2019 DataFunTalk 广告技术应用文章合集

DataFunTalk 2019年度 "各厂最新技术应用分享" 文章合集:广告篇。来自各厂12位嘉宾分享的广告技术应用干货电子书合集,限时7天,免费领!
导读:回望2019年,DataFunTalk 为大数据、人工智能的技术小伙伴们出品了61场线下沙龙,16场线上直播,吸引了20000+小伙伴们的参与。取得这样的成绩,最应该感谢的是所有参与分享的企业和老师们,你们的经验帮助了许许多多小伙伴们缩短了把大数据、人工智能技术应用在各自场景的周期,少走了很多弯路。
为了让宝贵的经验传播,为了方便小伙伴们的阅读,小编特别整理了 DataFunTalk 2019年度"各厂最新技术应用分享"文章电子版合集,共6大系列,10余个子话题,将在农历春节前的时间里为粉丝们陆续发放新春福利。
今天将为伙伴们发放第二波福利:广告篇,共12篇精选文章,245页,53000字,12M。
如何领取?
1. 分享本文至朋友圈。
2. 扫码加管理员微信,索要电子书。

(点击下方标题,可跳至对应原文)
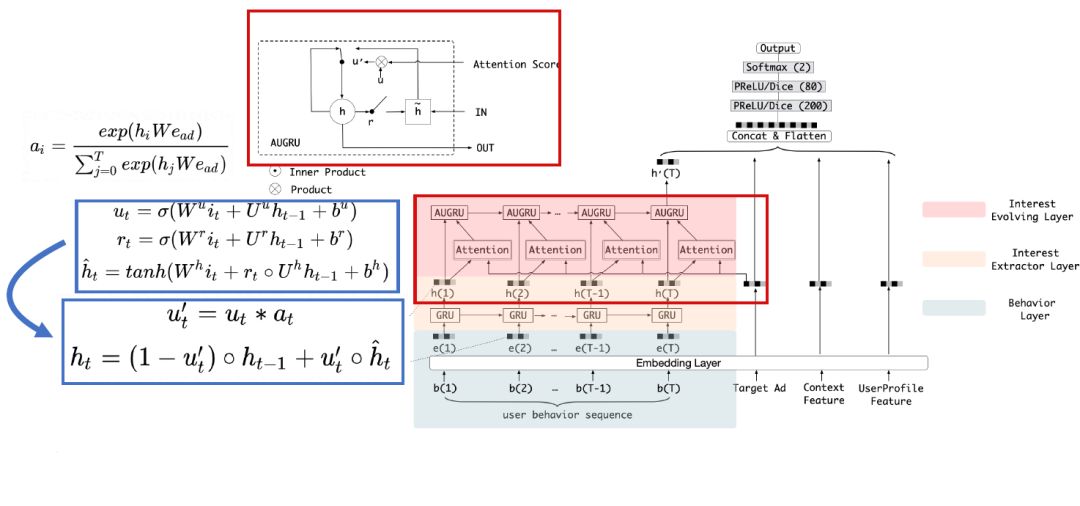
回顾阿里妈妈模型的演化路径,从线性到非线性,再到深度学习的不断演化,模型的结构一直在变化,但是 Representation 的技术上一直没有明显的进展,展望未来的发展方向主要有两点:
1. Representation 的研究,目前一些预训练和类似 NLP 的方案在我们的场景没有良好的效果。推测可能是因为电商数据商品之间并没有如 NLP 一样词与词之间从属,双关,同义等关系,然而商品之间的结构关系已经被天然的账户体系,店铺、类目、品牌等特征很好的表达。但是我们依然会继续推进,后面会尝试 Disentangled Representation,学习电商领域的抽象表达,提取出有效的 Concept,更好的解释我们的 representation 每一维的语义信息是什么;
