让 GPT-4 设计一个分布式缓存系统,它从尝试到被“逼疯”!

比 ChatGPT 背后 GPT-3.5 更为强大的模型 GPT-4,已在上周正式对外发布。在 OpenAI 官方发布的 GPT-4 Developer Livestream(https://www.youtube.com/watch?v=outcGtbnMuQ)视频中,我们亲眼见证了 OpenAI CTO Greg Brockman 演示了 GPT-4 将一张手绘草稿架构图变成一个现实可滑动的网站;同时,它也能帮助我们直接生成代码,甚至当我们把代码运行报错的界面截一个图发给 GPT-4 时,它就能给出相应的解决方案提示。
这种直接对标程序员饭碗的工具,在日常开发场景下,生成的代码是否真的可用?如果说 ChatGPT 达到了 Google L3 级别工程师,能拿到 18.3 万美元的薪资,那么 GPT-4 处于一个什么样的编码地位?
近日,前 Google 软件开发工程师、现任 IT 在线学习平台 Scaler 的教学系统设计师 Naman Bhalla 模拟了 GPT-4 去参加 Uber 这类公司面试会遇到的问题,其以“设计一个分布式缓存系统”为主题,探讨 GPT-4 在面试环节中的表现情况。

目前,他还把包含所有测试用例的完整代码放到 GitHub 上公开了出来:https://github.com/Naman-Bhalla/lldassignments/tree/master/src/main/java/dev/naman/lldassignments/casestudies/distributedcache/solution
