一个模型搞定元素周期表常见元素:中国团队打造分子模拟预训练模型,最高节省90%数据
白交 发自 凹非寺
量子位 | 公众号 QbitAI
分子模拟领域的预训练模型,来了!
DPA-1,中国团队深势科技以及北京科学智能研究院等机构打造,能覆盖元素周期表大多数常见元素。

在各类数据集上的迁移学习结果表明,该模型能大幅降低新场景对数据的依赖,甚至在特定条件下能省去90%的数据。
用大模型的思路打开分子模拟
机器学习辅助下的原子间势能面(PES)建模,与相应的机器学习势函数正在彻底改变分子模拟领域。PES是用于描述化学体系的一个基本量,通过它能得到大量原子间相互作用的信息。
过去传统的分子模拟,主要是基于物理经验得到的解析函数来描述PES,但始终无法完整描述出原子间相互作用。
目前,机器学习势函数得益于第一性原理计算产生的数据,极大拓展了模型的应用范围,在材料科学、计算物理等领域应用广泛,并取得了较大成果。
不过仍面临着现有模型迁移能力不足、缺乏通用大模型的局限性。当面对一个复杂体系时,仍需获取大量数据从头开始训练模型,造成计算成本高昂。
基于这样的背景,研究人员参考当下在CV、NLP等领域中大模型的一种“预训练+少量数据微调”解决方案,提出了DPA-1,基于新注意力机制的深度势能预训练模型。
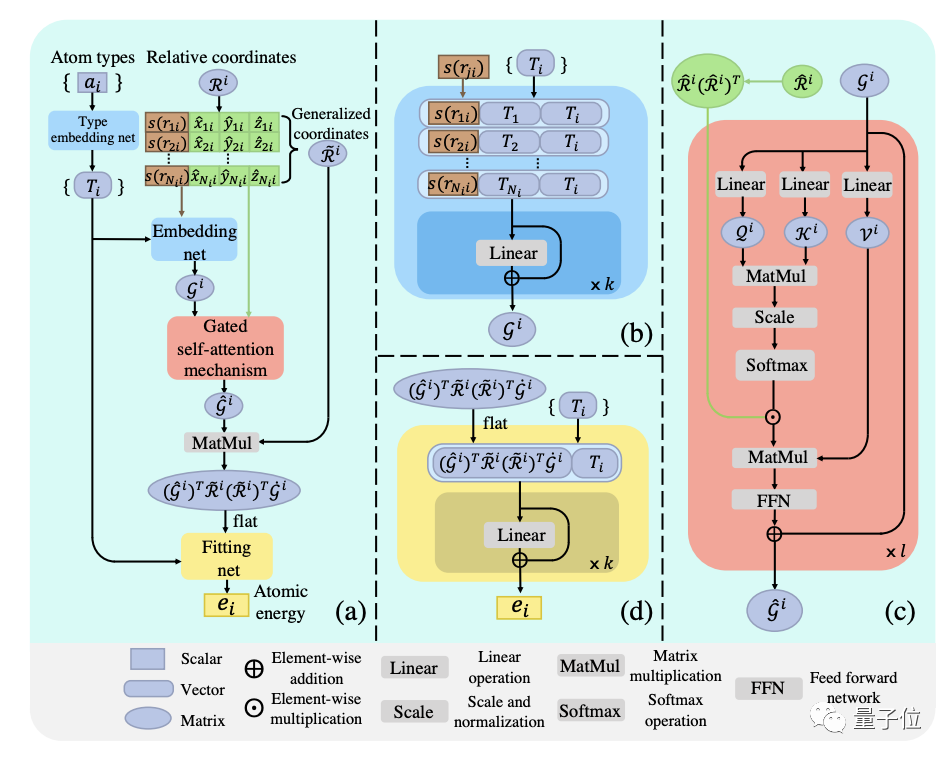
类似于NLP的注意力机制,研究人员提出了门控注意力机制 (即图中的红色模块)。
据介绍,该模型在原子局部环境矩阵上进行了类比多体(大量粒子构成的微观系统)相互作用的信息交互,并以正则化的相对坐标点乘作为角度信息,对获得注意力权重进行重新加权,以此来实现类似门控的机制。