2. 黑盒的模型让平台离用户/商家的距离越来越远,平台自身也不能完整的理解模型的机理。希望能够构建更白盒的模型,知晓影响用户决策的 Concept,并依此联系用户和商品。产品上我们可以透传出推荐的理由和用户做更多的交互,商业营销上可以结合商家自己的卖点是什么,可以让商家更精准的实现营销诉求。
分享嘉宾:高凯明 奇虎360
早些时候,计算语义相关性的方法,主要是特征工程 + GBDT。特征包括:文本相似度,embedding 相似度,bm25,以及搜索引擎提供的一些特征,等等。特征工程的问题在很难表征语义,所以准确率得不到保证。
随着 DeepLearning 技术的发展,nlp 领域的多个任务,相继提出了深层语义模型。
2013年,web search 任务提出了 DSSM 模型,DSSM 对 query 和 doc 独立进行编码,编码层可以选择 FNN,CNN,或者 RNN,输出层用 cosine 和 sigmoid 来计算相关性。DSSM 的特点是 query 和 doc 独立编码,doc 的编码可以离线计算,线上只做 cosine 和 sigmoid 计算。
2016年,language inference 提出了 ESIM 模型,ESIM 采用了两层 bidirectional LSTM,中间引入了 soft attention。这个模型广泛应用于智能客服系统。如果大家对智能客服了解的话,大概会知道客服系统一般会构建一个问答库,ESIM 用于计算问题和问题的相关性,然后把语义相同的问题归结到同一个答案上。这个就跟我们的广告词召回非常像了,我们的任务是让语义相同的 query 可以召回相同的广告关键词。
2018年,也就去年,我们说,Bert 模型横空出世。Bert 采用了 pre-training 和 fine-tuning 的方式,真正意义上 实现了 NLP 领域的迁移学习。Bert 刷新了11项 NLP 任务的记录,其中就有两项语义相关的任务。
