对于斯坦福 NLP 库,我们一定不会陌生,但是这一库主要基于 Java。
近日,Christopher Manning 所在的斯坦福 NLP 组开源了 Python 版的工具包——Stanza,让 Python 生态系统又增添了一员 NLP 大将。
我们都知道斯坦福 NLP 组的开源工具——这是一个包含了各种 NLP 工具的代码库。近日,他们公开了 Python 版本的工具,名为 Stanza。该库有 60 多种语言的模型,可进行命名实体识别等 NLP 任务。一经开源,便引起了社区的热议。李飞飞就在推特上点赞了这个项目。
项目地址:https://github.com/stanfordnlp/stanza
Stanza 包含了 60 多种语言模型,在 Universal Dependencies v2.5 数据集上进行了预训练。这些模型包括简体、繁体、古文中文,英语、法语、西班牙语、德语、日语、韩语、阿拉伯语等,甚至还有北萨米语等不太常见的语言。
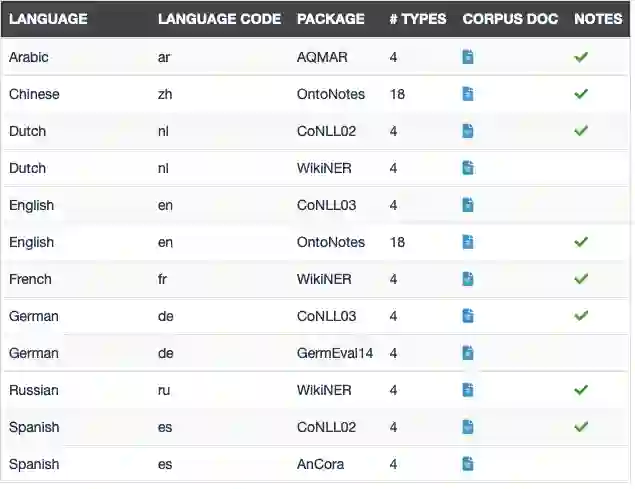
除了语言模型外,Stanza 还支持了数十种语言的命名实体识别模型。完整列表如下:
据 Stanza 的论文介绍,Stanza 涵盖了多个自然语言处理任务,如分词、词性标注、依存句法分析、命名实体识别等。此外,它还提供了 Pyhton 界面,用来和我们熟悉的 Stanford CoreNLP 库进行交互,从而扩展了已有的功能。
另外值得注意的是,Stanza 是完全基于神经网络 pipeline 的。研究者在 112 个数据集上进行了预训练,但使用的是同一个模型架构。他们发现,同样一个神经网络架构可以泛化得很好。网络在所有语言上的性能都很好。整个神经网络 pipeline 都是通过 PyTorch 实现的。
要运行首个 Stanza pipeline,只需要在 python 解释器 z 中进行操作:
>>> import stanza>>> stanza.download('en') # This downloads the English models for the neural pipeline# IMPORTANT: The above line prompts you before downloading, which doesn't work well in a Jupyter notebook.# To avoid a prompt when using notebooks, instead use: >>> stanza.download('en', force=True)>>> nlp = stanza.Pipeline() # This sets up a default neural pipeline in English>>> doc = nlp("Barack Obama was born in Hawaii. He was elected president in 2008.")>>> doc.sentences[0].print_dependencies()
而最后一条指令将输出当时输入字符串中第一个句子中的词(或是 Stanza 中表示的 Document),以及在该句的 Universal Dependencies parse(其「head」部分)中控制该词的索引,以及词之前的依赖关系。输出如下:
('Barack', '4', 'nsubj:pass')('Obama', '1', 'flat')('was', '4', 'aux:pass')('born', '0', 'root')('in', '6', 'case')('Hawaii', '4', 'obl')('.', '4', 'punct')
