拓扑机器学习的神圣三件套:Gudhi,Scikit-Learn和Tensorflow(附链接&代码)

作者:Mathieu Carrière
翻译:孙韬淳
校对:和中华
TDA:
https://en.wikipedia.org/wiki/Topological_data_analysis
IBM:
https://researcher.watson.ibm.com/researcher/view_group.php?id=6585
Fujitsu:
https://www.fujitsu.com/global/about/resources/news/press-releases/2016/0216-01.html
Ayasdi:
https://www.ayasdi.com/platform/technology/
生物学:
https://www.ncbi.nlm.nih.gov/pubmed/28459448
时间序列:
https://www.ams.org/journals/notices/201905/rnoti-p686.pdf
金融:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2931836
科学可视化:
https://topology-tool-kit.github.io/
计算机图形学:
http://www.lix.polytechnique.fr/~maks/papers/top_opt_SGP18.pdf
TDA的参考示例:点云分类
这个数据集在一篇开创性的TDA文章上介绍过。它由通过下述动力系统生成的轨迹来得到的点云集组成:
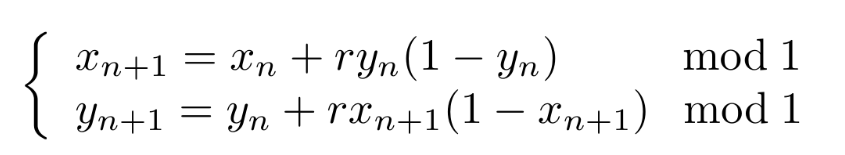

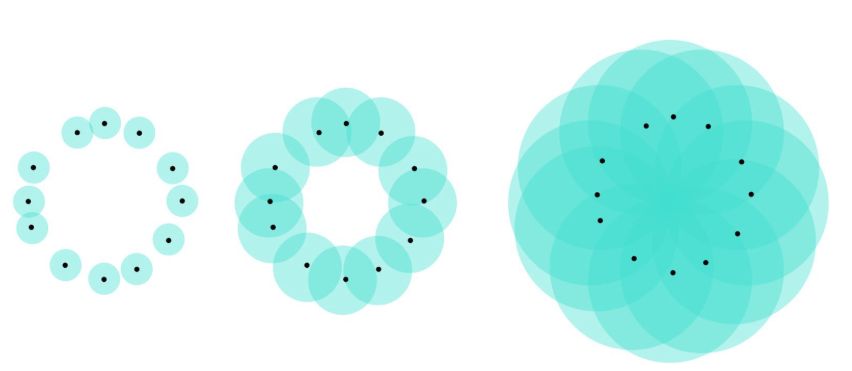
球并集的例子。对于中间图的并集,它清晰的组成了一个洞。整张图片被我“不要脸”地借用自我之前的一个帖子
import gudhirips = gudhi.RipsComplex(points=X).create_simplex_tree()dgm = rips.persistence()
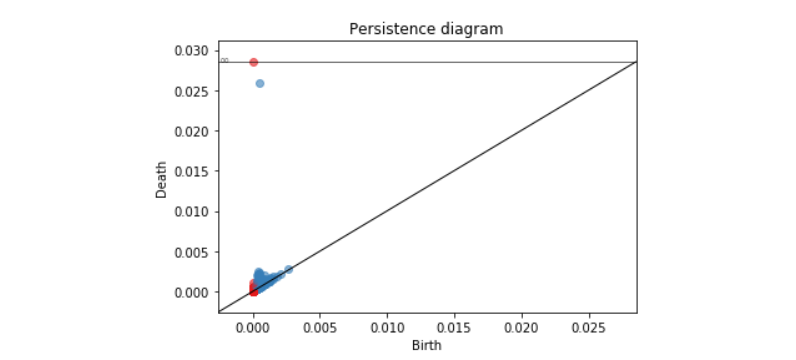
这个漂亮的持续图由r=4.1对应的点云计算出。红色的点代表相连的成分,蓝色的点代表洞
接下来我们将解决的任务则是给定点云预测r的值。
表达
https://gudhi.inria.fr/python/latest/representations.html
import gudhi.representations as tdafrom sklearn.pipeline import Pipelinefrom sklearn.svm import SVCfrom sklearn.ensemble import RandomForestClassifier as RFfrom sklearn.neighbors import KNeighborsClassifier as kNNfrom sklearn.model_selection import GridSearchCV
pipe = Pipeline([("TDA", tda.PersistenceImage()), ("Estimator", SVC())])param = [{"TDA": [tda.SlicedWassersteinKernel()], "TDA__bandwidth": [0.1, 1.0], "TDA__num_directions": [20], "Estimator": [SVC(kernel="precomputed")]}, {"TDA": [tda.PersistenceWeightedGaussianKernel()], "TDA__bandwidth": [0.1, 0.01], "TDA__weight": [lambda x: np.arctan(x[1]-x[0])], "Estimator": [SVC(kernel="precomputed")]}, {"TDA": [tda.PersistenceImage()], "TDA__resolution": [ [5,5], [6,6] ], "TDA__bandwidth": [0.01, 0.1, 1.0, 10.0], "Estimator": [SVC()]}, {"TDA": [tda.Landscape()], "TDA__resolution": [100], "Estimator": [RF()]}, {"TDA": [tda.BottleneckDistance()], "TDA__epsilon": [0.1], "Estimator: [kNN(metric="precomputed")]} ]model = GridSearchCV(pipe, param, cv=3)model = model.fit(diagrams, labels)
带切片Wasserstein核:
http://proceedings.mlr.press/v70/carriere17a/carriere17a.pdf
持续权重Gaussian核:
http://proceedings.mlr.press/v48/kusano16.html