我想大家对 Bert 的评价主要是两种,第一种是,Bert 让我们看到了深层的 Transformer encoder 具有强大的语义表征能力。第二种更实际一点,是 Google 发布的 pretrain 的 model,中文方面就是那个 base 版的 Chinese model。他的意义在于,对于一些小样本的问题,我们用有限的样本,去 fine-tune 这个 model,就可以获得不错的效果。小样本使用大模型,这在之前是做不到的。

分享嘉宾:韦春阳 Hulu
上图总结了在 Hulu 的视频广告系统中的核心算法问题,也是我们研究员每天在做的事情:
① 广告定向,涉及到:
预估模型:例如用户标签的补全,构建 lookalike 模型等等
主题模型:使用无监督方式挖掘用户属性
图像识别技术:识别视频内容中物体、场景、氛围等等,投放上下文相关视频广告
-
时序预测算法: 库存预估一般被建模成时序预测问题
③ 流量匹配,涉及到:
凸优化:使用凸优化进行离线流量匹配
自动化控制理论 ( PID Controller ):使用自动化控制理论进行线上动态调整
④ 转化率优化,涉及到:
CVR 预估模型
Casual Inference ( 因果推断 ):使用因果推断,得到一个更加公正、有效的指标来评估转化是否有效。
Bandit/增强学习:使用 Bandit 以及增强学习的方式来解决广告冷启动的问题
⑤ 程序化交易广告,涉及到:
RTB ( Real time bidding ) 策略研究
流量预估/CVR 预估/投放节奏控制
⑥ 用户/广告体验分析,涉及到:
统计理论
Casual Inference ( 因果推断 )
⑦ 价格机制设计,涉及到:
博弈问题
增强学习
分享嘉宾:李铁牛 新浪微博
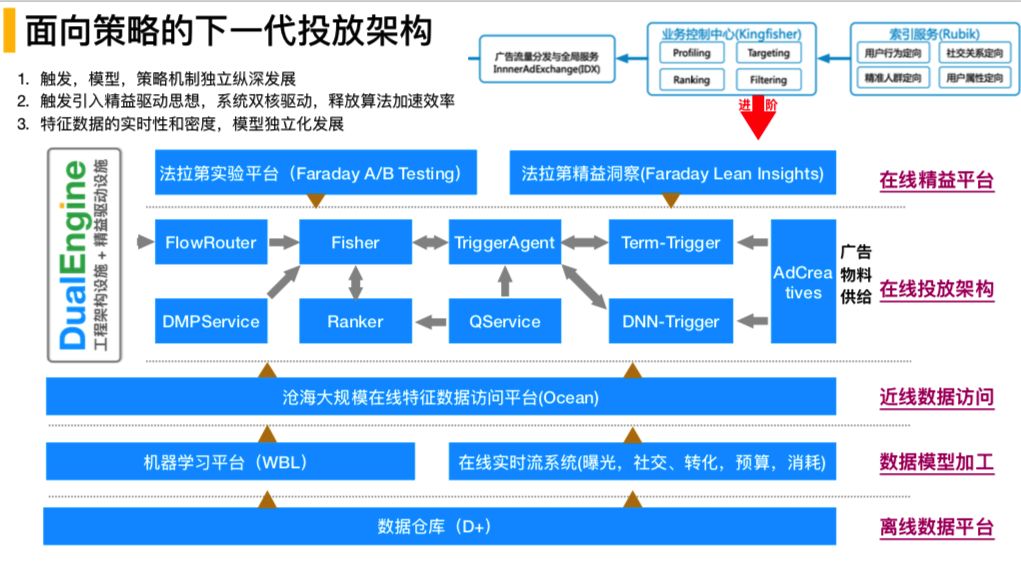
在架构系统4.0中的基础上对在线投放引擎进行业务分级,以满足新的流量漏斗模型。有以下关键点:
① 触发、模型、策略机制向独立纵深发展
系统在支持触发、模型、策略迭代上能够实现很好的各自的独立纵深发展,能够做到各自的快速迭代,互不影响。
② 引入精益驱动思想,系统双核驱动,释放算法迭代效率