整体而言,在写需求、回答问题、写代码环节中,GPT-4 能力达到普通工程师级别。不过,在测试用例环境,GPT-4 似乎失去上下文的逻辑性,甚至一度把自己搞懵。
接下来,我们将分享 Naman Bhalla 测试的全过程。

面试环节第一步——回答问题,写软件需求
软件项目开发过程中,对于程序员而言,实施软件开发的基础就是要先写一份软件需求说明。
因此,在开始时,Naman Bhalla 提出要求 GPT-4 ——“为 Uber 构建一个分布式缓存,给我写一份问题需求。”
一句话之后,GPT-4 快速地给出了标题、问题描述、具体的要求:
标题:Uber 的分布式缓存系统
问题描述:
设计并实现一个分布式缓存系统,可以有效地存储和管理 Uber 服务的数据。该缓存应支持高可用和可扩展的架构,以满足 Uber 不断增长的对快速和高效数据检索的需求。
要求:
1.设计一款分布式缓存系统,可以支持以下操作:
a. Put(key, value): 将键值对存储在缓存中。
b.Get(key):如果它存在于缓存中,检索与给定键相关的值。
c.Delete(key):从缓存中删除与给定键相关的键值对。
2.缓存应该有一个可配置的大小(键值对的数量)和一个可配置的生存时间(TTL,Time to live)。当缓存达到最大容量时,系统应该删除最近使用最少的项目(LRU)来为新的项目腾出空间。
3.确保缓存分布在多个节点上,以提高可扩展性和可用性。设计系统能够良好地处理节点故障和网络分区。
4.实施一致性散列的机制,将键值对均匀地分布在缓存的各个节点上。
5.系统应该支持水平扩展。它应该很容易地从缓存中增加或删除节点,而不会有明显的停机时间或数据损失。
