英特尔发布第二代“至强”处理器,进一步领先AI推理市场

硅谷Live / 实地探访 / 热点探秘 / 深度探讨
本月3日,英特尔发布了第二代至强处理器(Xeon Processor)。
唔,虽然,还是在14纳米级别徘徊……但相较于第一代,第二代Xeon处理器新增了代号Cascade Lake-AP的铂金9200系列,最多可达56核心112线程。因此,第二代也被称为“Cascade Lake”。
更重要的是,这代处理器内置了机器学习加速(Intel DL Boost)功能,推理性能提升1.4倍,被认为是将嵌入式AI性能提升到新的水平。按照英特尔执行副总裁Navin Shenoy在发布会上的说法是:“这是我们在过去五年中在Xeon处理器系列中提供的最大一代改进。”

(图片来自网络,版权属于原作者)
虽然众多名词可能你看得有点晕,但不得不说,在这个静悄悄背后,硅谷洞察观察到的是,这一次,英特尔新的处理器可以说在AI领域下功夫了。甚至说,大有挑战GPU的架势啊!
先不管是否要真正叫板英伟达的GPU,但至少,英特尔在已有芯片市场格局下,拿下AI市场的决心是很明显了,尤其是主打AI推理的市场。
今天,硅谷洞察就来跟你分析分析,英特尔在人工智能芯片的举动与未来格局。
AI推理 VS AI训练
在分析英特尔在拿下AI芯片市场的决心之前,硅谷洞察给大家再次普及下人工智能芯片到底哪些玩家有机会。
我们都知道,使用深度神经网络分为两阶段。首先,第一阶段是“训练一个神经网络”,也就是我们常见的AI Training。第二阶段,是部署这个“神经网络”进行推理,使用之前训练过的参数,对未知的输入进行分类、识别和处理,也就是AI Inference。
举个简单的例子方便大家理解。
大家都知道,亚马逊的智能音箱Echo对吧。当你向Alexa提出一个问题时,比如“今天天气如何?”。Alexa听到问题,并决定告诉你今天天气的具体更新情况如何时,这就是基于推理的机器学习。而在回答问题之前,Alexa肯定被无数次输入不同的天气信息进行训练,从而才能遇到用户提问时答出来。
因此,如果以当中关键的硬件——芯片来看,针对训练(Training)和推理(Inference)功能所达到的不同目标,就有不同的需求。
简单说,针对人工智能训练(Training)阶段的话,需要很高的吞吐量,大量的算力、数据等,像英伟达的GPU就具有很高的计算精度,很强的并行、复杂运算的能力,但英伟达还是需要不断提高其内存带宽和数据吞吐量(Data throughput)。
而推理方面,通常在数据量来说,会比训练分批输入少得多,但需要的是尽可能快的响应和能耗效率优化。
按照英特尔预测,到 2020 年,推理周期和训练周期之间的比率将从深度学习初期的 1:1 提高至超过 5:1。也就是说,在人工智能领域,推理的比重将会越来越重要。英特尔称这一转变为 “大规模推理”。
由于推理将占用近 80% 的人工智能 (AI) 工作流程,因此,真正的人工智能就绪之路显然需要从选择适合的硬件架构开始。
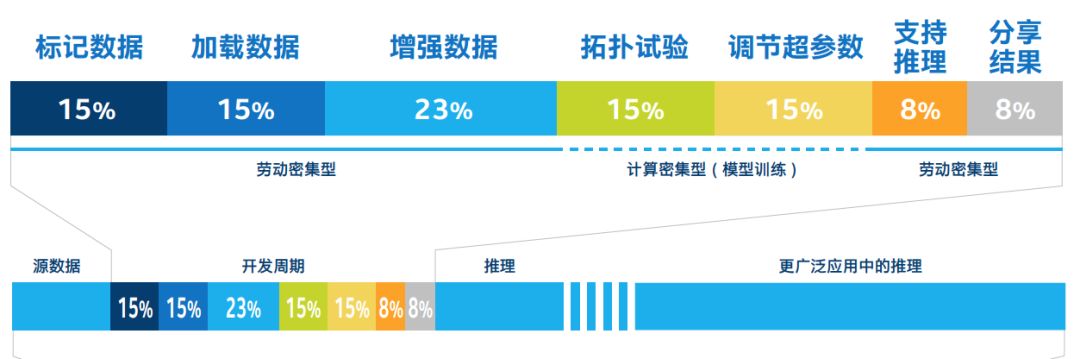
上图是一个典型的人工智能工作流程,可见推理在人工智能的工作后半程占的比重的远大于前面数据训练的。这也是为什么硅谷洞察认为,英特尔在AI推理方面大力下苦工的原因。当然,因为内存密集训练已经是Xeon处理器的优势了。
在发布会上,英特尔官方还透露了一个数据,Xeon处理器已经在当今市场上为80%至90%的AI推理助力了。
实用场景:已跟菲利浦、亚马逊等展开合作
在发布会现场,西门子医疗保健团队上场介绍了应用英特尔二代处理器的实际场景。没错,硬件被广泛应用的一个最大的核心步骤是跟工业领域合作。
我们都知道,心脏MRI(心血管磁共振成像)是医生用于识别心脏病的主要工具,仅在美国,每年心脏病就造成约1800万人死亡。但手动检查MRI图像需要很长时间,如果医生可以使用AI来帮助分类图像并识别潜在的问题,那么就可以更快地提供护理。
事实上,西门子用的就是英特尔新发布的二代处理器Cascade Lake。
(图片来自网络,版权属于原作者)
此外,英特尔在人工智能领域的另一大业界合作伙伴是另一家医学影像巨头——飞利浦。
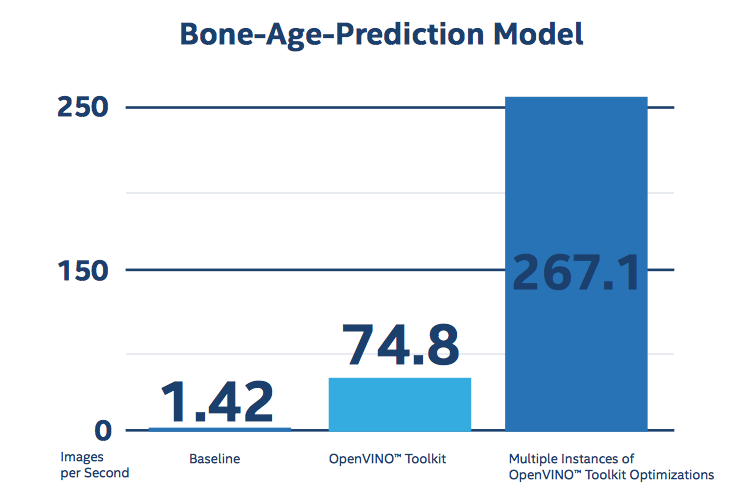
从英特尔人工智能官网可以发现,飞利浦用英特尔芯片处理的案例是:从人体骨骼影像识别骨质流失。当机器从人体骨骼(如手腕)的X射线图像中获取患者的性别后,推理模型能确定来自骨骼的预测年龄,以帮助识别导致的医疗状况——骨质流失。
假设来了一个年轻患者,只有35岁,但机器对这位患者预测的骨骼年龄有30岁,一旦小于实际年龄,则意味着患者可能患有营养不良、骨质流失的情况了。
用了AI之后,菲利浦的骨龄预测模型的速度提高了188倍,从每秒1.42幅图像的基线结果到每秒267.1幅图像。
(截图自英特尔人工智能官网intel.ai)
除了医疗领域之外,去年英特尔还与亚马逊合作推出了Deep Racer League。