在做整体的精细化转型的时候,系统需要不断的进行尝试,而尝试要有一个很好的尝试平台,所以引入了精益驱动的思想。在线精益平台包括:法拉第实验平台和法拉第精益洞察,这是一个比较好的促进业务模型迭代的工具链,更加注重数据的实时性和数据的密度。
系统架构总体上分为:在线精益工具平台、在线投放系统、近线数据访问、数据模型加工(曝光机器学习平台和在线实时流的机制)和离线数据平台
③ 特征数据的实时性和密度,模型独立化发展
重点说下在线投放服务,在服务中,会有流量接入,会有流量的触发,会有触发机制,包括多路触发,通过多路触发体制后,会有机制策略,包括模型预估服务,模型预估服务是聚合服务,会进行粗排、对数据进行裁剪,会在大规模分布式预估服务中完成,Ranker 也会基于预估进行精排。
特别说明一下,为什么进行粗排和精排,粗排我的理解是为了精排的性能考虑的,因为精排会涉及到大规模的精细计算,性能有可能会扛不住,所以需要粗排,而且在保证效果的情况下,为了性能的保证会有多级粗排。
最上面是法拉第实验平台和法拉第精益洞察。整体上会形成双核引擎:一个良好的工程架构体系和精益驱动的工具平台。
分享嘉宾:刘祁跃 爱奇艺
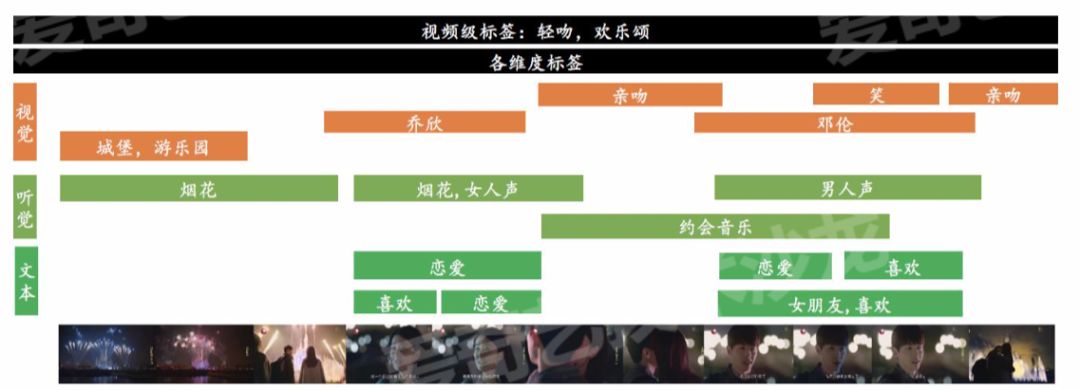
怎么实现对视频更进一步的理解,以下面的例子为主,我们可以从视觉、听觉、文本打各式各样的标签,也可以从部分到整体可以打上各种标签;有了这些底层标签之后,我们需要能达到满足2个需求:
① 怎么去表达抽象的概念,比如浪漫;
② 如何判断哪些是重要的标签,哪些是非重要的标签,以及标签的精度。
当我们生成这些独立的标签之后,我们应该利用标签之间的相关性,提高标签的精度。
当各个识别算法给出这样的结论:
从场景识别,识别出宫廷;从物体检测,识别出手机;从人物装扮中,识别出古装。
很明显物体检测出手机是有问题的,因为这些标签之间会很多的关系,比如同义词,上下级、相关性、互斥等,通过对标签之间的关系的分析,我们可以提高标签识别的精度,对标签排序,找到一些更多高层标签,特别是业务更需要的标签,比如具有商业价值和创作价值的标签。

分享嘉宾:凤凰新媒体广告算法团队