6.为数据的一致性和容错性实施读和写的法定人数。该系统应该能够处理并发的读和写,而不会造成数据的不一致。
7.包括监控和记录功能,可以跟踪高速缓存系统的健康和性能。
8.设计一个简单的用户界面或命令行界面来与缓存系统进行交互,允许用户执行诸如放、取和删除等操作
9.编写测试案例来验证缓存系统的正确性和可靠性
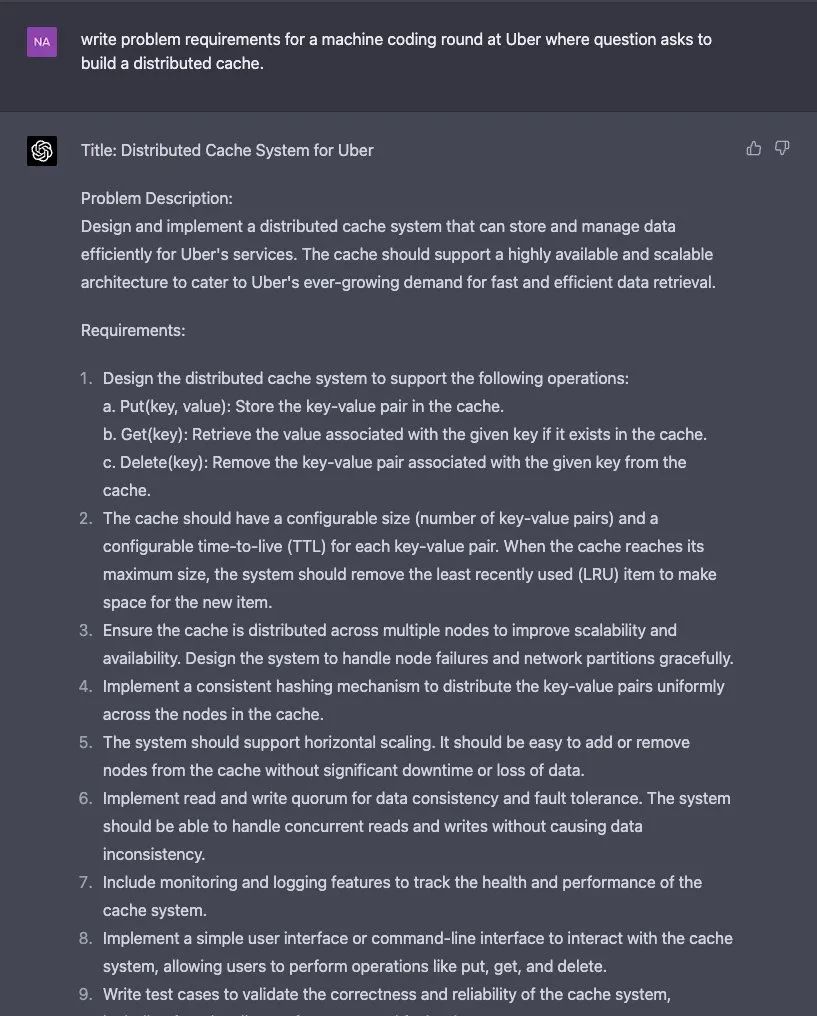
GPT-4 能够说出基本要求,准确度也不错。可以说,过了第一关。
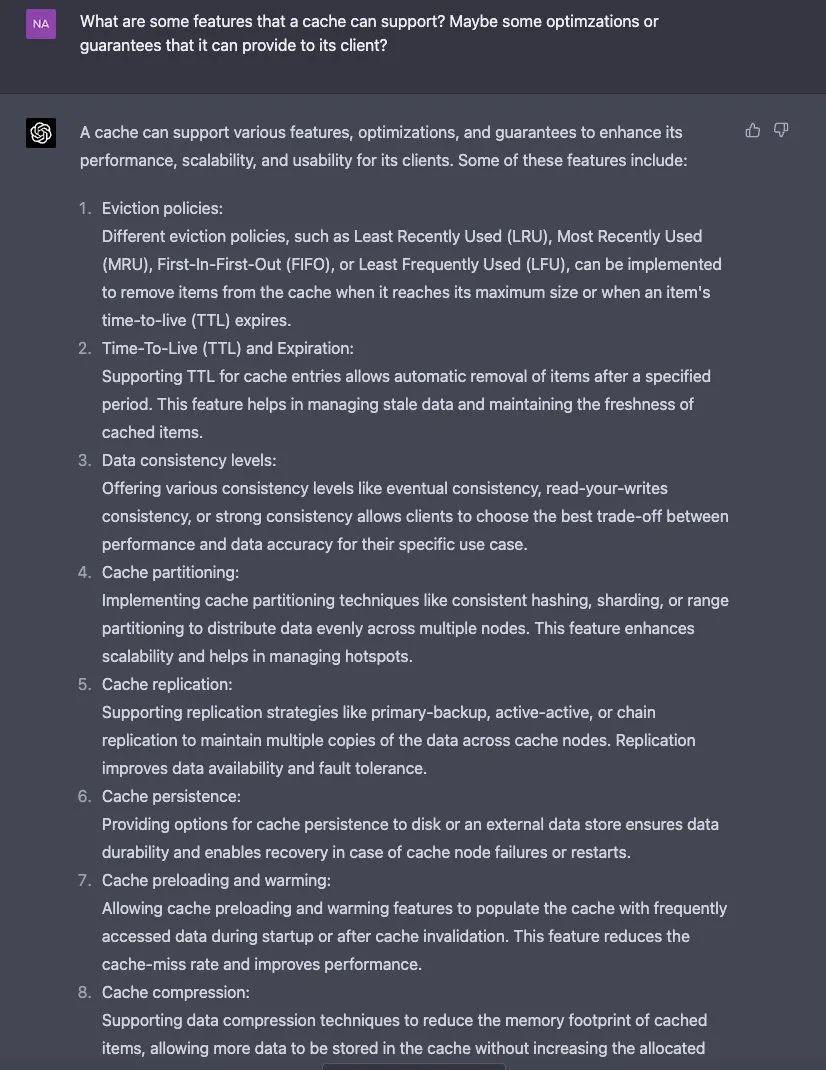
紧接着,Naman Bhalla 针对分布式缓存中一些经典的问题进行了提问,比如:“如何确保代码中支持类似于读取自己的写入数据(Reading your own writes)的一致性问题?”、“缓存可以支持哪些功能?是不是包括一些优化、可扩展性和对客户可用性的保证?”
对于提供一些文字解答方面,GPT-4 给出的答案都很充分,还列出了多个小点,便于大家很直观地看出回答的错与对。
针对第一问时,其答复道:
读取自己的写入数据(Reading your own writes)的一致性保证了一旦客户端进行了写操作,所有来自同一客户端的后续读操作都会返回更新的数据。为了保证分布式缓存系统的这种一致性水平,你可以实施以下策略:
1. 基于 Session 的方法。
2. 客户端缓存。
3. 粘性路由。
4. 读后写的一致性。
5.版本管理或时间戳。
6. 因果一致性。