此外,DPA-1还引入了对元素的编码。不同元素共用同一套网络参数,从而提升元素容量。
还将化学元素可视化
在迁移性测试中,研究人员有意将不同训练集划分成多个子集,且每个子集的组分、构型都有较大差异。
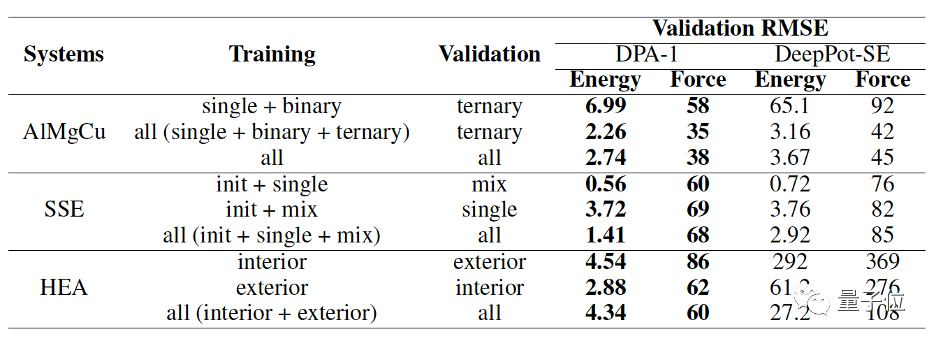
以AlMgCu合金数据集为例,则是分为了single、binary、ternary三个子集。
(single子集仅包含单质/一元数据,binary仅有二元数据,即Al-Mg,Al-Cu,Mg-Cu;而ternary则是剩余的三元数据)
结果显示,相较于DeepPot-SE,DPA-1的测试精度有较大的提升,甚至在特定条件下这种提升达到了一两个数量级。
进一步地,研究人员设计了迁移学习的方案。
简言之,就是先在较大规模数据上进行预训练,然后根据新的少量数据集修改最后一层能量偏差。
在AlMgCu合金数据集测试中,就将一元、二元子集上进行预训练,然后在三元子集上测试。
结果显示,对比DeepPot-SE,DPA-1可节省约90%的三元数据。
在仅有少量三元数据测试下,也能达到较高的精度。
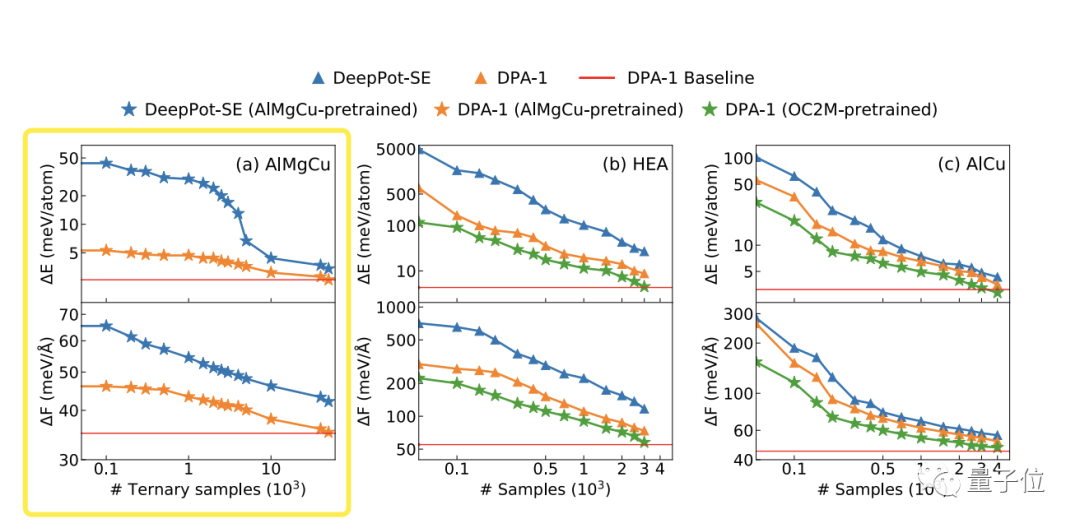
接着他们在包含56种元素的大型数据集OC2M上预训练,并将其迁移到毫不相关的HEA和AlCu数据集上,结果都显示出能成功的应用。
其他类似模型GemNet(分子的通用方向图神经网络)在同样OC2M数据集上预训练,产生的模型有数十亿的参数,训练时间需要数以千计的GPU hours。