Persistence Images:
http://jmlr.org/papers/v18/16-337.html
Persistence Landscapes:
http://www.jmlr.org/papers/volume16/bubenik15a/bubenik15a.pdf
Gudhi的Tutorial:
https://github.com/GUDHI/TDA-tutorial/blob/master/Tuto-GUDHI-representations.ipynb
Gudhi(1):
http://gudhi.gforge.inria.fr/python/latest/
Gudhi(2):
https://gudhi.inria.fr/python/latest/
这篇论文:
https://sites.google.com/view/hiraoka-lab-en/research/mathematical-research/continuation-of-point-cloud-data-via-persistence-diagram
https://github.com/GUDHI/TDA-tutorial/blob/master/Tuto-GUDHI-optimization.ipynb
def compute_rips(x): rc = gd.RipsComplex(points=x) st = rc.create_simplex_tree() dgm = st.persistence() pairs = st.persistence_pairs() return [dgm, pairs]
def compute_rips_grad(grad_dgm, pairs, x): grad_x = np.zeros(x.shape, dtype=np.float32) for i in range(len(dgm)): [v0a, v0b] = pairs[i][0] [v1a, v1b] = pairs[i][1] grad_x[v0a,:]+=grad_dgm[i,0]*(x[v0a,:]-x[v0b,:])/val0 grad_x[v0b,:]+=grad_dgm[i,0]*(x[v0b,:]-x[v0a,:])/val0 grad_x[v1a,:]+=grad_dgm[i,1]*(x[v1a,:]-x[v1b,:])/val1 grad_x[v1b,:]+=grad_dgm[i,1]*(x[v1b,:]-x[v1a,:])/val1 return grad_x
import tensorflow as tffrom tensorflow.python.framework import opsdef py_func(func, inp, Tout, stateful=True, name=None, grad=None): rnd_name = "PyFuncGrad" + str(np.random.randint(0, 1e+8)) tf.RegisterGradient(rnd_name)(grad) g = tf.get_default_graph() with g.gradient_override_map({"PyFunc": rnd_name}): return tf.py_func(func, inp, Tout, stateful=stateful, name=name)def Rips(card, hom_dim, x, Dx, max_length, name=None): with ops.op_scope([x], name, "Rips")as name: return py_func(compute_rips, [x], [tf.float32], name=name, grad=_RipsGrad)def _RipsGrad(op, grad_dgm): pairs = op.outputs[1] x = op.inputs[0] grad_x = tf.py_func(compute_rips_grad, [grad_dgm,pairs,x], [tf.float32])[0] return [None, None, grad_x, None,None]
tf.reset_default_graph()x = tf.get_variable("X", shape=[n_pts,2], initializer=tf.random_uniform_initializer(0.,1.), trainable=True)dgm, pairs = Rips(x)loss = -tf.reduce_sum(tf.square(dgm[:,1]-dgm[:,0]))opt = tf.train.GradientDescentOptimizer(learning_rate=0.1)train = opt.minimize(loss)
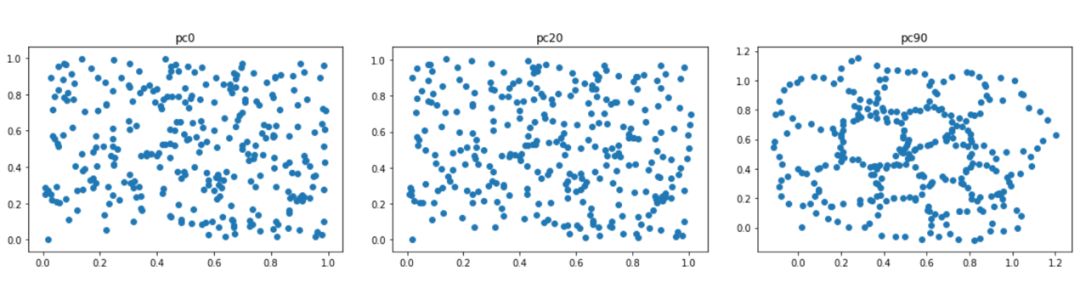
https://github.com/GUDHI/TDA-tutorial/blob/master/Tuto-GUDHI-optimization.ipynb
——END——



