到有很多的“预”这些预有事根据用户相关度,预测被推荐人在看完此片后会打几分。比如复仇1,用户1和被推荐人(用户3)的相关系数为0.5,那么预测用户3在看完复仇1之后可能会给该片打1.5分,以此类推。
总计:为所有预测评分之和
Sim.Sum:为相似度(第一栏)之和,这里相似度只相加对该片打过分的人的相似度,没打分的人的相似度不用相加,比如速度与激情就不用加入用户5的相似度,后会无期不用加入用户4和用户5的相似度。
最终获得的推荐分数为总计除以相似度之和。
最终我们获得的排序列表为后会无期:5.17 > 速度与激情:2.85 > 变形金刚:2.46 > 复仇者:1.97
有人可能会质疑这个用户5的价值不高,甚至产生了副作用,这个是可以再具体应用场景中把这个用户5个剔除的。可以根据自己的需要把相关度低于某个值的信息屏蔽掉。这里后会无期出现了大于5的值,在推荐中其实这个是不影响的,当然,用户可以根据自己的需求设置阀值,把大于5的值全等于5,小于1的值全归1,这个可以自由发挥。
以上都是基于USER_BASE的推荐实现方式。ITEM_BASE在算法上和USER_BASE是一样的,基于以上的例子,无非是把用户的位子和影片的位子互换。
例:在USER_BASE下的数据如果为