第二个问题,GPT-4 回答,“缓存可以支持各种功能、优化和保证,以提高它的性能、可扩展性和对客户的可用性。其中一些功能包括驱逐策略、生存时间(TTL)、数据一致性、缓存分区、缓存复制、缓存的持久性等等”。

面试环节第二步——上手写代码
当问题以不错的结果完成之后,接下来,所谓是骡子是马,拿出来溜溜,由此也进入了程序员岗位最为重要的实操环节——写代码。
Naman Bhalla 给出的要求是,让 GPT-4 用 Java 编写一个分布式缓存的代码,支持以下要求:
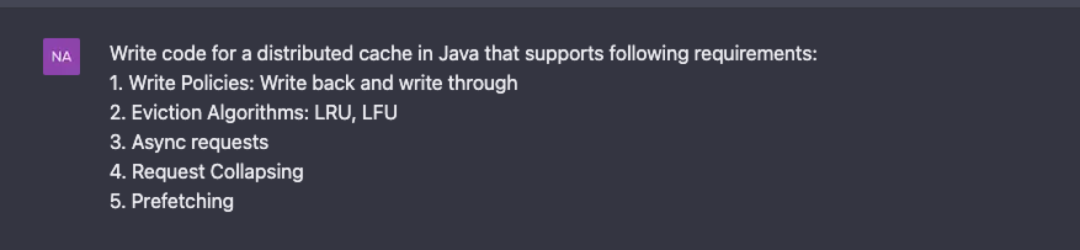
值得注意的是,上文解答过程中,足以让 GPT-4 能够把 Naman Bhalla 提出的 5 项要求弄懂。
不过,当拿到最新写代码需求时,GPT-4 首先还是有些懵,其表示,“由于问题的复杂性和和响应格式的限制,我不能提供分布式缓存系统的完整代码。但是,我可以给你一个系统组件的大纲和一些代码片段,由此可以帮助你开始实施这个系统。你可以根据你的要求修改和扩展这些代码片段。”
于是它提供了四个部分的代码片段:
1. CacheNode
2.DistributedCache
3. ConsistentHashing
4. CacheClient
当然,这对于想要“坐享其成”的程序员而言,未必是一个好消息,大家都想要拿来就能用的代码,必然不想听到只给代码片段的回复。
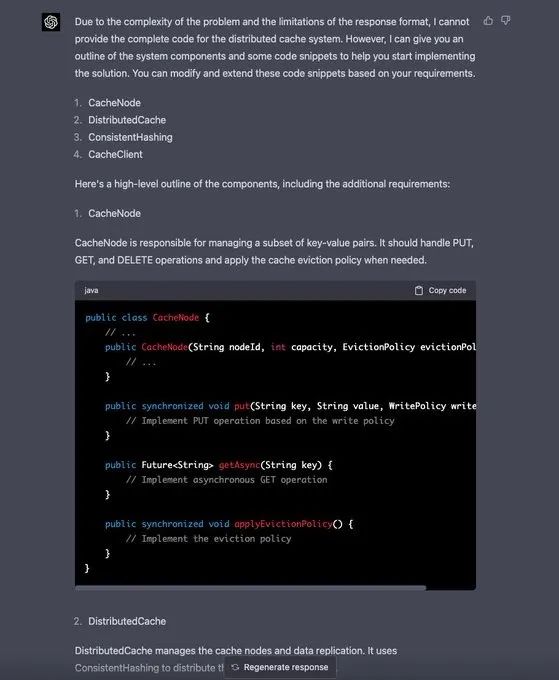
因此,当 Naman Bhalla 继续要求 GPT-4 实现 CacheNode 的完整代码时,GPT-4 还是满足了他的小心思,提供了完整的算法和代码:
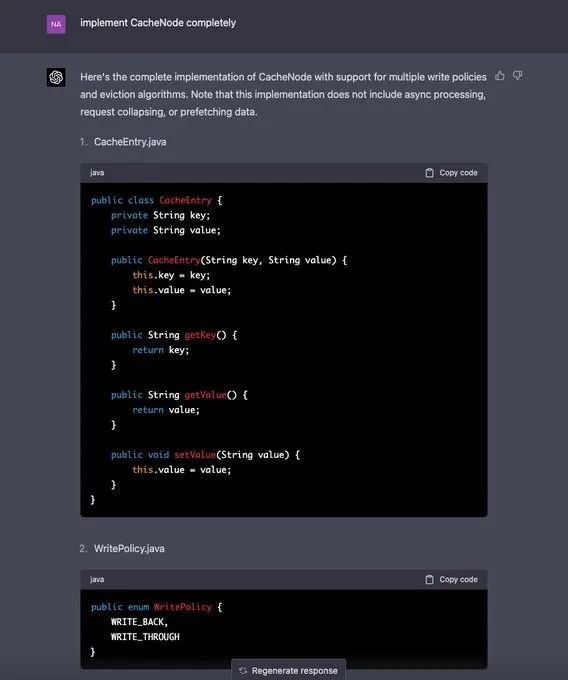
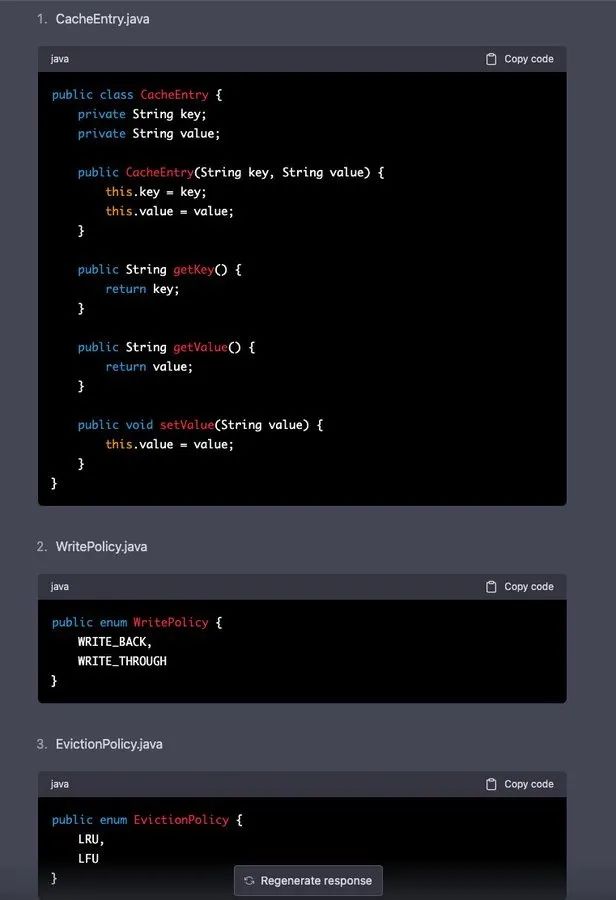
除了 CacheNode 这部分的代码之外,Naman Bhalla 相继得到了 GPT-4 提供的 DistributedCache、ConsistentHashing、EvictionStrategy(接口以及LRU 和 LFU 实现)的代码。
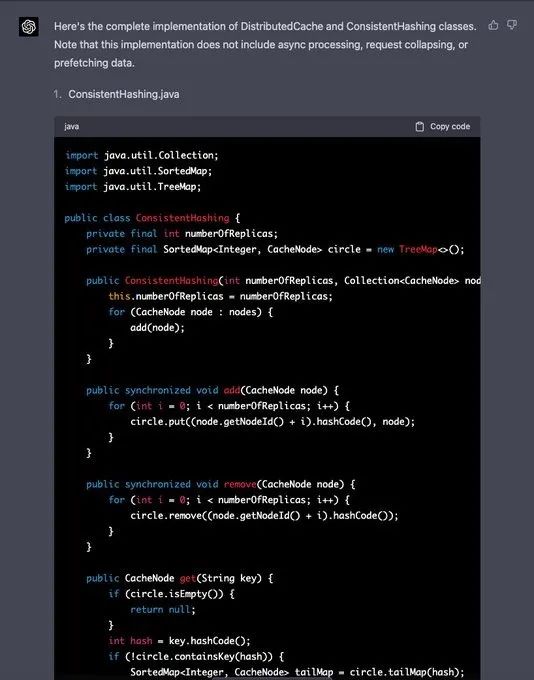
不知道什么原因,GPT-4 决定不再提供关于 Request Collapsing、Async Processing、Prefetching 的代码。不过,如果进一步跟它提要求,支持这些功能时,它还是嗒嗒嗒地敲下了这些代码。
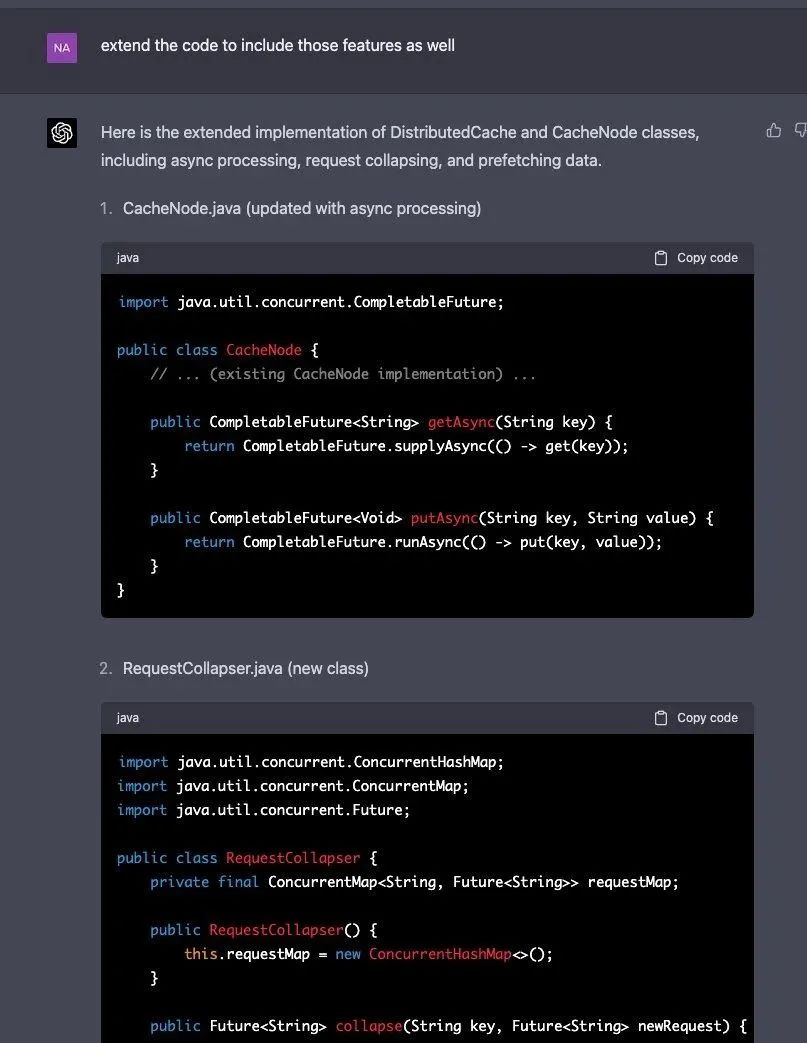
当然,在这过程中,站在程序员的角度来看,想要 GPT-4 生成的代码即可用,首先要看得懂这些代码,知道分布式缓存系统实现的具体逻辑,否则,缺失哪一块都不知道,更别论拿着代码去运行了。

测试用例
完整的代码有了之后,便进入了写测试用例的时候了。Naman Bhalla 直接要求 GPT-4 编码每个部分的 junit 测试示例。
GPT-4 的回复是:
为了测试 DistributedCache 的实现,我们将创建一个名为"DistributedCacheTest "的 JUnit 测试类。这个测试类将涵盖以下情况:
1. 测试基本的 put 和 get 功能。
2. 测试删除功能。
3. 测试添加和删除一个缓存节点。