(图片来自网络,版权属于原作者)
这是一个希望由开发人员参与的培训小型自动驾驶汽车挑战绕圈赛跑的联盟。开发人员可以在在线模拟器中训练、评估和调整强化学习(Reinforcement Learning)模型,再将他们的模型部署到AWS DeepRacer上获得真实的自主体验,最后创造最快速度的开发者可以有在联盟中赢得冠军的机会。
从处理器到软件包一应俱全
英特尔在上面这些跟工业界合作的案例中,需要指出的一点是:这些都是基于CPU完成的。而不是传统意义上人工智能领域常见的GPU或者乃至谷歌的TPU芯片(事实上,TPU属于定制芯片,尚未商业化)。
像飞利浦方面透露,为其各类医疗终端客户提供人工智能(AI),不应显着增加客户系统的成本,也不需要对现场部署的硬件进行修改。这也是最终能在医疗领域大规模使用AI的一个终极目的。
英特尔方面则表示,在医疗保健场景中,人工智能推理应用程序通常以小批量或流方式处理工作负载,这意味着它们不会有大批量的数据涌入,因此,CPU很适合低批量或流式的应用程序。
再举另一个对比的例子,你就知道了。
为什么在自动驾驶技术方面,大多依赖的芯片是NVIDIA的GPU而不是CPU,这是因为自动驾驶涉及到每秒钟需要处理的数据很庞杂,而且可以说是巨量。GPU确实可以加速深度学习,但也对机器、硬件有一定要求。
正如Forbes记者Maribel Lopez在采访英特尔人工智能产品集团(AIPG)首席技术官Amir Khosrowshahi后表示:GPU在AI领域受到关注,但许多公司也在使用CPU进行AI。
为什么?一个原因是:每个人都有CPU。随着云能承载越来越多的应用和数据,现有的CPU资源将会更多用于AI了。
硅谷洞察发现,除了本月发布新的二代至强处理器之外,英特尔还在软件工具方面帮助企业在边缘设备上部署人工智能。也就是说,从芯片处理器到整个软件工具包,英特尔无不透露着希望拿下AI推理的市场。
一个做法是,英特尔在软件方面已经跟多款主流人工智能开源框架合作,针对CPU的AI训练和AI推理功能,进行全面优化。
比如在TensorFlow上与 Google 合作,在 MXNet 上与 Apache 合作,也在 Caffe 上展开合作。就在今年3月,微软也宣布与英特尔合作,为Azure带来优化的深度学习框架。经过在TensorFlow、Caffe、Pytorch等上述主流框架的优化,Xeon处理器的训练性能得到不断提升。
事实上,亚马逊前面赛跑联盟采用的就是英特尔提供的OpenVINO工具包。这个工具包能使开发人员在云上构建人工智能模型(如TensorFlow,MXNet 和Caffe以及其他流行的框架),并将其部署到各种产品中,也有助于在英特尔的硬件上分配人工智能的工作量。
此外,英特尔新的二代处理器还专门通过嵌入式指令,提供深度学习加速(Deep Learning Boost)功能,为图像分类、语音识别、语言翻译和物体检测等深度学习应用案例提供更高效的推理加速。
也就是说,在不同的AI应用场景下,英特尔希望尽可能涵盖那些高频率的应用,比如图像分类、语音识别、翻译、物体检测都属于这类应用。
去年,英特尔已经跳出来说“could be better in inference of AI”(在AI推理领域能更好),随着谷歌已经推出定制芯片TPU,也促使了像亚马逊、微软等公司进行更多的定制芯片开发。可见,接下来的芯片开发、研发的一场混战,依然会围绕人工智能推理这块展开。
你认为英特尔接下来在AI推理领域还会有什么作为?你更看好谁?欢迎留言讨论。
更多精彩,欢迎点击阅读原文:
推荐阅读