关于 CVR 数据稀疏的问题。新的客户在冷启动阶段的转化不到100个,使用不到100个的转化建立用户的转化率的预估,这个问题是比较困难的。其次,点击转化率与曝光转化率其实不一致,这是一个漏斗序列,先曝光再点击再转化。
如果用点击行为样本训练模型行预估点击转化率,在线上会出现数据不一致的情况,在数据样本比较小的时候,会有很大偏差。曝光转化率解决了样本不一致的问题,但是考虑到数据稀疏,建模后偏差过大,这种方法被弃用。
做过数据分析,发现点击率与转化率存在相关性,可以考虑将 CTR 与 CVR 一起联合训练联合建模,它们肯定有很多特征信息可以共用的。比如通过 weightedLR 做 loss 改造,在推荐等其它项目中有过不错的效果,后续可以一试。
最后,是构建一个模型还是多个模型?是分一个客户建模还是考虑同行业同目标一起建模?关键还是在于业务目标和数据情况:
OCPC 追求单个客户的完成率,要为单个客户做 ROI 达成和算法归因,同时各个客户之间的差异很大,这和全局最优化不一样。从这个角度出发,在考虑很多方法之后,决定为每个客户单独建模。所以会有很多模型,有很多工程上的版本控制,会考虑泛化与工程准确度的需求,我们会为相似的用户做一些先验的平滑,来提升准确度。后续 OCPC 的客户非常多的时候,可以考虑同一个行业,同一转化目标的类型一起建模,数据的稀少情况也能得到一定缓解。
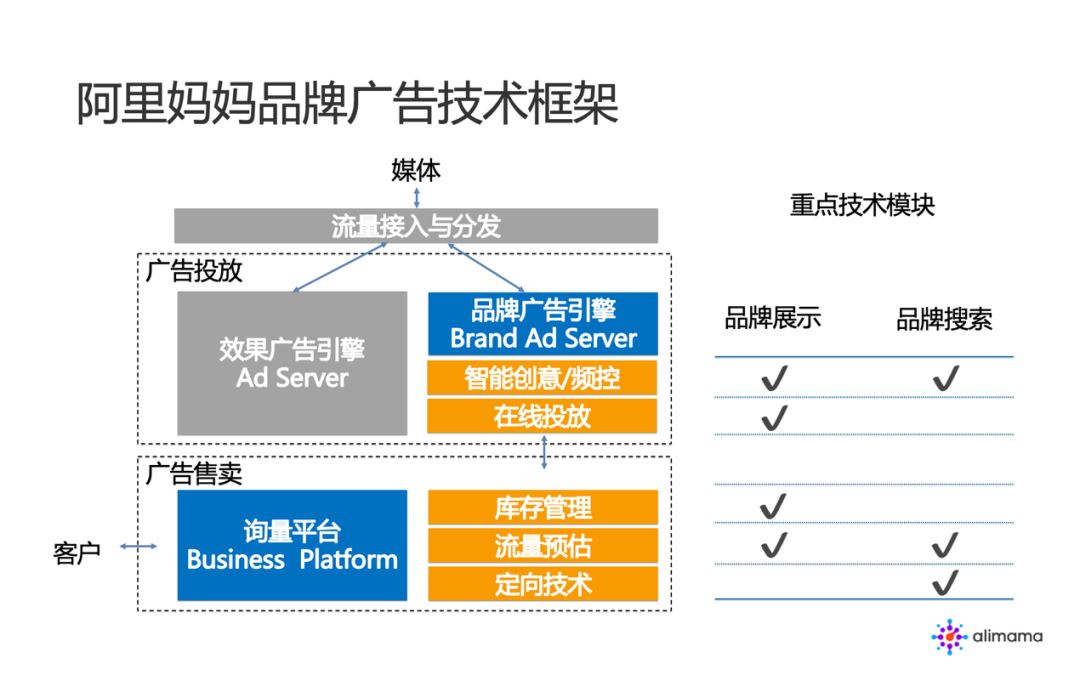
分享嘉宾:肖国锐 阿里妈妈
简要看一下阿里妈妈的品牌广告的技术框架。首先,从广告主侧视角看,广告主(客户)到达时,首先通过询量平台对要采购的流量、人群、时段和地域等各种定向进行询量询价,背后提供支撑的是库存管理、流量预估和定向技术。订单下单后,将构建广告索引,通过广告引擎实现在线投放,这里面涉及到的关键模块是在线投放、智能创意/频控。另外,从流量侧视角看,一个流量到来,会由统一的流量接入与分发层处理,根据流量类型分发到不同的引擎,效果广告或者品牌广告引擎。