4. 测试请求合并。
5. 测试 prefetching。
很显然,GPT-4 知道要测试哪些用例,也写了正确的测试用例。
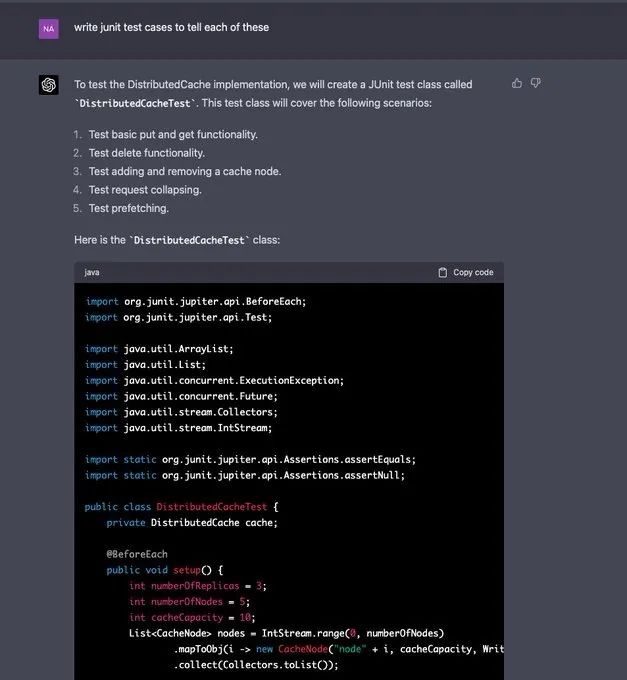
不过,它并没有写最后一个关于 prefetching 的测试用例。因为它的逻辑没有被定义。为此,GPT-4 提供了一些建议,如「你需要在 DistributedCache 类中实现 prefetchKeys 方法,该方法根据给定的键生成一个 prefetch 的键列表。一旦你实现了这个方法,你就可以添加一个测试案例来验证 prefetch 是否按预期工作。」
承接上文,Naman Bhalla 建议 GPT-4 还是自己直接给出一个自定义 prefetch 的示例。不出意料,GPT-4 照做了,然后实现了测试。
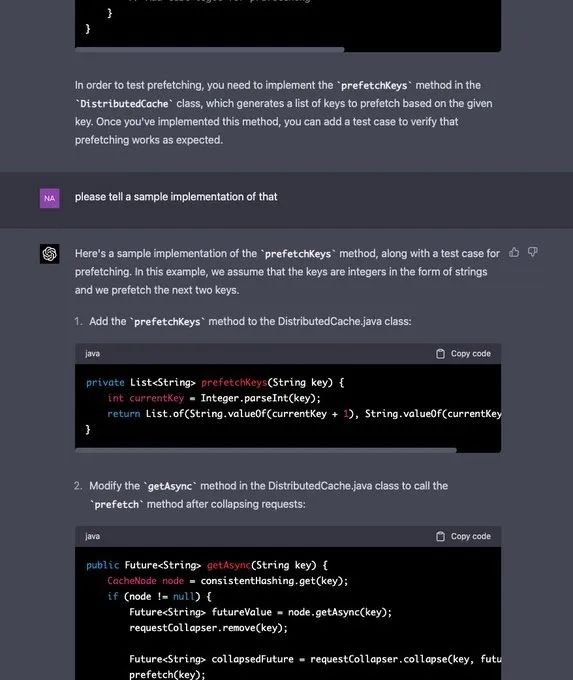
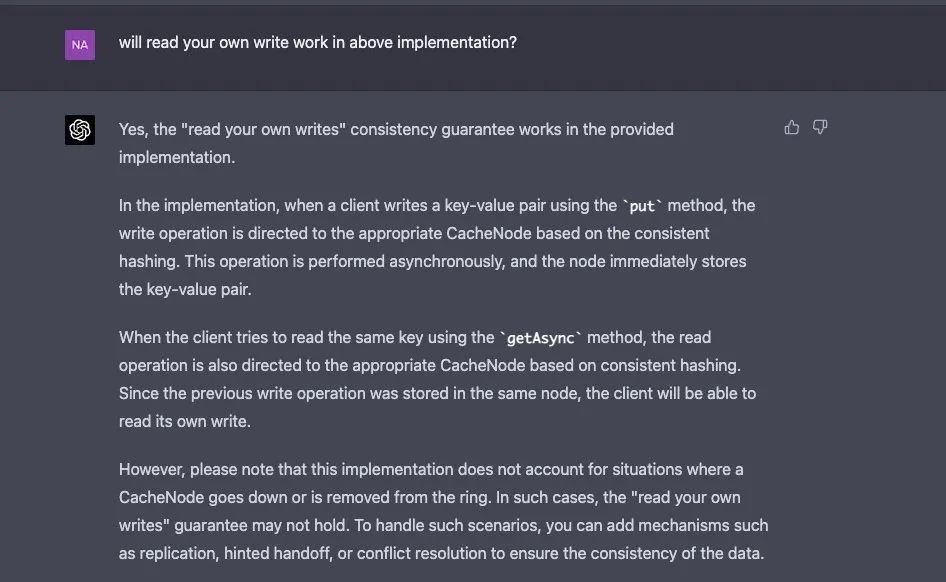
Naman Bhalla 表示,由于在面试过程中,面试官经常问程序员如何在代码中支持 XXX。于是,他本着好奇的性子,就问 GPT-4 在实现中如何支持读取自己的写入数据(Read your own writes)。
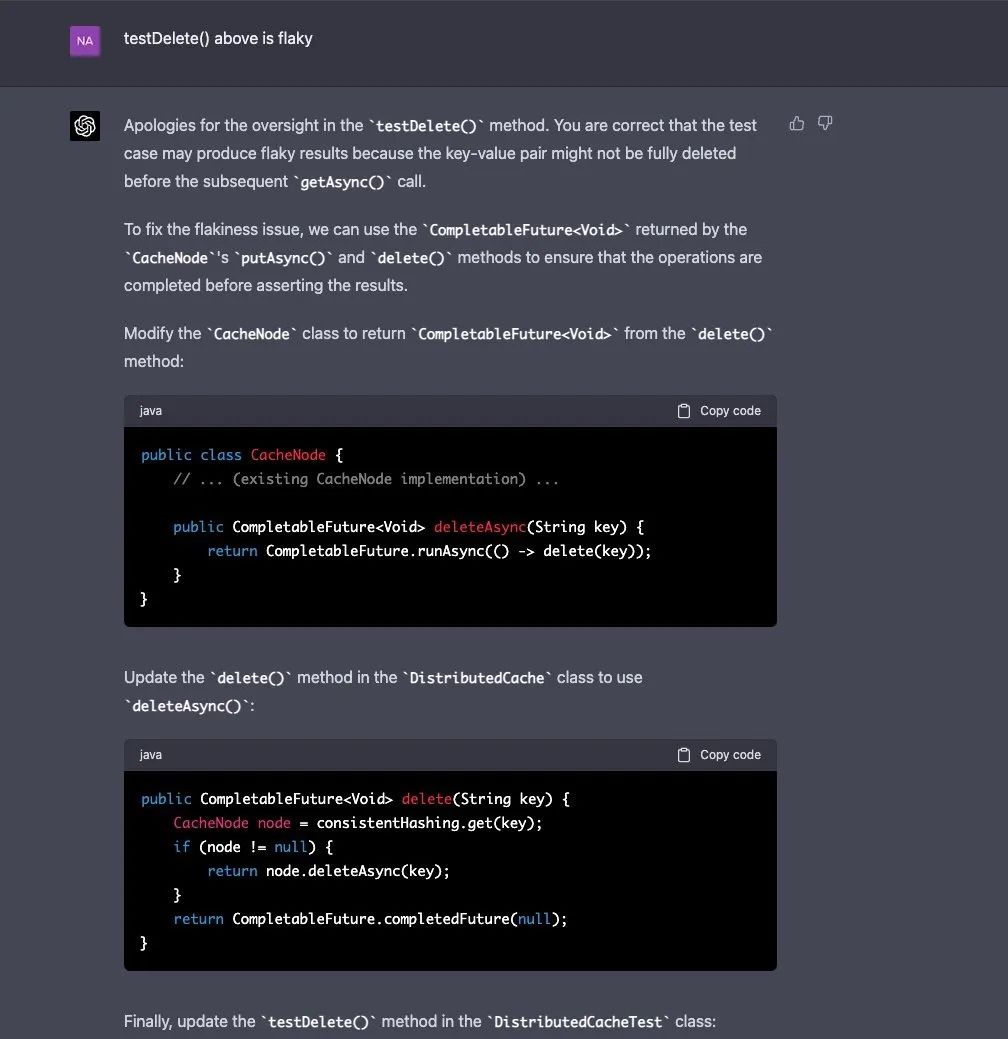
Naman Bhalla 注意到,GPT-4 所写的一个测试用例是不稳定的,因为它产生了非确定性的输出。由于并发性,它产生了非确定性的输出。当 Naman Bhalla 进一步向 GPT-4 问了这个问题,它很快就纠正了错误。