访问 Java Stanford Core NLP 软件
除了神经 Pipeline,该软件包还包括一个官方包,用于使用 Python 代码访问 Java Stanford CoreNLP 软件。
文档中会有全面的示例,展示如何通过 Stanza 使用 CoreNLP,并从中获取注释。
当前为所用的 Universal Dependencies 库 V2.5 提供模型,并为几种广泛使用的语言提供 NER 模型。
为了最大程度地提供速度方面的性能,必须针对成批的文档运行 Pipeline。每一次单在一个句子上运行一个 for 循环将 fei'c 非常慢,目前解决方法是将文档连在一起,每个文档见用空行(及两个换行符\n\n)进行分割。分词器将在句子中断时去识别空白行。
该库中所有神经模块都可以使用自己的数据进行训练。如 Tokenizer、multi-word token(MWT)扩展器、POS/特征标记器等。目前,不支持通过 pipeline 进行模型训练,因此需要克隆 git 存储库并从源代码中运行训练。
以下为训练神经 pipeline 的示例,可以看到项目中提供了各种 bash 脚本来简化 scripts 目录中的训练过程。训练模型运行以下指令:
bash scripts/run_${module}.sh ${corpus} ${other_args}
其中 ${module} 是 tokenize, mwt, pos, lemma,depparse 之一,是主体的全名; ${corpus} 是训练脚本所允许的其他参数。
例如,可以使用以下指令在 UD_English-EWT 语料库上训练时批量处理大小为 32,而终止率为 0.33:
bash scripts/run_tokenize.sh UD_English-EWT --batch_size 32 --dropout 0.33
注意对于 dependency parser, 还需要在训练/开发数据中为使用的 POS 标签类型指定 gold|predicted:
bash scripts/run_depparse.sh UD_English-EWT gold
如果使用了 predicted,训练后的标记器模型会首先在训练/开发数据上运行以便生成预测的标记。
默认情况下,模型文件将在训练期间保存到 save_models 目录(也可以使用 save_dir 参数进行更改)。
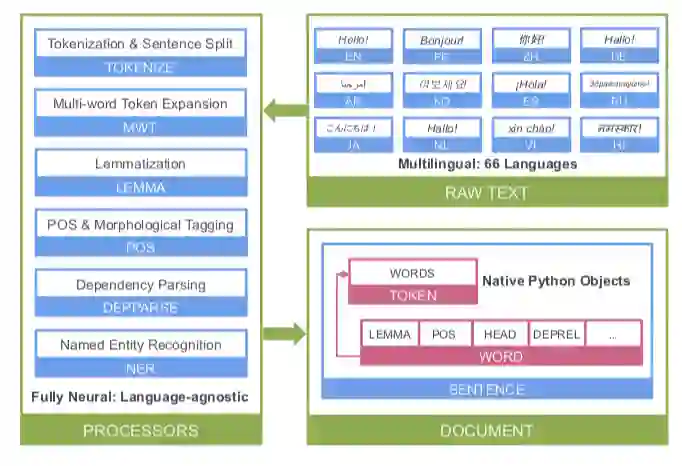
Stanza 的论文提供了整个代码库的架构。可以看到,它以原始文本为输入,能够直接输出结构化的结果。
Stanza 的神经网络部分架构。除了神经网络 pipeline 以外,Stanza 也有一个 Python 客户端界面,和 Java 版的 Stanford CoreNLP 进行交互。
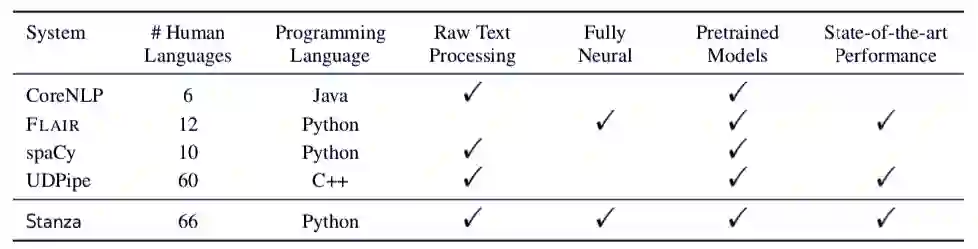
于此同时,论文还将 Stanza 和现有的 NLP 工具,如 spaCy 等进行了对比。可以看到,Stanza 是目前涵盖语言数量最多,达到 SOTA 且完全基于神经网络框架的库。
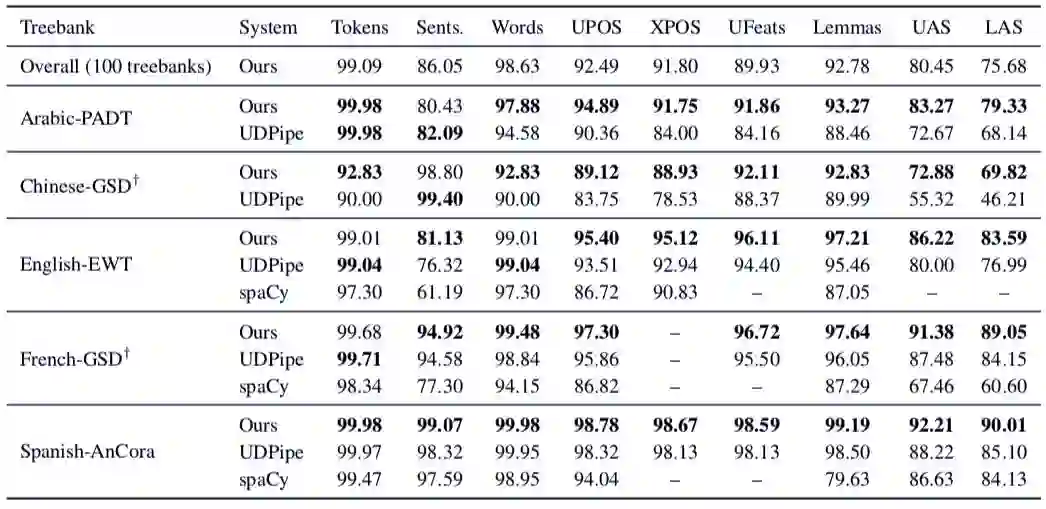
最后,研究者还将 Stanza 上 NLP 任务的性能和现有的基线进行对比,发现 Stanza 大部分情况下都超过了 SOTA。
和已有基线性能的对比。可以看到,Stanza 在多个语言多个任务中都实现了 SOTA。
参考链接:https://arxiv.org/abs/2003.07082
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com