这里要说的是,品牌广告内部的展示广告与搜索广告在重点技术模块上存在差异。品牌展示广告在整个链路上的重要模块是库存管理与流量预估,以及在线阶段的流量分配。这些是业内研究十分深入的方向,有很多技术资料,这里不做展开。品牌搜索广告,除了以上常规问题,其特殊问题还包括定向技术、智能创意模块,本文会重点分享。
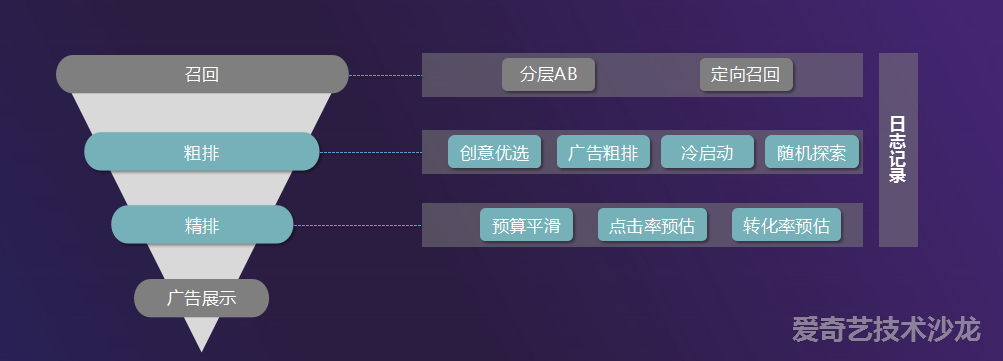
分享嘉宾:王晖 爱奇艺
个性化广告推荐流程:
召回:对候选广告进行召回,比如人群定向等。
粗排:使用轻量级但保证精度的模型对广告做初选,避免精排阶段服务压力过大。粗排阶段还有冷启动和随机探索等功能模块,主要用于解决 E&E 问题,避免马太效应 ( 投放好广告越来越好,差的越来越差 )
精排:使用高精度模型对点击率、转化率和智能出价进行预估。另外精排阶段还支持预算平滑功能。还有预算平摊到全时段等。
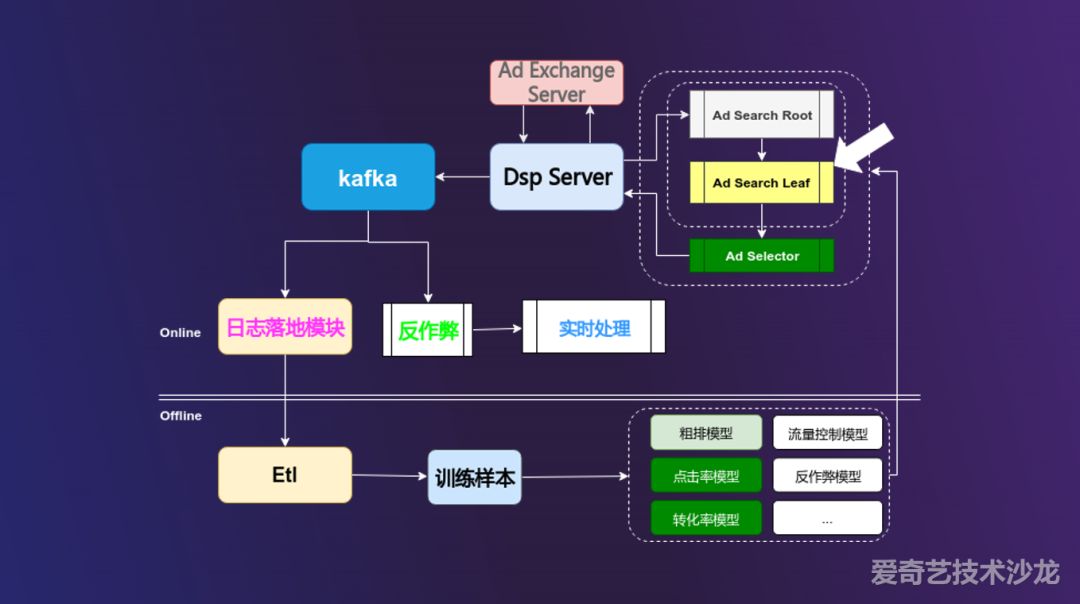
分享嘉宾:王华呈 奇虎360
360展示广告整体架构流程:
流量从 ADX 发送给 DSP 端,DSP 拿到流量之后交给检索召回模块,我们叫 Ad Search 模块,Ad Search 模块分为两个部分,一个是 Ad Search Root 模块,对流量进行识别,判断其为哪种类型的流量,比如 keyword 流量、信息流流量、banner 流量,然后交给不同级别的 Ad Search Leaf 模块对广告进行召回,选出相匹配的广告初步候选集,该模块就是我们今天的主题。然后将选出的广告初步候选集交给 Ad Selector 模块进行精排,即对广告的 CTR 或者 CVR 预估,进行打分,选出 top K 个广告返回给 DSP Server。同时 DSP Server 会将点击、曝光、后续的日志写入 kafka,并进行日志落地,日志落地后会进入后续的 ETL 离线流程,用于后续粗排、点击率等模型生成训练样本使用,另一部实时数据日志数据流会经过反作弊模块后过一遍 ctr 预估的 online learning 和实时曝光反馈的 online feedback。