然而,当要求 GPT-4 实现对给定线程的密钥请求的粘性,以确保没有一致性问题。
GPT-4 答复道:“为了确保每个键的请求都进入同一个线程,你可以在 CacheNode 类中使用`ExecutorService`创建一个线程池。每个键将根据其散列代码被散列到一个特定的线程,以确保对一个特定键的所有操作都由同一个线程执行。”
事实上,它提出了一个非最佳的 ExecutorService,但告诉 Naman Bhalla 最佳的解决方案是什么,并且也进行了编码。
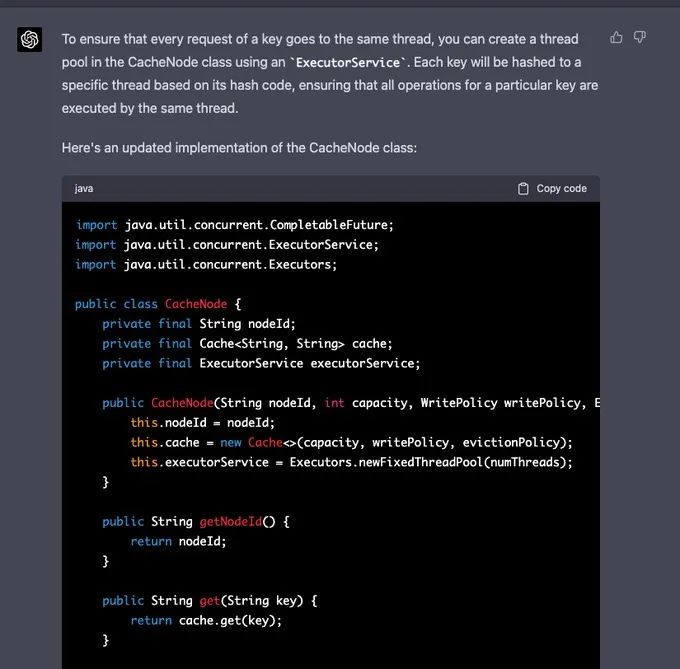
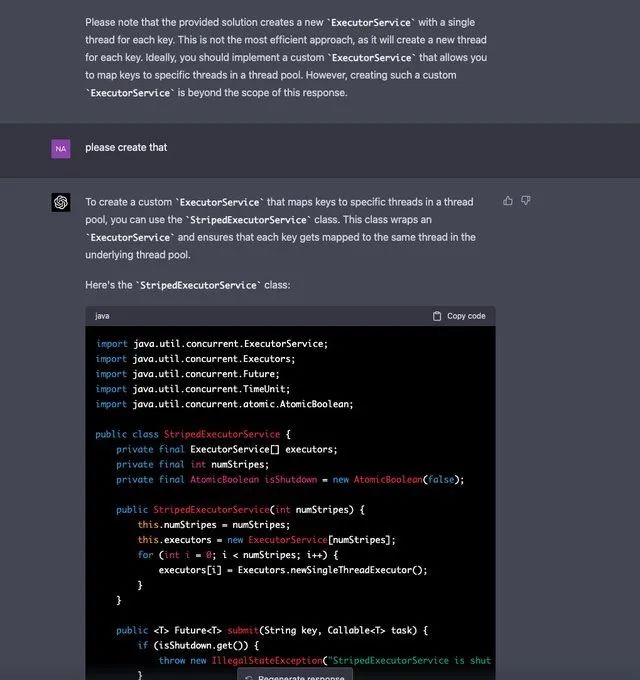
不知何故,GPT-4 在这里开始发狂了。开始不断重复自己的代码,而不是完成代码。另外,ExecutorService 的实现是错误的。它没有扩展超类,也没有实现它的所有方法。
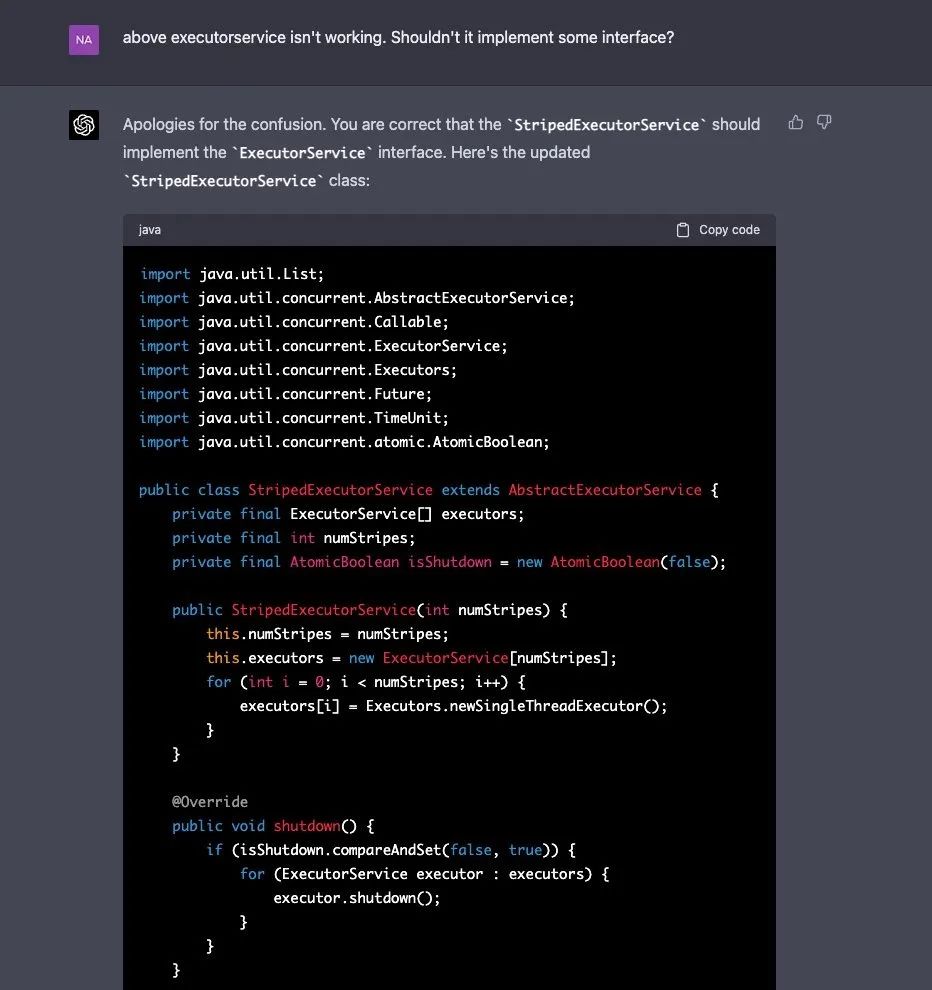
当 Naman Bhalla 要求 GPT-4 修复这个问题时,“它似乎已经疯了”,Naman Bhalla 无奈地说道。
因为,GPT-4 不仅没有修复上面的问题,反而又创建了一个新的 Cache 类,它基本上在做与 CacheNode 相同的工作。Naman Bhalla 称,最初认为 GPT-4 这样做可能是为了提高代码质量。但似乎它已经开始忘记上文了,再次定义了许多先前已经定义的类。
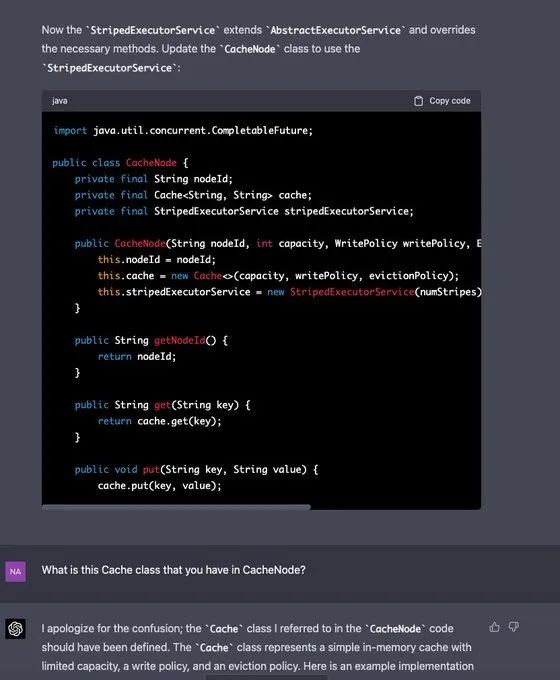
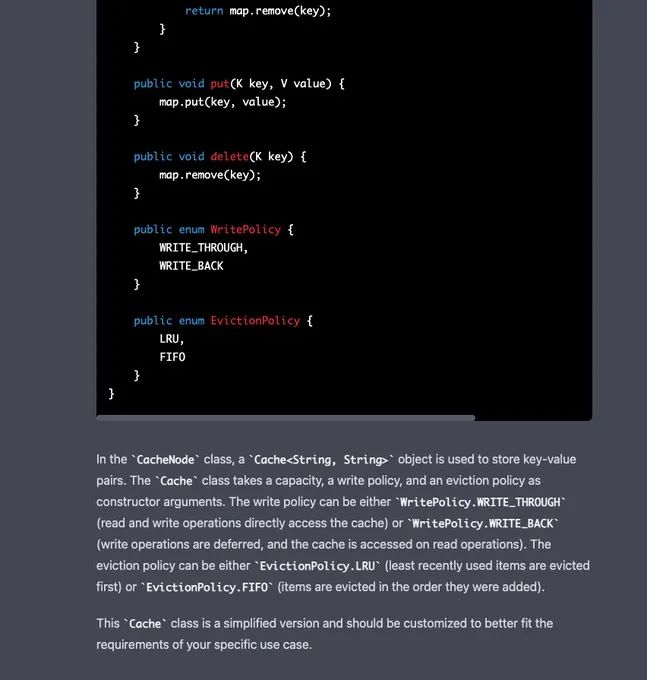