而DPA-1只需要不到200个GPU hours 来训练不到一百万个参数,并取得了不错的结果(DPA-1和Gemnet-OC[34]的能量MAE为0.681 vs 0.286 eV)。
除此之外,他们还将元素可视化——模型中学习到元素编码进行了PCA降维并可视化。
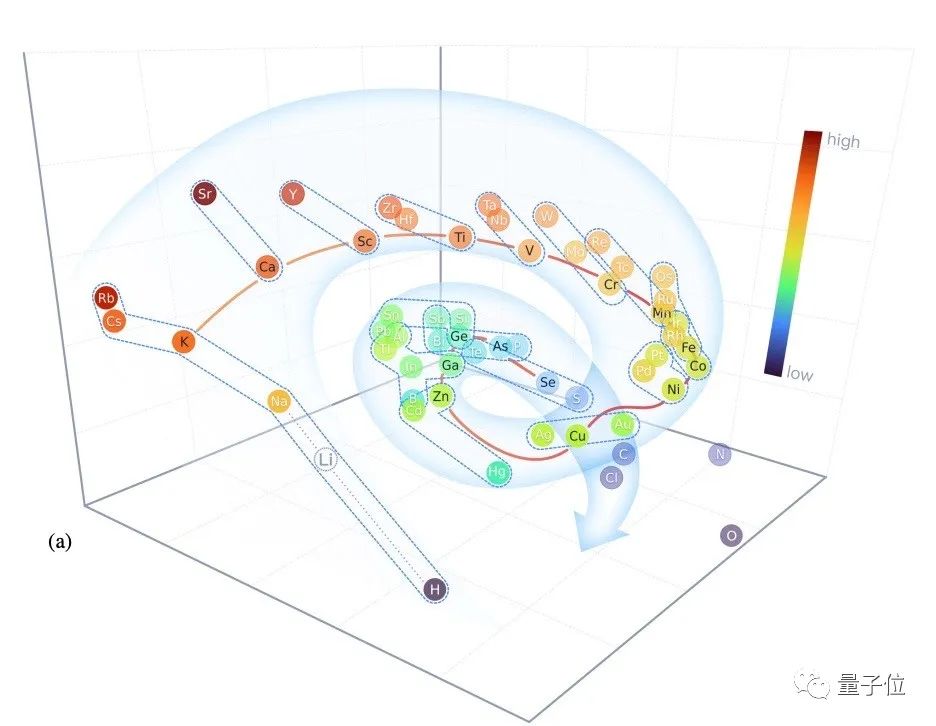
可以看到,所有元素都呈螺旋状分布,同周期元素沿着螺旋下降,同族元素则垂直螺旋方,恰好对应的是元素周期表的位置。
据研究人员介绍,本次研究证明了“预训练+少量任务微调”流程的可行性。
接下来,他们将致力于势函数自动化生产、自动化测试,也将关注像多任务训练、无监督学习、模型压缩、蒸馏等操作,方便用户一键生成下游任务所需的势能函数。
感兴趣的旁友,可戳下方论文链接了解更多~
论文链接:
https://arxiv.org/abs/2208.08236
GitHub链接:
https://github.com/deepmodeling/deepmd-kit
参考链接:
https://mp.weixin.qq.com/s/cbTgntJmuntskQmTWjAINA
— 完 —
「人工智能」、「智能汽车」微信社群邀你加入!
欢迎关注人工智能、智能汽车的小伙伴们加入我们,与AI从业者交流、切磋,不错过最新行业发展&技术进展。
PS. 加好友请务必备注您的姓名-公司-职位哦 ~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