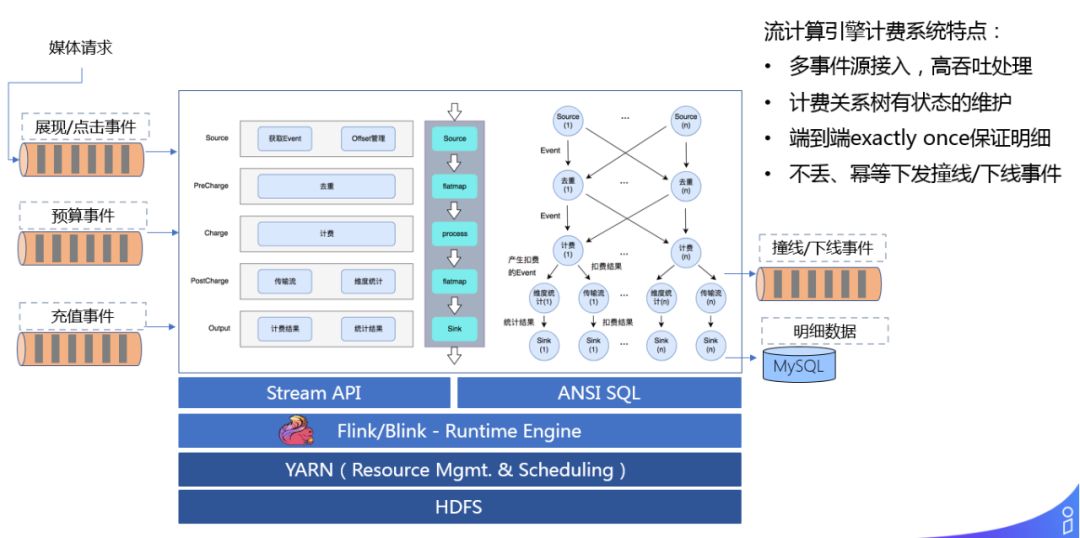
分享嘉宾:辰序 阿里巴巴
我们过去的计费系统是基于单机或者分布式的系统来开发的,现在的计费系统跑在 Flink上,我们接收媒体的请求,展现/点击事件、预算事件、充值事件这三类事件之后,基于 YARN、Flink 之上,通过 Stream API 来做相应的逻辑。每个计费事件来之后,会先做去重,然后再做计费,把明细数据存在数据库中,撞线/下线数据可以实时的通过队列传输给检索系统。采用流式计算引擎做计费的好处在于:
可以做到实时处理,敏感信息高优低延迟的幂等下发;
对于明细数据可以通过两阶段提交 sink 的方式,保证端到端 exactly once 语义,然后做聚批高吞吐的写入数据库;
有状态的存储账户状态,在面对 failover,修历史数据场景下可以做自动和灵活的处理。
总结下流计算引擎计费系统特点:
多事件源接入,高吞吐处理
计费关系树有状态的维护
端到端 exactly once 保证明细
不丢、幂等下发撞线/下线事件
分享嘉宾:鸿雁 阿里文娱
完善的数据分析系统对DSP的投放非常重要,通过数据分析,优化转化漏斗,降低成本。
转化漏斗:
首先需要定义业务的转化漏斗,见下图:

下面逐步说下这几个漏斗阶段我们可以干预的策略。
-
参与竞价 参与竞价的量,主要受限于用户的识别能力,如果根据设备信息可以准确识别到是优酷的用户,那么参与竞价的量可以大大提升。 -
竞价成功 竞价成功的量,主要有这几个方面的受限,第一个是出价,出价过低导致竞价失败率高,第二个是接口性能,目前 ADX 要求是 100ms 内返回,这就要求 dsp 需要不断的优化接口的响应时间,可以很明显的提升竞价成功的量。 -
展现 展现的量,比如标题长度,曝光的次数等等。 另一个是媒体自身的原因了,可能媒体本身有些复杂的频控逻辑导致展现不成功。 -
点击 这个第一是和算法的推荐能力的准确性有关系,推荐的越准确越容易点击,另一个是和图片和标题的吸引程度以及视觉体验有关系,比如一个猎奇的短视频,可以大大激发用户的点击欲望,还有就是刚才说的视觉图片合图的优化。 -