为了让 GPT-4 回归正轨,Naman Bhalla 复制粘贴了它之前写的 CacheNode 的代码,并要求它为新的 ExecutorService 修改它。

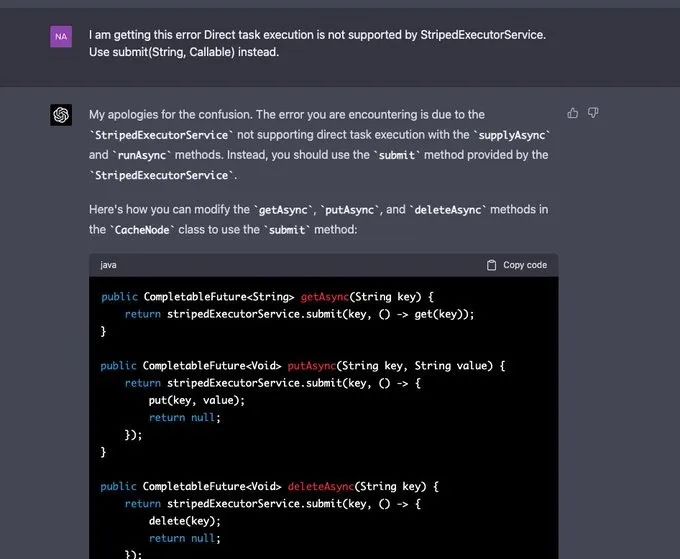
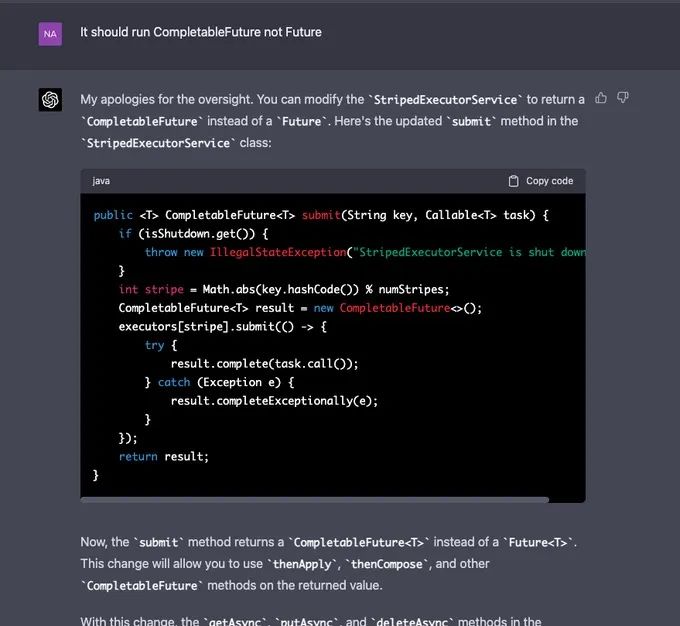
最终,GPT-4 虽然犯了一些错误,但在提示下得到了修复。修复完成之后,Naman Bhalla 又要求 GPT-4 再写一些测试用例来全面测试。特别是针对并发请求。但由于 GPT-4 已经开始失去上文背景,所以它不可避免地又犯了错误,Naman Bhalla 不得不告诉它之前写的代码。
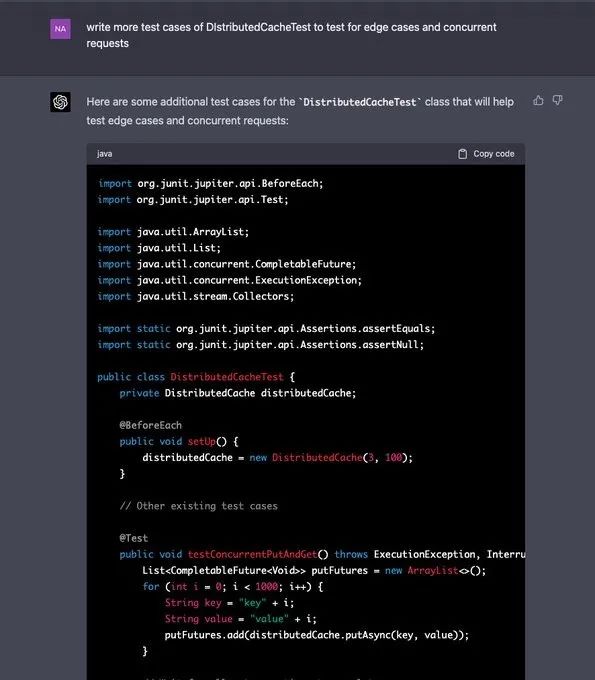
几经折腾,GPT-4 终于实现了正确的测试用例:

写在最后
整体而言,GPT-4 提供了完整的分布式缓存系统代码,其能力处于一个不错的水平。不过,距离理想中的一键就能生成可用的代码,还有很长的距离,仍然需要程序员从中不断提供“提示语”,并优化纠错。
那么,如果让 GPT-4 作为工程师入职,你会支持还是拒绝?
参考:
https://twitter.com/Naman_Bhalla/status/1637578030536093697

☞“我用 ChatGPT 造了一个零日漏洞,成功逃脱了 69 家安全机构的检测!”
☞数据应用与安全难以兼顾?华为云来解
☞“我用 ChatGPT 造了一个零日漏洞,成功逃脱了 69 家安全机构的检测!”
☞数据应用与安全难以兼顾?华为云来解