唤起 换端率,主要受限于识别用户是否安装了优酷 APP,用户是否是误点击,或者不像打开观看,时机不对? 或者还有个原因就是系统启动太慢,有广告,提前退出了。 -
播放 播放率,主要受限于播放页的性能和前贴广告,如果前贴广告太长,用户等不及就退出了,没有产生有效的播放,再有就是网络状态 4g or wifi 等等。 -
次日留存 主要和产品的用户体验有关系
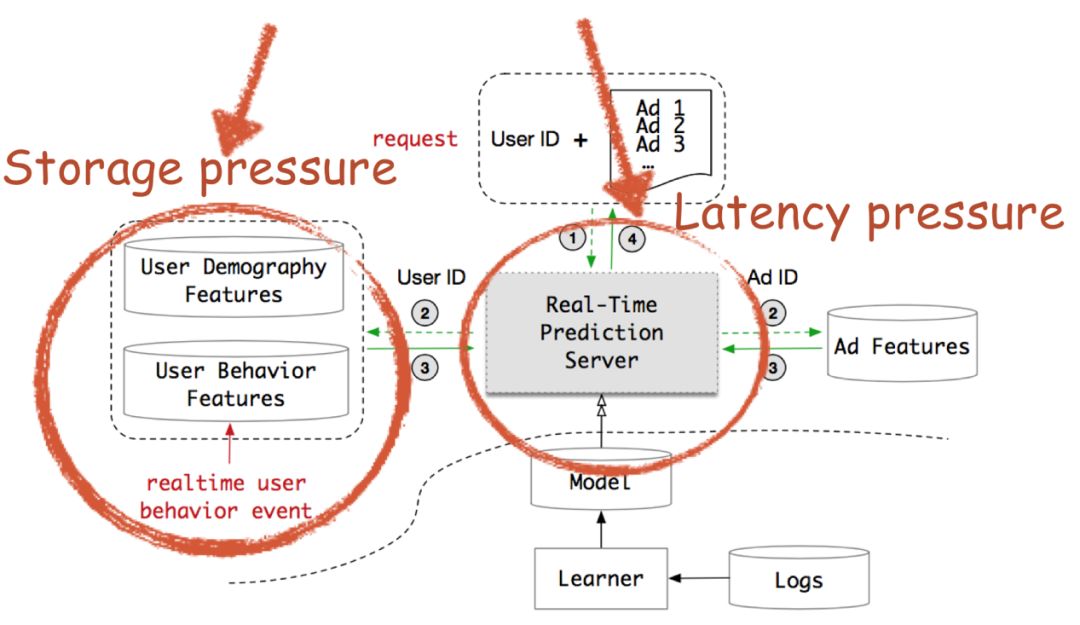
分享嘉宾:卞维杰 阿里妈妈
上图展示的是在线 RTP 引擎,当一个 request 过来的时候,会打分大概400个广告,我们根据 Ad ID 去 Ad Feature 这个索引库里面提取广告特征,根据 User ID 去提取 User 的 Demography 特征以及行为序列特征,然后送入模型进行打分,排序后将广告返回给用户。点击率预估与大部分工业应用一样需要一个实时的响应。在阿里这个电商平台里,点击率预估系统不仅面临高并发的请求,还需要在一个极短的时间内进行响应。我们的 DIN 和 DIEN 模型由于原始序列和 Target 均有显式交互,因而无法解耦计算,当行为序列长度为100时,DIN 和 DIEN 现有的复杂度逼近计算极限,由于计算资源的约束,在现有的模型下想把行为序列往1000扩展是不可能的。另外一方面,用户的行为特征是存储在线上服务引擎,阿里有亿级的用户,如果每个用户存储的行为序列特征由100扩展到1000,将带来极大的存储消耗和模型服务 IO 问题。因此我们面临着延迟约束和存储限制的系统瓶颈。
为了解决以上的系统瓶颈,必须从一个 high level 的角度进行思考,我们通过 Co-Design 算法&系统的突破,得出以下三个突破点:
计算解耦;
存储压缩;
增量复用。
受限于篇幅,更多内容欢迎下载2019 DataFunTalk 年度技术文章合集:广告篇。
------
获取方式:
1. 分享本文至朋友圈。
2. 扫码加管理员微信,索要电子书。
一个「在看」,一段时光!👇



